Recognition: unknown
DETR-ViP: Detection Transformer with Robust Discriminative Visual Prompts
Pith reviewed 2026-05-10 12:04 UTC · model grok-4.3
The pith
DETR-ViP adds global integration and distillation to visual prompts so they become class-distinguishable and raise open-vocabulary detection accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
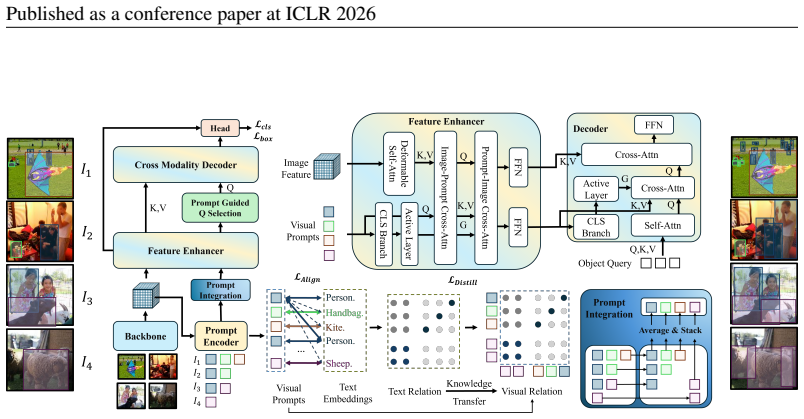
The central claim is that visual prompts derived from image features underperform because they lack global discriminability; DETR-ViP corrects this by performing global prompt integration and visual-textual prompt relation distillation on top of image-text contrastive learning, then applying selective fusion to keep detection stable and robust, which produces class-distinguishable prompts and substantially higher detection accuracy than prior visual-prompted detectors.
What carries the argument
The DETR-ViP architecture that performs global prompt integration to embed overall scene context into local visual prompts, followed by visual-textual prompt relation distillation to sharpen class boundaries and selective fusion to combine prompts stably.
If this is right
- Visual prompts acquire explicit global discriminability and therefore separate classes more reliably than before.
- Detection mAP rises substantially on COCO, LVIS, ODinW and Roboflow100 compared with prior visual-prompt baselines.
- Open-vocabulary detection becomes more practical because users can supply image examples for rare categories without text labels.
- Selective fusion keeps training stable, avoiding the overfitting or collapse that could otherwise accompany added prompt modules.
- Ablation results isolate the contribution of each added component to the final performance lift.
Where Pith is reading between the lines
- The same global-discriminability fix could be tried on prompt-based tasks outside detection, such as segmentation or retrieval.
- Hybrid visual-textual distillation may improve prompt quality in any multimodal model that mixes image and text cues.
- Real-time interactive systems could now let users draw or click example regions on the fly and expect consistent detection.
- The emphasis on global context suggests that purely local prompt extraction is a general limitation worth revisiting in other vision-language architectures.
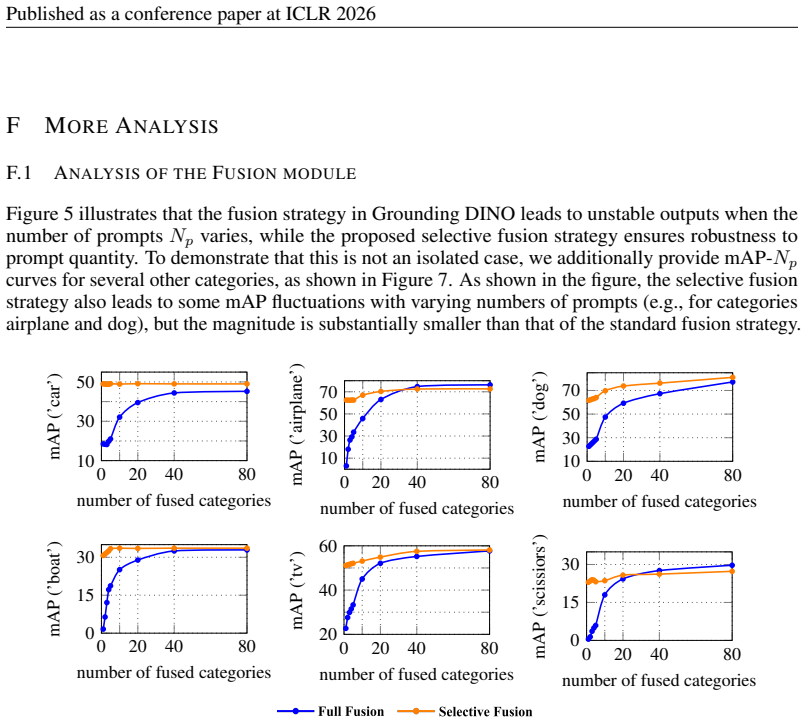
Load-bearing premise
The performance shortfall in visual-prompted detection is caused mainly by the absence of global discriminability in the prompts, and the added integration plus distillation steps close that gap without creating instability or overfitting.
What would settle it
Run the same baseline detector with and without the global integration and distillation modules; if the version with those modules shows no measurable gain in class separation in prompt feature space or in mAP on COCO validation, the central claim is false.
Figures









read the original abstract
Visual prompted object detection enables interactive and flexible definition of target categories, thereby facilitating open-vocabulary detection. Since visual prompts are derived directly from image features, they often outperform text prompts in recognizing rare categories. Nevertheless, research on visual prompted detection has been largely overlooked, and it is typically treated as a byproduct of training text prompted detectors, which hinders its development. To fully unlock the potential of visual-prompted detection, we investigate the reasons why its performance is suboptimal and reveal that the underlying issue lies in the absence of global discriminability in visual prompts. Motivated by these observations, we propose DETR-ViP, a robust object detection framework that yields class-distinguishable visual prompts. On top of basic image-text contrastive learning, DETR-ViP incorporates global prompt integration and visual-textual prompt relation distillation to learn more discriminative prompt representations. In addition, DETR-ViP employs a selective fusion strategy that ensures stable and robust detection. Extensive experiments on COCO, LVIS, ODinW, and Roboflow100 demonstrate that DETR-ViP achieves substantially higher performance in visual prompt detection compared to other state-of-the-art counterparts. A series of ablation studies and analyses further validate the effectiveness of the proposed improvements and shed light on the underlying reasons for the enhanced detection capability of visual prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DETR-ViP, a Detection Transformer variant for visual-prompted object detection. It diagnoses suboptimal visual-prompt performance as stemming from missing global discriminability in prompts derived from image features, then adds global prompt integration, visual-textual prompt relation distillation, and selective fusion atop image-text contrastive learning. Extensive experiments on COCO, LVIS, ODinW, and Roboflow100 plus ablations are reported to show substantially higher performance than prior state-of-the-art visual-prompted detectors.
Significance. If the performance gains and attribution to the proposed modules hold under scrutiny, the work would meaningfully advance open-vocabulary and interactive detection by making visual prompts more reliable, particularly for rare categories where they already hold an edge over text prompts. The multi-benchmark evaluation and ablation sections provide a reasonable empirical basis for the engineering claims.
major comments (2)
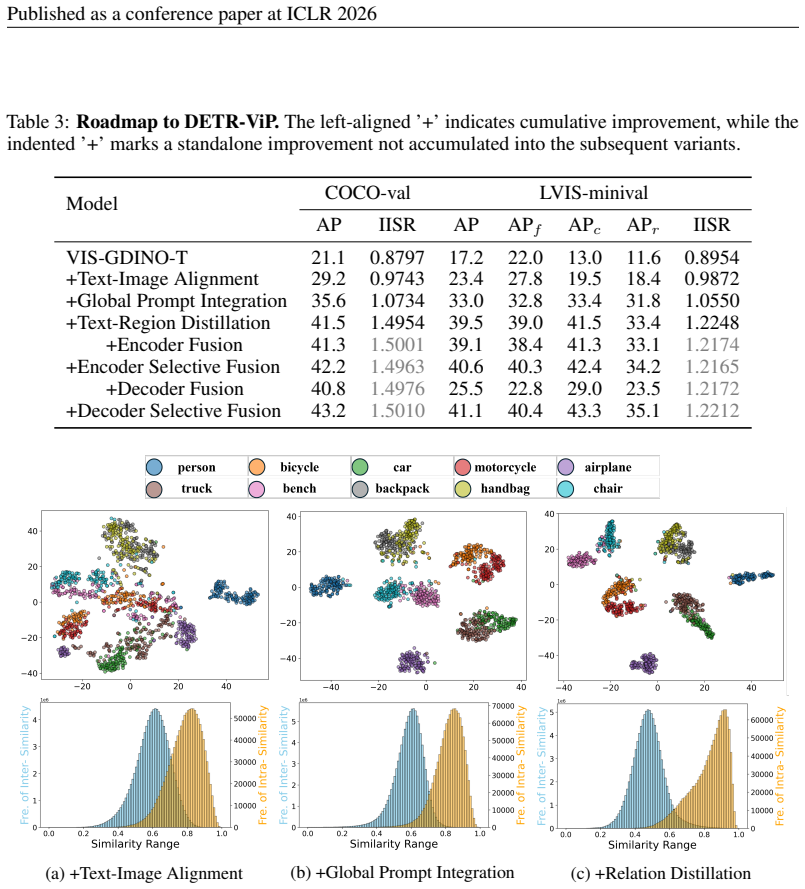
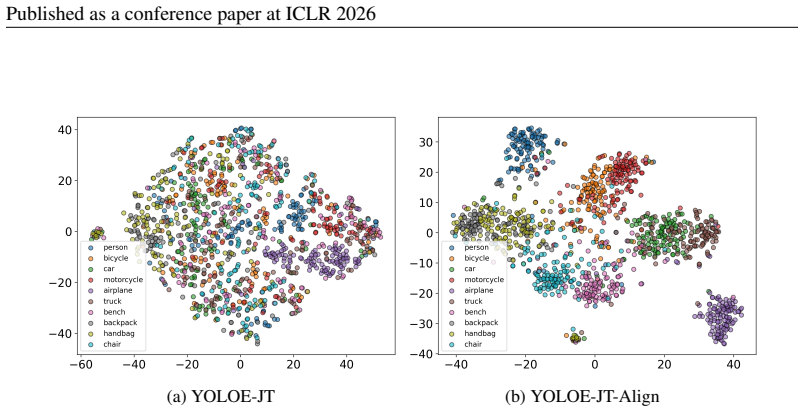
- [§3] §3 (Method): The central hypothesis that 'absence of global discriminability' is the root cause is stated as an observation, yet no direct supporting analysis (e.g., inter-class cosine distances or t-SNE of prompt embeddings before/after the proposed modules) is referenced in the motivation or results; without this, the attribution of gains specifically to global discriminability remains indirect.
- [§4] §4 (Experiments): The abstract and high-level claims assert 'substantially higher performance,' but the manuscript must include explicit mAP (or equivalent) deltas versus the strongest baselines on each dataset, together with training details (e.g., whether all methods use identical backbones, prompt sampling, and data splits) to allow verification that the reported gap is not due to implementation differences.
minor comments (2)
- [§3.3] Notation for the selective fusion module (Eq. X) should be defined more explicitly; the weighting mechanism is described qualitatively but the exact formula for the fusion gate is not immediately recoverable from the surrounding text.
- [§4.3] The ablation tables would benefit from an additional row or column reporting the performance of the base DETR with only contrastive learning (no proposed modules) to isolate the cumulative contribution of global integration + distillation + fusion.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation and constructive feedback. The comments highlight opportunities to strengthen the motivation and experimental reporting, which we address below with planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central hypothesis that 'absence of global discriminability' is the root cause is stated as an observation, yet no direct supporting analysis (e.g., inter-class cosine distances or t-SNE of prompt embeddings before/after the proposed modules) is referenced in the motivation or results; without this, the attribution of gains specifically to global discriminability remains indirect.
Authors: We acknowledge that the manuscript presents the lack of global discriminability primarily as an empirical observation motivating the design. To provide direct evidence, we will add in the revised §3 (or a new analysis subsection in §4) quantitative support including inter-class cosine similarity matrices and t-SNE visualizations of prompt embeddings before and after the global integration and distillation modules. These additions will make the attribution of performance gains to improved discriminability explicit and address the indirect nature of the current motivation. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and high-level claims assert 'substantially higher performance,' but the manuscript must include explicit mAP (or equivalent) deltas versus the strongest baselines on each dataset, together with training details (e.g., whether all methods use identical backbones, prompt sampling, and data splits) to allow verification that the reported gap is not due to implementation differences.
Authors: We agree that explicit deltas and implementation parity details are necessary for rigorous verification. In the revised manuscript, we will add a dedicated table in §4 summarizing mAP (or equivalent metric) improvements versus the strongest baselines on COCO, LVIS, ODinW, and Roboflow100. We will also expand the experimental protocol to explicitly state that all methods were evaluated under identical conditions, including the same backbone architecture, prompt sampling procedure, and data splits, with full hyperparameter details provided in the supplementary material. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical architecture for visual-prompted object detection. It identifies a hypothesized limitation (lack of global discriminability in visual prompts), introduces targeted components (global integration, relation distillation, selective fusion), and reports benchmark gains plus ablations on COCO/LVIS/ODinW/RoboFlow100. No derivation, first-principles prediction, or equation chain is claimed; performance is framed as an engineering outcome validated by experiments rather than reduced to fitted inputs or self-citations by construction. The central claims rest on external benchmark comparisons and internal ablations, which are independent of any circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Absence of global discriminability is the root cause of suboptimal visual-prompt performance
Reference graph
Works this paper leans on
-
[1]
Roboflow 100: A rich, multi-domain object detection benchmark,
Floriana Ciaglia, Francesco Saverio Zuppichini, Paul Guerrie, Mark McQuade, and Jacob Solawetz. Roboflow 100: A rich, multi-domain object detection benchmark.arXiv preprint arXiv:2211.13523,
-
[2]
Achal Dave, Piotr Dollár, Deva Ramanan, Alexander Kirillov, and Ross Girshick. Evaluating large-vocabulary object detectors: The devil is in the details.arXiv preprint arXiv:2102.01066,
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[4]
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921,
-
[5]
Learning deep representations by mutual information estimation and maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization.arXiv preprint arXiv:1808.06670,
-
[6]
T-rex: Counting by visual prompting.arXiv preprint arXiv:2311.13596, 2023
11 Published as a conference paper at ICLR 2026 Qing Jiang, Feng Li, Tianhe Ren, Shilong Liu, Zhaoyang Zeng, Kent Yu, and Lei Zhang. T-rex: Counting by visual prompting.arXiv preprint arXiv:2311.13596,
-
[7]
InAdvances in Neural Information Processing Systems, Vol
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre- training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10965–10975, 2022b. Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and Ja...
-
[8]
Towards end-to-end unified scene text detection and layout analysis
12 Published as a conference paper at ICLR 2026 Shangbang Long, Siyang Qin, Dmitry Panteleev, Alessandro Bissacco, Yasuhisa Fujii, and Michalis Raptis. Towards end-to-end unified scene text detection and layout analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1049–1059,
2026
-
[9]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review arXiv
-
[12]
Crowdhuman: A benchmark for detecting human in a crowd,
URL https: //api.semanticscholar.org/CorpusID:273233140. Shuai Shao, Zijian Zhao, Boxun Li, Tete Xiao, Gang Yu, Xiangyu Zhang, and Jian Sun. Crowdhuman: A benchmark for detecting human in a crowd.arXiv preprint arXiv:1805.00123,
-
[13]
Videoclip: Contrastive pre-training for zero-shot video-text understanding
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding.arXiv preprint arXiv:2109.14084,
-
[14]
Open-vocabulary detr with conditional matching
13 Published as a conference paper at ICLR 2026 Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Open-vocabulary detr with conditional matching. InEuropean conference on computer vision, pp. 106–122. Springer,
2026
-
[15]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022a. Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation a...
work page internal anchor Pith review arXiv
-
[16]
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Con- trastive learning of medical visual representations from paired images and text. InMachine learning for healthcare conference, pp. 2–25. PMLR, 2022b. Xiangyu Zhao, Yicheng Chen, Shilin Xu, Xiangtai Li, Xinjiang Wang, Yining Li, and Haian Huang. An open and comprehe...
-
[17]
Please act as a native English speaker and AI expert, and translate the following passage into English
14 Published as a conference paper at ICLR 2026 A STATEMENTS Use of Large Language Models (LLMs).During the preparation of this paper, we employed LLM-based tools to assist with writing and polishing. Specifically, we used the following instructions: • "Please act as a native English speaker and AI expert, and translate the following passage into English....
2026
-
[18]
a woman in a red shirt
We argue that this gap does not reflect the upper bound of visual prompts, but rather that their potential has not yet been fully explored. In this work, we aim to investigate the underlying reasons for the suboptimal performance of visual prompts and to fully exploit their potential, thereby advancing the development of prompt-based detection. 15 Publish...
2026
-
[19]
labels = labels.unique() To intuitively illustrate how global prompt integration works, we provide an example: if the prompt categories insample1are C1 ={0,2,3,5} and those insample2are C2 ={0,1,4,5} , then we 17 Published as a conference paper at ICLR 2026 can use a classifier covering the combined category set C={0,1,2,3,4,5} when performing classificat...
2026
-
[20]
blades to help board cut through water
For Visual Grounding (VG) datasets, the situation is typically more complicated. On the one hand, their annotations are generally of lower quality compared with object detection (OD) datasets such as COCO or Object365. On the other hand, the box descriptions in VG datasets are usually short phrases extracted from image captions, leading to highly variable...
2026
-
[21]
As shown in the figure, the selective fusion strategy also leads to some mAP fluctuations with varying numbers of prompts (e.g., for categories airplane and dog), but the magnitude is substantially smaller than that of the standard fusion strategy. 0 20 40 8010 30 50 number of fused categories mAP (’car’) 0 20 40 80 10 30 50 70 number of fused categories ...
2024
-
[22]
current image prompt, current image detect
Such instability with respect to the number of prompts not only introduces an additional hyperparameter, but also requires multiple runs under long text prompts, thereby increasing the testing time. With the selective fusion strategy, DETR-ViP integrates only the prompts corresponding to categories likely to appear in the input image, regardless of the nu...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.