Recognition: unknown
CURaTE: Continual Unlearning in Real Time with Ensured Preservation of LLM Knowledge
Pith reviewed 2026-05-10 11:58 UTC · model grok-4.3
The pith
CURaTE lets LLMs forget targeted information on demand by training a separate embedding model to refuse matching prompts, without ever changing the original model's parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
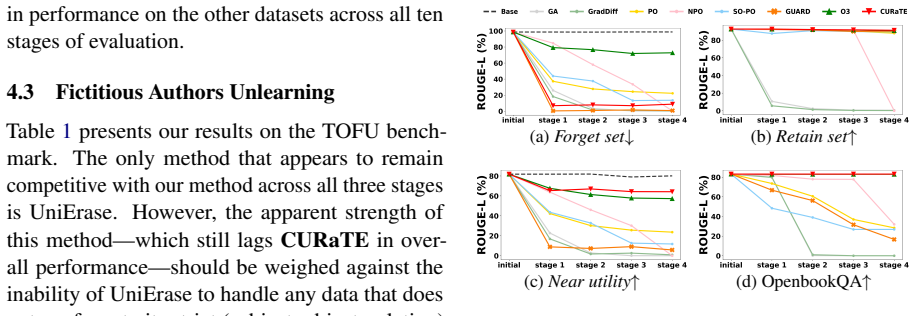
CURaTE trains a sentence embedding model on a forget-request dataset to form sharp decision boundaries, then uses similarity scoring on incoming prompts to decide whether to answer with the language model or return a refusal. Because the language model parameters are never modified, knowledge unrelated to the forget requests is preserved at near-perfect levels through any number of unlearning operations, and each request can be acted on in real time.
What carries the argument
A separately trained sentence embedding model that creates decision boundaries around forget requests and gates whether the unchanged language model generates a response or refuses.
If this is right
- Unlearning requests can be handled instantly upon arrival with no retraining of the language model.
- Performance on all retained knowledge remains near perfect across an unlimited sequence of updates.
- Forgetting effectiveness exceeds that of methods that edit model parameters directly.
- Continual unlearning becomes feasible for deployed models without cumulative loss of utility.
Where Pith is reading between the lines
- The separation of a lightweight detector from the main model could let existing LLM services add unlearning with little added latency.
- Similar detectors might be used for other runtime controls such as safety checks without retraining the base model.
- Over repeated requests this method could lower the long-term cost of meeting data-deletion regulations compared with periodic full retraining.
Load-bearing premise
Training a sentence embedding model on forget-request data will produce decision boundaries sharp enough to catch relevant prompts in real inputs without refusing too many unrelated ones.
What would settle it
A test set containing both direct variants of stored forget requests and clearly unrelated prompts, with measurement of whether the embedding model refuses the former while answering the latter at high accuracy.
Figures













read the original abstract
The inability to filter out in advance all potentially problematic data from the pre-training of large language models has given rise to the need for methods for unlearning specific pieces of knowledge after training. Existing techniques overlook the need for continuous and immediate action, causing them to suffer from degraded utility as updates accumulate and protracted exposure of sensitive information. To address these issues, we propose Continual Unlearning in Real Time with Ensured Preservation of LLM Knowledge (CURaTE). Our method begins by training a sentence embedding model on a dataset designed to enable the formation of sharp decision boundaries for determining whether a given input prompt corresponds to any stored forget requests. The similarity of a given input to the forget requests is then used to determine whether to answer or return a refusal response. We show that even with such a simple approach, not only does CURaTE achieve more effective forgetting than existing methods, but by avoiding modification of the language model parameters, it also maintains near perfect knowledge preservation over any number of updates and is the only method capable of continual unlearning in real-time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CURaTE for continual unlearning of specific knowledge from LLMs in real time. It trains a sentence embedding model on a forget-request dataset to form sharp decision boundaries, then computes similarity between an input prompt and stored forget requests to decide whether to answer or refuse. By avoiding any modification of the underlying LLM parameters, the method claims to deliver more effective forgetting than prior techniques while maintaining near-perfect knowledge preservation across arbitrary numbers of updates and enabling the only real-time continual unlearning approach.
Significance. If the empirical claims are substantiated, the work would be significant for machine unlearning: it directly targets the degradation of utility that accumulates in parameter-modifying methods and offers a path to immediate, ongoing removal of sensitive information without retraining or fine-tuning the base model. The parameter-free preservation aspect is a notable potential strength.
major comments (3)
- Abstract: the central claims of 'more effective forgetting than existing methods,' 'near perfect knowledge preservation over any number of updates,' and being 'the only method capable of continual unlearning in real-time' are asserted without any quantitative results, baselines, evaluation metrics, or experimental protocol, rendering the claims unevaluable from the provided text.
- Method description (sentence-embedding component): the approach depends on the embedding model producing sufficiently sharp decision boundaries to classify real-world prompts (including paraphrases and indirect queries) against stored forget requests. No details are supplied on dataset construction (positive/negative examples, augmentation strategy), similarity-threshold selection, or quantitative validation of boundary quality or false-refusal rates.
- Evaluation claims: the assertion of perfect preservation 'over any number of updates' and superior forgetting requires explicit multi-step continual-unlearning experiments that measure both leakage on forget cases and utility degradation on unrelated prompts; the current text provides none.
minor comments (2)
- Clarify whether the similarity threshold is a fixed hyperparameter, a learned quantity, or chosen via a specific procedure, and report its sensitivity.
- Ensure the full manuscript includes a dedicated experimental section with tables reporting forgetting efficacy, preservation metrics, runtime, and comparisons to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to better present our contributions. We address each major comment below and will revise the manuscript to strengthen the abstract, method details, and evaluation descriptions.
read point-by-point responses
-
Referee: Abstract: the central claims of 'more effective forgetting than existing methods,' 'near perfect knowledge preservation over any number of updates,' and being 'the only method capable of continual unlearning in real-time' are asserted without any quantitative results, baselines, evaluation metrics, or experimental protocol, rendering the claims unevaluable from the provided text.
Authors: We agree that the abstract would be strengthened by incorporating concrete quantitative summaries of our results. The full manuscript reports experimental outcomes supporting these claims, including comparisons to baselines on forgetting effectiveness and preservation metrics. We will revise the abstract to include key numerical findings (e.g., forgetting rates, preservation accuracy across update counts) and a brief reference to the evaluation protocol. revision: yes
-
Referee: Method description (sentence-embedding component): the approach depends on the embedding model producing sufficiently sharp decision boundaries to classify real-world prompts (including paraphrases and indirect queries) against stored forget requests. No details are supplied on dataset construction (positive/negative examples, augmentation strategy), similarity-threshold selection, or quantitative validation of boundary quality or false-refusal rates.
Authors: The manuscript outlines the training of the sentence embedding model on a forget-request dataset to create decision boundaries. To address the request for greater transparency, we will expand the method section with specifics on dataset construction (positive/negative example generation and augmentation), the similarity threshold selection procedure, and quantitative validation results for boundary sharpness, including false-refusal rates on paraphrased and indirect prompts. revision: yes
-
Referee: Evaluation claims: the assertion of perfect preservation 'over any number of updates' and superior forgetting requires explicit multi-step continual-unlearning experiments that measure both leakage on forget cases and utility degradation on unrelated prompts; the current text provides none.
Authors: We acknowledge that the evaluation section would benefit from more explicit multi-step experimental details. The manuscript includes continual unlearning experiments demonstrating effective forgetting and near-perfect preservation, but we will revise it to clearly describe the protocol, metrics for leakage on forget requests, utility on unrelated prompts, and results across increasing numbers of updates. revision: yes
Circularity Check
No significant circularity; claims rest on independent experimental validation
full rationale
The paper's derivation chain consists of (1) training a separate sentence embedding model on a forget-request dataset to produce decision boundaries, (2) using cosine similarity at inference to decide refusal vs. answer, and (3) evaluating forgetting efficacy and knowledge retention on held-out prompts. Knowledge preservation is a direct consequence of the design choice to leave LLM parameters untouched, not a fitted quantity or self-referential prediction. No equations are presented that reduce performance metrics to the training data by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of prior results occurs. The abstract and method description treat the embedding step as an external, trainable component whose generalization is tested rather than assumed tautologically. This is the normal case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- similarity threshold
axioms (1)
- domain assumption Sentence embedding models can be trained to form sharp decision boundaries separating forget-request prompts from normal prompts.
Reference graph
Works this paper leans on
-
[1]
Alphaedit: Null-space constrained knowledge editing for language models.ArXiv, abs/2410.02355. Chongyang Gao, Lixu Wang, Kaize Ding, Chenkai Weng, Xiao Wang, and Qi Zhu. 2025. On large lan- guage model continual unlearning. InThe Thirteenth International Conference on Learning Representa- tions. Raia Hadsell, Sumit Chopra, and Yann LeCun. 2006. Dimensiona...
-
[2]
Zhenhua Liu, Tong Zhu, Chuanyuan Tan, and Wen- liang Chen
Rethinking machine unlearning for large lan- guage models.Nature Machine Intelligence, pages 1–14. Zhenhua Liu, Tong Zhu, Chuanyuan Tan, and Wenliang Chen. 2024. Learning to refuse: Towards mitigating privacy risks in llms.ArXiv, abs/2407.10058. Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai- Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and...
-
[3]
Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, and Virginia Smith
Guardrail baselines for unlearning in llms. ArXiv, abs/2403.03329. Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. An Yang, Anfeng Li, Baoso...
-
[4]
Miao Yu, Liang Lin, Guibin Zhang, Xinfeng Li, Junfeng Fang, Ningyu Zhang, Kun Wang, and Yang Wang
Qwen3 technical report. Miao Yu, Liang Lin, Guibin Zhang, Xinfeng Li, Junfeng Fang, Ningyu Zhang, Kun Wang, and Yang Wang
-
[5]
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei
Unierase: Unlearning token as a universal era- sure primitive for language models.arXiv preprint arXiv:2505.15674. Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. 2024. Negative preference optimization: From catastrophic collapse to effective unlearning.arXiv preprint arXiv:2404.05868. A Discussion on the Cost of Retain Sets Table 5:Retain setsizes for met...
-
[6]
and test split of OpenbookQA (Mihaylov et al., 2018). C.2 Training Configuration We employed ‘multi-qa-mpnet-base-dot- v1’ (Reimers and Gurevych, 2019) as the base model for the unlearning sentence embedder U. This model has only around 109 million parameters so our training cost is orders of magnitude smaller than existing gradient-based approaches, whic...
-
[7]
and Qwen3-1.7B (Yang et al., 2025). N.1 Privacy Data Unlearning In Figure 14 we can see that for LLaMA-3.2- 1B, gradient-based methods exhibit the same phe- nomenon of overforgetting as in the case of the 7B model. O3 shows even worse performance on theforget set, indicating greater difficulty in for- getting the necessary information. Of all baselines, U...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.