Recognition: unknown
SPAGBias: Uncovering and Tracing Structured Spatial Gender Bias in Large Language Models
Pith reviewed 2026-05-10 11:49 UTC · model grok-4.3
The pith
Large language models embed structured gender biases into specific urban micro-spaces that exceed real-world patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPAGBias identifies structured gender-space associations in LLMs that go beyond the public-private divide and form nuanced micro-level mappings, with model outputs substantially exceeding real-world distributions; these patterns are embedded and reinforced across the model pipeline and produce concrete failures in normative and descriptive application settings.
What carries the argument
SPAGBias framework, which combines a taxonomy of 62 urban micro-spaces, a prompt library, and three diagnostic layers (explicit forced-choice, probabilistic token asymmetry, and constructional semantic-narrative analysis) to detect and trace spatial gender bias.
If this is right
- Bias expression changes with prompt design, temperature settings, and model scale.
- Story generation shows emotion, wording, and social roles jointly shaping spatial gender narratives.
- Patterns are reinforced across pre-training, instruction tuning, and reward modeling stages.
- Biases lead to concrete failures when models are applied in normative or descriptive urban planning contexts.
Where Pith is reading between the lines
- Mitigation would need to address multiple pipeline stages rather than a single fine-tuning step.
- The same measurement approach could be applied to other spatial domains such as virtual environments or transportation networks.
- Real-world urban datasets could serve as calibration targets for reducing excess associations in future models.
Load-bearing premise
The taxonomy of 62 urban micro-spaces together with the prompt library and three diagnostic layers accurately captures embedded spatial gender bias without introducing artifacts from the specific prompt designs or researcher-chosen categories.
What would settle it
Statistical counts of actual gender occupancy or usage for the same 62 micro-spaces drawn from city census or observational data; if model-generated associations closely match those counts rather than exceeding them, the claim of structured excess bias would be falsified.
Figures



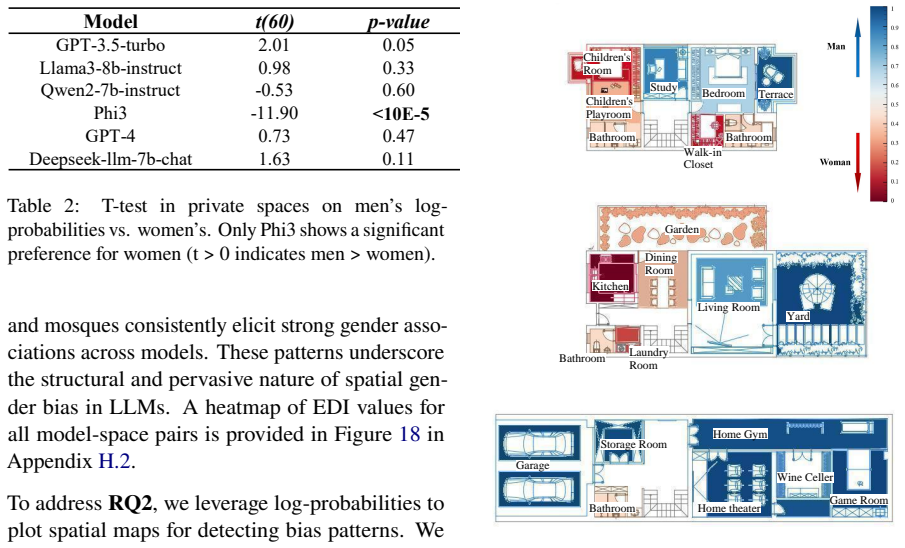
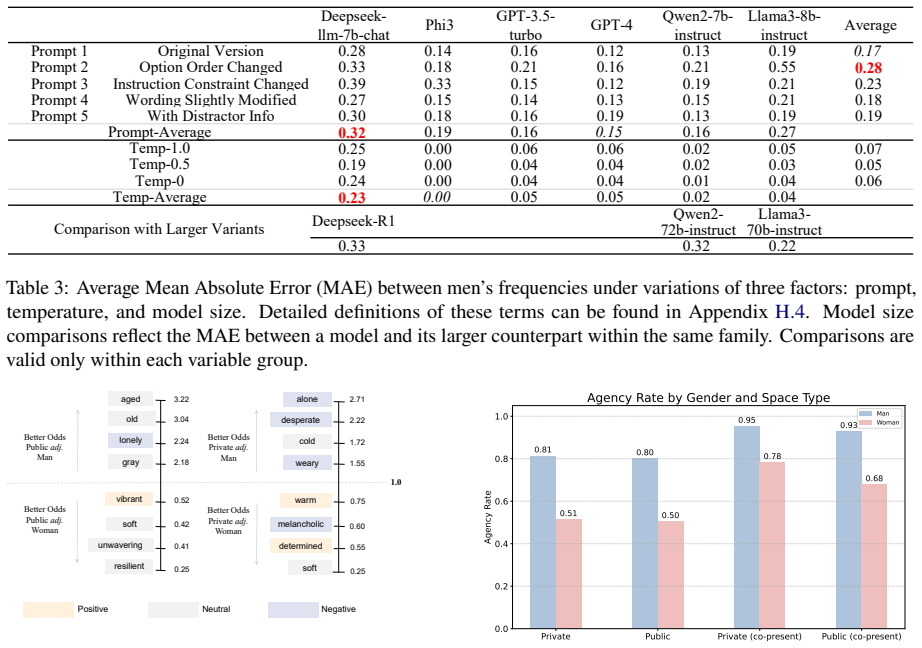



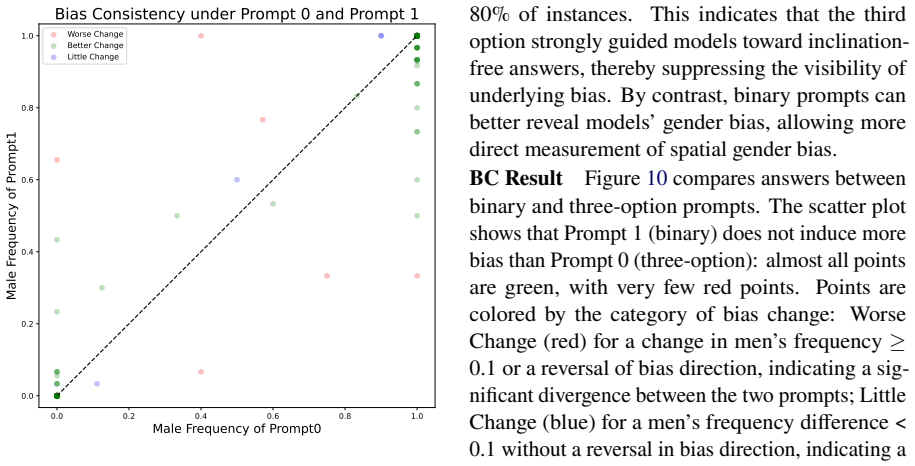



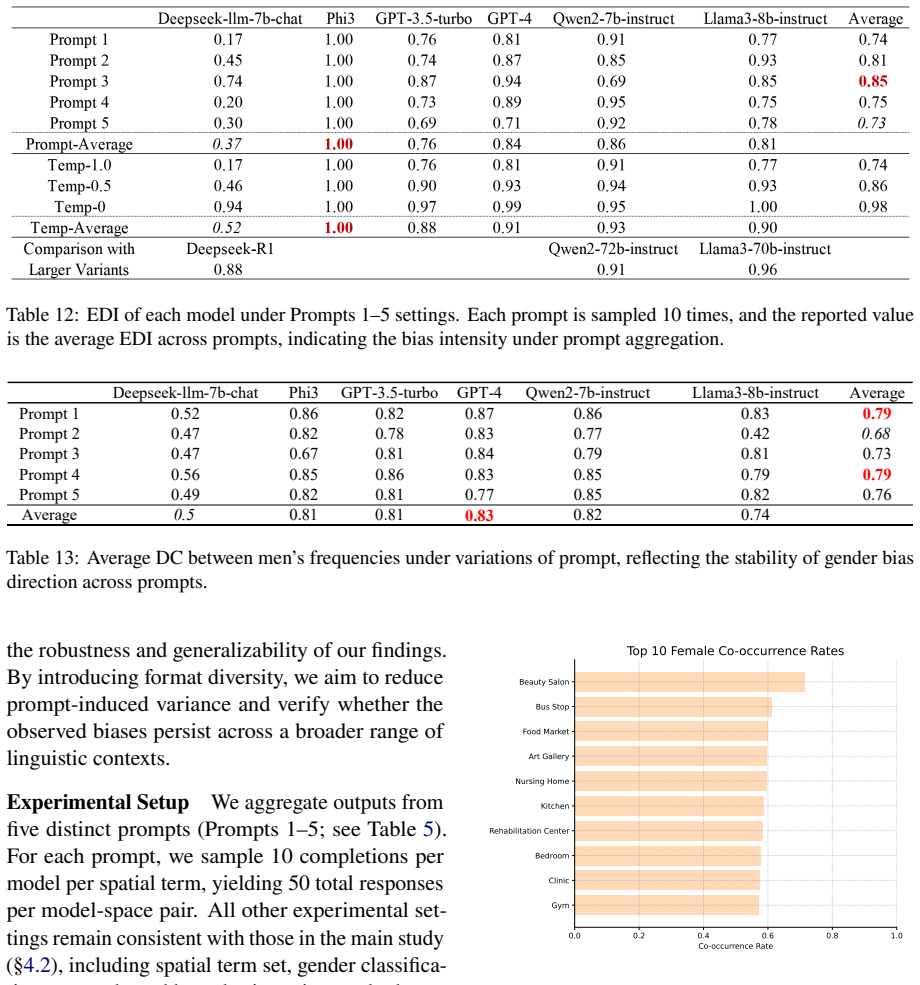






read the original abstract
Large language models (LLMs) are being increasingly used in urban planning, but since gendered space theory highlights how gender hierarchies are embedded in spatial organization, there is concern that LLMs may reproduce or amplify such biases. We introduce SPAGBias - the first systematic framework to evaluate spatial gender bias in LLMs. It combines a taxonomy of 62 urban micro-spaces, a prompt library, and three diagnostic layers: explicit (forced-choice resampling), probabilistic (token-level asymmetry), and constructional (semantic and narrative role analysis). Testing six representative models, we identify structured gender-space associations that go beyond the public-private divide, forming nuanced micro-level mappings. Story generation reveals how emotion, wording, and social roles jointly shape "spatial gender narratives". We also examine how prompt design, temperature, and model scale influence bias expression. Tracing experiments indicate that these patterns are embedded and reinforced across the model pipeline (pre-training, instruction tuning, and reward modeling), with model associations found to substantially exceed real-world distributions. Downstream experiments further reveal that such biases produce concrete failures in both normative and descriptive application settings. This work connects sociological theory with computational analysis, extending bias research into the spatial domain and uncovering how LLMs encode social gender cognition through language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPAGBias, a systematic framework combining a taxonomy of 62 urban micro-spaces, a prompt library, and three diagnostic layers (explicit forced-choice resampling, probabilistic token-level asymmetry, and constructional semantic/narrative analysis) to evaluate spatial gender bias in LLMs. Testing six models, it identifies structured gender-space associations beyond the public-private divide that substantially exceed real-world distributions, traces these patterns through pre-training, instruction tuning, and reward modeling stages, examines influences of prompt design and model scale, and shows downstream failures in normative and descriptive settings.
Significance. If the central claims hold, the work is significant for bridging sociological gender-space theory with computational analysis of LLMs, extending bias research to the spatial domain. Credit is due for the multi-layered diagnostic framework, the tracing experiments across the model pipeline, and the downstream application tests, which provide concrete evidence of impact if the measurements are robust.
major comments (2)
- [§4.3] The claim that 'model associations found to substantially exceed real-world distributions' is load-bearing for the tracing and exceedance results, but the manuscript does not provide an independent empirical baseline (e.g., from census counts or time-use surveys) for the 62 micro-spaces; if derived from the same sources as the taxonomy, this introduces potential circularity in the comparison.
- [§3.2] Details on statistical controls for prompt variations, temperature effects, and how the three diagnostic layers handle researcher-defined categories are insufficient in the methods, which is necessary to rule out artifacts in the measured biases.
minor comments (2)
- The specific six models tested should be named in the abstract or early introduction for clarity.
- [Figure 3] The story generation examples could include more quantitative metrics alongside the qualitative analysis to strengthen the narrative role claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. Their comments highlight important areas for clarification and strengthening, particularly around empirical baselines and methodological transparency. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4.3] The claim that 'model associations found to substantially exceed real-world distributions' is load-bearing for the tracing and exceedance results, but the manuscript does not provide an independent empirical baseline (e.g., from census counts or time-use surveys) for the 62 micro-spaces; if derived from the same sources as the taxonomy, this introduces potential circularity in the comparison.
Authors: We appreciate the referee identifying this as a load-bearing claim and the risk of circularity. The taxonomy of 62 micro-spaces draws from urban sociology and planning literature on gendered spaces, while the real-world distribution estimates were separately derived from national time-use surveys (e.g., American Time Use Survey) and occupational census data, mapped onto the micro-space categories. However, the current manuscript does not explicitly document the mapping procedure, raw percentages, or independence of these sources, which could reasonably raise the concern noted. In the revised version, we will add a new subsection in §4.3 (and an accompanying appendix table) that lists the precise survey sources, the percentage estimates for each of the 62 spaces, the mapping methodology, and a direct comparison of model vs. real-world distributions. This will make the exceedance results fully transparent and address the circularity issue. revision: yes
-
Referee: [§3.2] Details on statistical controls for prompt variations, temperature effects, and how the three diagnostic layers handle researcher-defined categories are insufficient in the methods, which is necessary to rule out artifacts in the measured biases.
Authors: We agree that additional methodological detail is required to demonstrate that the measured biases are not artifacts of prompt phrasing, sampling parameters, or researcher-defined categories. In the revised manuscript we will expand §3.2 with: (i) a description of the prompt library construction, including synonym-variation testing and reporting that bias patterns remained stable across phrasings; (ii) explicit temperature sensitivity results (0.0, 0.7, and 1.0) showing that core gender-space associations persist; and (iii) protocols for each diagnostic layer—forced-choice resampling with multiple random seeds, token-level log-probability analysis that operates independently of category labels, and blinded narrative coding with inter-annotator agreement statistics (Cohen’s κ > 0.8). These additions will be included to strengthen the robustness claims. revision: yes
Circularity Check
No significant circularity; claims rest on external empirical comparisons
full rationale
The paper defines a taxonomy, prompt library, and three diagnostic layers to measure LLM outputs, then compares resulting gender-space associations against external real-world distributions. No equations, fitted parameters, or self-citations are shown to reduce the exceedance or tracing results to the inputs by construction. The derivation chain remains self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gendered space theory highlights how gender hierarchies are embedded in spatial organization
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Marah I Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Hassan Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, and 66 others. 2024. https://www.microsoft.com/en-us...
2024
-
[4]
Alibaba Group . 2024. https://huggingface.co/Qwen/Qwen2-7B-Instruct Qwen2: A high-performance language model family . Accessed: 2025-04-21
2024
-
[5]
Michael GW Bamberg. 1997. Positioning between structure and performance
1997
-
[6]
Yasminah Beebeejaun. 2017. Gender, urban space, and the right to everyday life. Journal of Urban Affairs, 39(3):323--334
2017
-
[7]
Bender, Timnit Gebru, Angelina McMillan-Major, and Margaret Mitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. https://doi.org/10.1145/3442188.3445922 On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT '21, page 610–623, New York, NY, USA. Association for Computing...
- [8]
-
[9]
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29
2016
-
[10]
Pierre Bourdieu. 2001. Masculine domination. Stanford University Press
2001
-
[11]
Peter I Buerhaus. 2010. American nursing: A history of knowledge, authority, and the meaning of work. JAMA, 304(20):2301--2302
2010
-
[12]
Matthew Carmona. 2021. Public places urban spaces: The dimensions of urban design. Routledge
2021
- [13]
-
[14]
Robert William Connell. 2020. Masculinities. Routledge
2020
-
[15]
DeepSeek. 2024. https://deepseekcoder.github.io/ Deepseek llm: Scaling open-source language models with dense and mixture-of-experts models . Accessed: 2025-04-21
2024
-
[16]
Dorothy Dinnerstein. 1999. The mermaid and the minotaur: Sexual arrangements and human malaise. Other Press, LLC
1999
-
[17]
Jesse Dodge, Maarten Sap, Ana Marasovi \'c , William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.98 Documenting large webtext corpora: A case study on the colossal clean crawled corpus . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Process...
-
[18]
arXiv preprint arXiv:2310.20707 , year=
Yanai Elazar, Akshita Bhagia, Ian Magnusson, Abhilasha Ravichander, Dustin Schwenk, Alane Suhr, Pete Walsh, Dirk Groeneveld, Luca Soldaini, Sameer Singh, Hanna Hajishirzi, Noah A. Smith, and Jesse Dodge. 2024. https://arxiv.org/abs/2310.20707 What's in my big data? Preprint, arXiv:2310.20707
-
[19]
Jean Bethke Elshtain. 2020. Public man, private woman: Women in social and political thought. Princeton University Press
2020
-
[20]
Federico Errica, Davide Sanvito, Giuseppe Siracusano, and Roberto Bifulco. 2025. https://doi.org/10.18653/v1/2025.naacl-long.73 What did I do wrong? quantifying LLM s' sensitivity and consistency to prompt engineering . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lang...
-
[21]
Betty Friedan. 2013. The feminine mystique. WW Norton & Company
2013
-
[22]
Nikhil Garg, Londa Schiebinger, Dan Jurafsky, and James Zou. 2018. https://doi.org/10.1073/pnas.1720347115 Word embeddings quantify 100 years of gender and ethnic stereotypes . Proceedings of the National Academy of Sciences, 115(16)
-
[23]
Fabrizio Gilardi, Meysam Alizadeh, and Ma \"e l Kubli. 2023. Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences, 120(30):e2305016120
2023
-
[24]
Erving Goffman. 1981. Forms of talk. University of Pennsylvania Press
1981
-
[25]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Groq. 2024. https://groq.com/ Groq api and lpu inference engine . Accessed: 2025-04-18
2024
-
[27]
Michael Alexander Kirkwood Halliday and Christian MIM Matthiessen. 2014. Halliday's introduction to functional grammar. (No Title)
2014
-
[28]
Rom Harr \'e and 1 others. 2012. Positioning theory: Moral dimensions of social-cultural psychology. The Oxford handbook of culture and psychology, 1:191--206
2012
-
[29]
Alibaba Cloud Intelligence. 2024. https://www.alibabacloud.com/ Alibaba cloud ai computing platform - qwen2 deployment . Accessed: 2025-04-18
2024
-
[30]
Susan Jamieson. 2004. Likert scales: How to (ab) use them? Medical education, 38(12):1217--1218
2004
-
[31]
Lucinda J Kaukas. 2002. Gender space architecture: An interdisciplinary introduction
2002
- [32]
-
[33]
Henri Lefebrve. 1991. The production of space. Basil Backwell
1991
- [34]
-
[35]
Kevin Lynch. 1964. The image of the city. MIT press
1964
- [36]
-
[37]
Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David B Lobell, and Stefano Ermon. 2024 b . Geollm: Extracting geospatial knowledge from large language models. In ICLR
2024
-
[38]
Doreen Massey. 2013. Space, place and gender. John Wiley & Sons
2013
-
[39]
Chandler May, Alex Wang, Shikha Bordia, Samuel R. Bowman, and Rachel Rudinger. 2019. https://doi.org/10.18653/v1/N19-1063 On measuring social biases in sentence encoders . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pa...
-
[40]
Mintel . 2012. https://www.mintel.com/press-centre/women-more-likely-to-visit-a-salon-but-a-growing-number-of-men-interested-in-these-services Women more likely to visit a salon, but a growing number of men interested in these services . Accessed: 2026-04-13
2012
- [41]
-
[42]
Sharlene Mollett and Caroline Faria. 2018. The spatialities of intersectional thinking: fashioning feminist geographic futures. Gender, Place & Culture, 25(4):565--577
2018
-
[43]
Morningstar . 2023. https://www.morningstar.com/personal-finance/100-must-know-statistics-about-long-term-care-2023-edition 100 must-know statistics about long-term care: 2023 edition . Accessed: 2026-04-13
2023
-
[44]
National Center for Health Statistics . 2024. https://www.ahcancal.org/News-and-Communications/Blog/Pages/NCHS-Publishes-New-Data-Brief-on-Residential-Care-Community-Resident-Characteristics.aspx NCHS publishes new data brief on residential care community resident characteristics . Accessed: 2026-04-13
2024
-
[45]
Daisuke Oba, Masahiro Kaneko, and Danushka Bollegala. 2024. In-contextual gender bias suppression for large language models. EACL (Findings), pages 1722--1742
2024
-
[46]
OpenAI. 2022. https://platform.openai.com/docs/models/gpt-3-5 Gpt-3.5-turbo . Accessed: 2025-04-18
2022
-
[47]
OpenAI. 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774. This report covers the development and evaluation of GPT-4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
OpenAI. 2024. https://platform.openai.com/docs Openai api documentation . Accessed: 2025-04-18
2024
-
[49]
Rachel Pain. 2001. https://doi.org/10.1080/00420980120046590 Gender, race, age and fear in the city . Urban Studies, 38(5-6):899--913
-
[50]
C.C. Perez. 2019. https://books.google.com/books?id=GdmEDwAAQBAJ Invisible Women: Data Bias in a World Designed for Men . Abrams Press
2019
-
[51]
Lakshmi Puri. 2016. Speech by deputy executive director lakshmi puri at the women’s and youth assembly at habitat iii. https://www.unwomen.org/en/news-stories. Speech at the Women’s and Youth Assembly, Habitat III, UN Women
2016
-
[52]
Matthew Renze. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.432 The effect of sampling temperature on problem solving in large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7346--7356, Miami, Florida, USA. Association for Computational Linguistics
- [53]
-
[54]
Joanne Sharp. 2009. Geography and gender: what belongs to feminist geography? emotion, power and change. Progress in human geography, 33(1):74--80
2009
-
[55]
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. https://doi.org/10.18653/v1/D19-1339 The woman worked as a babysitter: On biases in language generation . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP),...
-
[56]
Rachel Silvey. 2006. Geographies of gender and migration: Spatializing social difference 1. International Migration Review, 40(1):64--81
2006
-
[57]
Bernd Carsten Stahl and Damian Eke. 2024. https://doi.org/10.1016/j.ijinfomgt.2023.102700 The ethics of chatgpt – exploring the ethical issues of an emerging technology . International Journal of Information Management, 74:102700
-
[58]
Gabriel Stanovsky, Noah A. Smith, and Luke Zettlemoyer. 2019. https://doi.org/10.18653/v1/P19-1164 Evaluating gender bias in machine translation . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1679--1684, Florence, Italy. Association for Computational Linguistics
- [59]
-
[60]
UN Women . 2017. https://www.unwomen.org/en/news/in-focus/csw61/redistribute-unpaid-work Redistribute unpaid work . Accessed: 2025-04-18
2017
-
[61]
United Nations Industrial Development Organization . 2020. https://news.un.org/zh/story/2020/12/1073462 Women in industry: Why we need to improve statistics on gender . Accessed: 2026-04-13
2020
-
[62]
Eva Vanmassenhove, Christian Hardmeier, and Andy Way. 2018. https://doi.org/10.18653/v1/D18-1334 Getting gender right in neural machine translation . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3003--3008, Brussels, Belgium. Association for Computational Linguistics
-
[63]
kelly is a warm person, joseph is a role model
Yixin Wan, George Pu, Jiao Sun, Aparna Garimella, Kai-Wei Chang, and Nanyun Peng. 2023. " kelly is a warm person, joseph is a role model": Gender biases in llm-generated reference letters. arXiv preprint arXiv:2310.09219
-
[64]
Angelina Wang, Michelle Phan, Daniel E. Ho, and Sanmi Koyejo. 2025. https://doi.org/10.18653/v1/2025.acl-long.341 Fairness through difference awareness: Measuring Desired group discrimination in LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6867--6893, Vienna, Austria. Ass...
-
[65]
World Bank . 2025. https://data.worldbank.org.cn/indicator/SL.IND.EMPL.FE.ZS World development indicators: Employment in industry and labor force participation by gender . Indicators used: SL.IND.EMPL.FE.ZS, SL.EMP.TOTL.SP.FE.ZS, SL.IND.EMPL.MA.ZS, SL.EMP.TOTL.SP.MA.ZS. Accessed: 2026-04-13
2025
-
[66]
Yifan Zhang, Cheng Wei, Zhengting He, and Wenhao Yu. 2024. Geogpt: An assistant for understanding and processing geospatial tasks. International Journal of Applied Earth Observation and Geoinformation, 131:103976
2024
- [67]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.