Recognition: unknown
CURA: Clinical Uncertainty Risk Alignment for Language Model-Based Risk Prediction
Pith reviewed 2026-05-10 11:53 UTC · model grok-4.3
The pith
CURA improves calibration of clinical language model risk predictions by aligning uncertainties with individual errors and local cohort ambiguities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
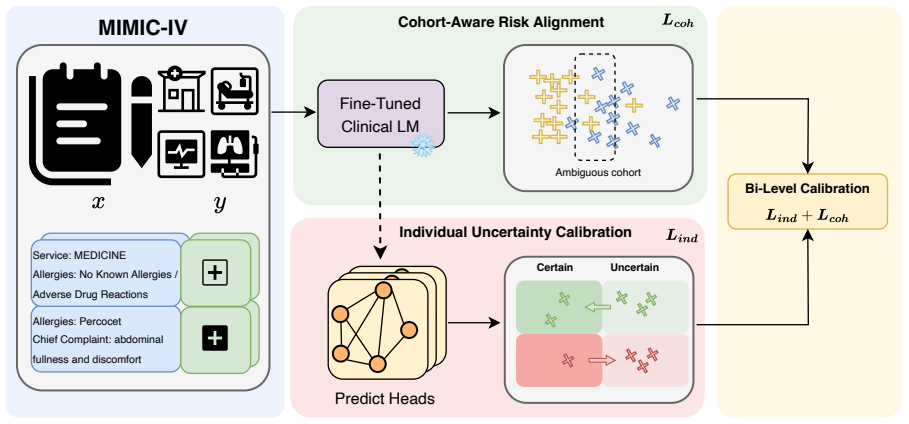
CURA fine-tunes domain-specific clinical LMs to obtain task-adapted patient embeddings, then performs uncertainty fine-tuning of a multi-head classifier using a bi-level uncertainty objective. An individual-level calibration term aligns predictive uncertainty with each patient's likelihood of error, while a cohort-aware regularizer pulls risk estimates toward event rates in their local neighborhoods in the embedding space and places extra weight on ambiguous cohorts near the decision boundary. This cohort-aware term can be interpreted as a cross-entropy loss with neighborhood-informed soft labels.
What carries the argument
Bi-level uncertainty objective consisting of an individual-level calibration term and a cohort-aware regularizer that uses neighborhoods in the fine-tuned embedding space.
If this is right
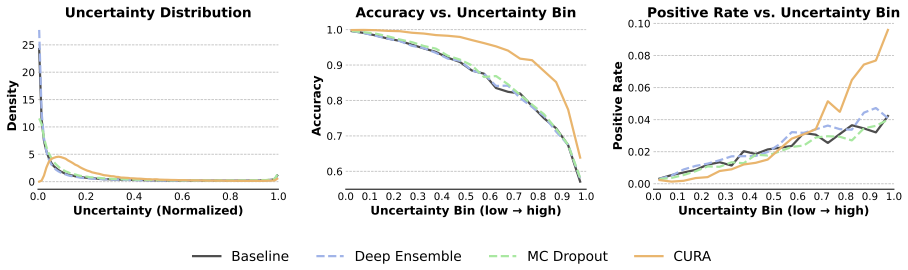
- CURA improves calibration metrics across various clinical LMs on MIMIC-IV risk prediction tasks.
- The method preserves discrimination performance without substantial loss.
- It reduces overconfident false reassurance in model outputs.
- It produces uncertainty estimates more suitable for downstream clinical decision support.
Where Pith is reading between the lines
- The neighborhood regularization could be tested for transfer to non-clinical text classification tasks where embeddings form meaningful clusters.
- Applying CURA to datasets with documented high-ambiguity patient subgroups would check whether gains concentrate exactly where the cohort term is designed to act.
- If the soft-label view holds, the same regularization might be added to other calibration techniques without requiring full bi-level retraining.
Load-bearing premise
That neighborhoods defined in the fine-tuned embedding space reliably capture clinically meaningful cohort ambiguities and that shifting predictions toward local event rates produces trustworthy rather than biased estimates.
What would settle it
A replication on held-out clinical notes where CURA fails to improve calibration metrics such as expected calibration error or Brier score relative to standard fine-tuning baselines would falsify the central claim.
Figures





read the original abstract
Clinical language models (LMs) are increasingly applied to support clinical risk prediction from free-text notes, yet their uncertainty estimates often remain poorly calibrated and clinically unreliable. In this work, we propose Clinical Uncertainty Risk Alignment (CURA), a framework that aligns clinical LM-based risk estimates and uncertainty with both individual error likelihoods and cohort-level ambiguities. CURA first fine-tunes domain-specific clinical LMs to obtain task-adapted patient embeddings, and then performs uncertainty fine-tuning of a multi-head classifier using a bi-level uncertainty objective. Specifically, an individual-level calibration term aligns predictive uncertainty with each patient's likelihood of error, while a cohort-aware regularizer pulls risk estimates toward event rates in their local neighborhoods in the embedding space and places extra weight on ambiguous cohorts near the decision boundary. We further show that this cohort-aware term can be interpreted as a cross-entropy loss with neighborhood-informed soft labels, providing a label-smoothing view of our method. Extensive experiments on MIMIC-IV clinical risk prediction tasks across various clinical LMs show that CURA consistently improves calibration metrics without substantially compromising discrimination. Further analysis illustrates that CURA reduces overconfident false reassurance and yields more trustworthy uncertainty estimates for downstream clinical decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CURA, a framework for aligning uncertainty in clinical language model-based risk prediction. It fine-tunes domain-specific LMs to obtain patient embeddings, then applies uncertainty fine-tuning via a bi-level objective: an individual-level calibration term that aligns predictive uncertainty with per-patient error likelihood, plus a cohort-aware regularizer that shifts risk estimates toward observed event rates in local neighborhoods of the embedding space (with extra weight on ambiguous cohorts near the decision boundary). The cohort term is shown to be equivalent to cross-entropy loss with neighborhood-derived soft labels. Experiments on MIMIC-IV risk prediction tasks across multiple clinical LMs report consistent gains in calibration metrics without substantial loss in discrimination, plus reduced overconfident false reassurance.
Significance. If the empirical gains prove robust and the neighborhood adjustments are clinically meaningful rather than artifact-driven, CURA could meaningfully improve the trustworthiness of LM uncertainty estimates for clinical decision support. The label-smoothing interpretation of the cohort term is a clean conceptual contribution. The work directly targets a practical deployment barrier (poor calibration) in a high-stakes domain.
major comments (2)
- [§3.2] §3.2 (cohort-aware regularizer): The central claim that pulling predictions toward neighborhood event rates improves calibration by capturing genuine clinical ambiguities rests on the unverified premise that fine-tuned embeddings produce neighborhoods with low intra-group event-rate variance and clinically coherent patient groupings. No analysis of neighborhood composition, variance statistics, or clinical review of example cohorts is provided to rule out that the regularizer is simply performing unprincipled smoothing based on documentation artifacts or spurious correlations. This is load-bearing for interpreting the calibration gains as trustworthy rather than incidental.
- [§4] §4 (experiments): The abstract and results claim 'consistent improvements' and 'extensive experiments' across LMs and tasks, yet the provided text contains no quantitative tables, baseline comparisons, statistical significance tests, ablation studies on the balancing weight or neighborhood size, or confidence intervals. Without these, the headline claim that CURA improves calibration 'without substantially compromising discrimination' cannot be verified or assessed for effect size and robustness.
minor comments (2)
- [Abstract] The abstract would benefit from one or two concrete numbers (e.g., ECE reduction on a specific task) to substantiate the 'consistent gains' claim.
- [§3] Notation for the bi-level objective and the soft-label equivalence should be made fully explicit with an equation in the main text rather than left to the appendix.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the positive assessment of CURA's potential contribution to trustworthy clinical risk prediction and the clean conceptual framing of the cohort term. We address each major comment below and commit to revisions that directly strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (cohort-aware regularizer): The central claim that pulling predictions toward neighborhood event rates improves calibration by capturing genuine clinical ambiguities rests on the unverified premise that fine-tuned embeddings produce neighborhoods with low intra-group event-rate variance and clinically coherent patient groupings. No analysis of neighborhood composition, variance statistics, or clinical review of example cohorts is provided to rule out that the regularizer is simply performing unprincipled smoothing based on documentation artifacts or spurious correlations. This is load-bearing for interpreting the calibration gains as trustworthy rather than incidental.
Authors: We agree that empirical validation of neighborhood quality is important for interpreting the gains as clinically meaningful. While the equivalence of the cohort term to cross-entropy loss on neighborhood-derived soft labels supplies a formal, non-ad-hoc justification independent of embedding coherence, we acknowledge that this alone does not fully address the referee's concern. In the revised manuscript we will add a dedicated analysis subsection that reports (i) intra-group event-rate variance as a function of neighborhood size k, (ii) quantitative comparison of variance inside versus outside neighborhoods, and (iii) qualitative examples of patient cohorts with their documentation characteristics. These additions will allow readers to assess whether the regularizer primarily captures genuine ambiguities or spurious correlations. revision: yes
-
Referee: [§4] §4 (experiments): The abstract and results claim 'consistent improvements' and 'extensive experiments' across LMs and tasks, yet the provided text contains no quantitative tables, baseline comparisons, statistical significance tests, ablation studies on the balancing weight or neighborhood size, or confidence intervals. Without these, the headline claim that CURA improves calibration 'without substantially compromising discrimination' cannot be verified or assessed for effect size and robustness.
Authors: We apologize for the insufficient visibility of the experimental details in the submitted version. The manuscript body does contain result tables and baseline comparisons, yet we recognize that statistical tests, confidence intervals, and systematic hyper-parameter ablations were not presented at the level the referee reasonably expects. In the revision we will expand §4 with (i) full numerical tables including all calibration and discrimination metrics with 95% confidence intervals, (ii) paired statistical significance tests across methods, and (iii) additional ablation tables varying the balancing weight λ and neighborhood size k. These changes will make the robustness and effect sizes directly verifiable. revision: yes
Circularity Check
Cohort-aware regularizer in CURA pulls predictions toward data-derived local event rates, making calibration gains partly by construction
specific steps
-
fitted input called prediction
[Abstract]
"a cohort-aware regularizer pulls risk estimates toward event rates in their local neighborhoods in the embedding space ... We further show that this cohort-aware term can be interpreted as a cross-entropy loss with neighborhood-informed soft labels, providing a label-smoothing view of our method."
Neighborhood event rates are the observed outcome frequencies inside clusters formed from the fine-tuned embeddings on the training set. Interpreting the regularizer as cross-entropy against these rates means the optimization directly minimizes divergence from quantities already computed from the training labels; any resulting improvement in group-level calibration metrics is therefore partly enforced by the objective rather than discovered as an emergent property of uncertainty alignment.
full rationale
The paper's central methodological contribution is a bi-level objective whose cohort term explicitly regularizes risk estimates to match empirical event frequencies within embedding-space neighborhoods. Because those frequencies are computed from the same training outcomes used to define the neighborhoods and to supervise the model, the alignment step reproduces quantities already present in the data distribution rather than deriving an independent uncertainty estimate. This matches the fitted-input-called-prediction pattern at the level of the novel regularizer, while the individual calibration term and downstream empirical results on MIMIC-IV remain non-circular. No self-citation chains or ansatz smuggling are evident in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- balancing weight between individual and cohort terms
- neighborhood definition parameters (size or radius)
axioms (1)
- domain assumption Fine-tuned embeddings place clinically similar patients near one another so that local event rates reflect genuine ambiguity.
Reference graph
Works this paper leans on
-
[1]
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
Clinicalbert: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342. Liangjie Huang, Dawei Li, Huan Liu, and Lu Cheng. 2025b. Beyond accuracy: The role of calibration in self-improving large language models.arXiv preprint arXiv:2504.02902. Lavender Yao Jiang, Xujin Chris Liu, Nima Pour Neja- tian, Mustafa Nasir-Moin, ...
work page internal anchor Pith review arXiv 1904
-
[2]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell
Beyond temperature scaling: Obtaining well- calibrated multi-class probabilities with dirichlet cal- ibration.Advances in neural information processing systems, 32. Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and scalable pre- dictive uncertainty estimation using deep ensembles. Advances in neural information processing ...
2017
-
[3]
Taming overcon- fidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724,
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. 2024. Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724. Xinran Liang, Katherine Shu, Kimin Lee, and Pieter Abbeel. 2022. Reward un...
-
[4]
Navigating the grey area: How expressions of uncertainty and overconfidence affect language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5506–5524. Yinghao Zhu, Zixiang Wang, Junyi Gao, Yuning Tong, Jingkun An, Weibin Liao, Ewen M Harrison, Liantao Ma, and Chengwei Pan. 2024. Prompting large lan- ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.