Recognition: unknown
Development of an LLM-Based System for Automatic Code Generation from HEP Publications
Pith reviewed 2026-05-10 08:50 UTC · model grok-4.3
The pith
A two-stage LLM system extracts structured analysis selections from HEP papers and references then generates and validates executable code, achieving partial event-level matches on an ATLAS Higgs-to-four-leptons benchmark but limited by hallucination and stochasticity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our initial results show that recent open-weight models can recover many documented selection criteria from papers and references, and that in some runs they can generate event selections fully matching a baseline implementation at the event level.
Load-bearing premise
That iterative prompting and execution feedback can reliably overcome LLM stochasticity and hallucination to produce code that matches a human baseline without substantial human correction, an assumption the abstract itself flags as still problematic.
Figures
read the original abstract
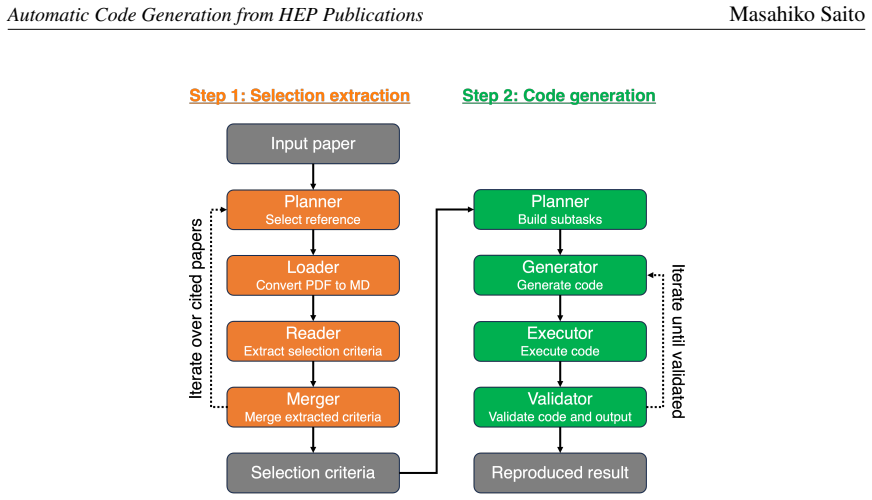
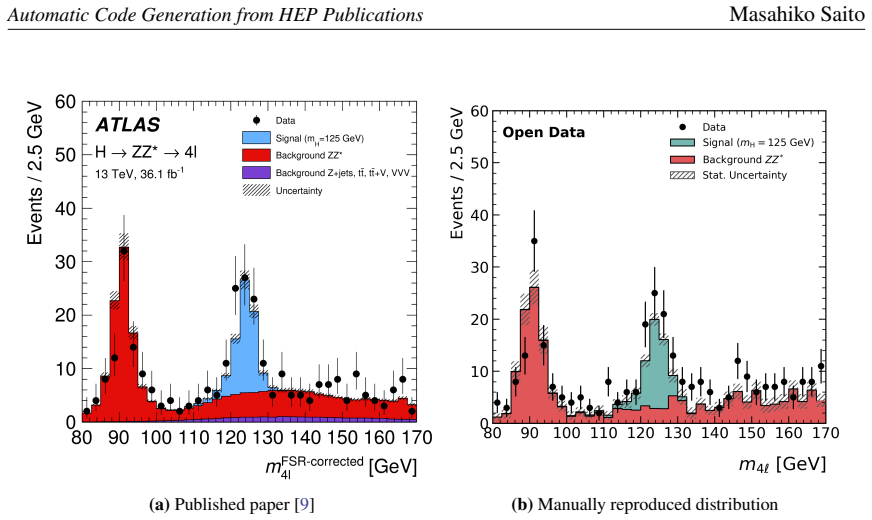
Ensuring the reproducibility of physics results is one of the crucial challenges in high-energy physics (HEP). In this study, we develop a proof-of-concept system that uses large language models (LLMs) to extract analysis procedures from HEP publications and generate executable analysis code for reproducing published results. Our method consists of two stages. In the first stage, open-weight LLMs extract event selection criteria, object definitions, and other relevant analysis information from a target paper and, when necessary, from its referenced publications, and then produce a structured selection list. In the second stage, the structured selection list is used to generate analysis code, which is then executed and validated iteratively. As a benchmark, we use the ATLAS $H \to ZZ^{*} \to 4\ell$ analysis based on proton-proton collision data recorded in 2015 and 2016 and released as ATLAS Open Data. This benchmark allows direct comparison between the generated results and the published analysis, as well as comparison with a manually developed baseline implementation. We separately evaluate selection extraction and code generation in order to clarify the current capabilities and limitations of open-weight LLMs for HEP analysis reproduction. Our initial results show that recent open-weight models can recover many documented selection criteria from papers and references, and that in some runs they can generate event selections fully matching a baseline implementation at the event level. At the same time, stochasticity, hallucination, and execution failure remain significant challenges. These results suggest that LLMs are already promising as human-in-the-loop tools for reproducibility support, although they are not yet reliable as fully autonomous HEP analysis agents. In this paper, we report the design of the prototype system and its initial performance evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a proof-of-concept two-stage system that employs open-weight LLMs to extract event selection criteria, object definitions, and related information from HEP publications (and referenced papers when needed) into a structured list, followed by iterative generation and validation of executable analysis code. The system is evaluated on the ATLAS H → ZZ* → 4ℓ analysis using 2015–2016 proton-proton open data, with direct comparison to published results and a manually developed baseline implementation. The authors separately assess selection extraction and code generation, reporting that recent models recover many documented criteria and that in some runs the generated code produces event selections fully matching the baseline at the event level, while acknowledging persistent issues with stochasticity, hallucination, and execution failures. The work concludes that LLMs are promising as human-in-the-loop reproducibility aids but not yet reliable as fully autonomous agents.
Significance. If the reported qualitative successes can be substantiated with quantitative metrics, this prototype would represent a concrete step toward reducing the manual effort required to reproduce complex HEP analyses from the literature. The use of a public benchmark with an explicit baseline implementation and the separation of extraction versus code-generation evaluation are appropriate design choices that facilitate assessment. The explicit acknowledgment of current limitations strengthens the manuscript by framing the system realistically as an assistive tool rather than a complete solution.
major comments (2)
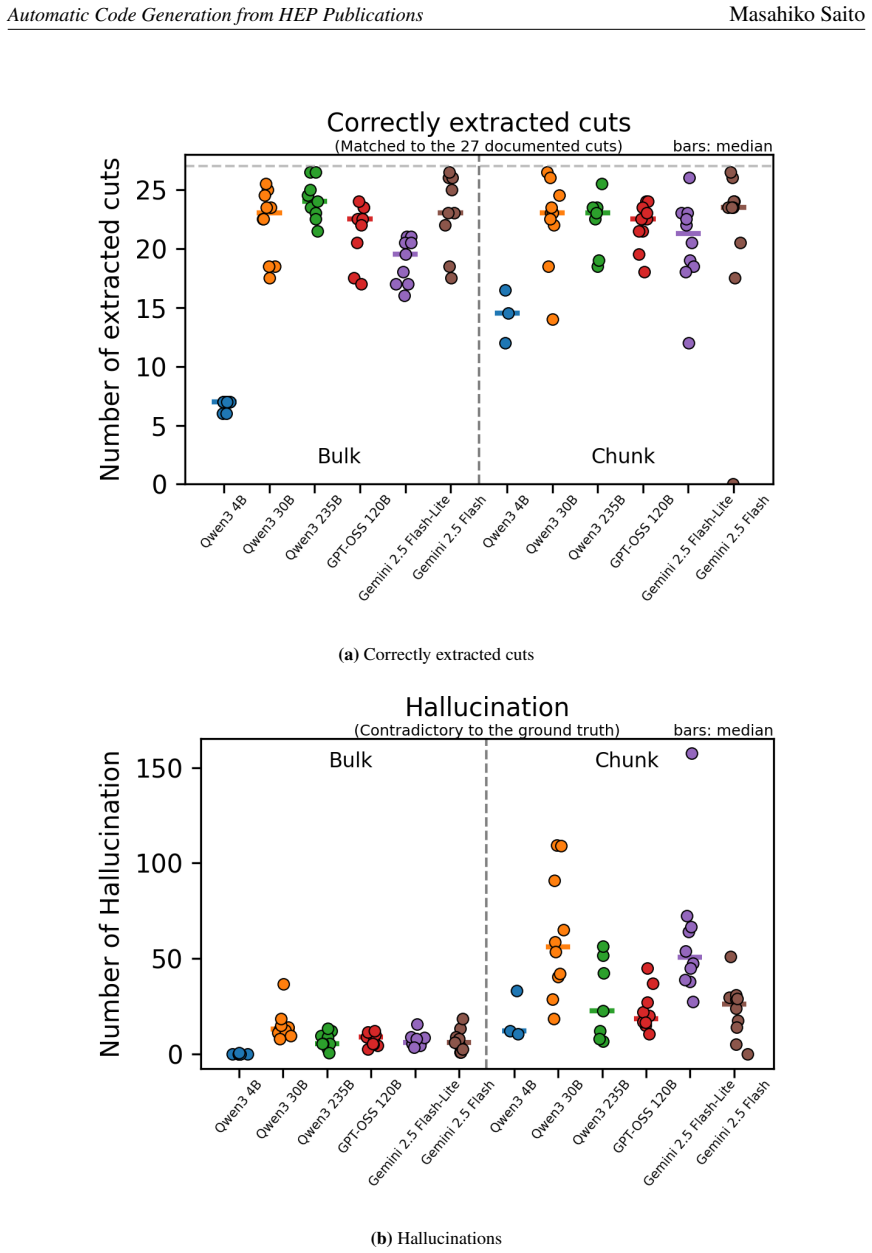
- [Abstract and Results section] The central claim in the abstract and results that LLMs 'in some runs' generate code whose output 'fully matching a baseline implementation at the event level' is load-bearing for the paper's assessment of current capabilities, yet no quantitative details are supplied: number of trials performed, success fraction, definition of event-level match (e.g., identical cutflow tables versus per-event agreement on the Open Data sample), or precision/recall for the extraction stage. Without these, it is impossible to determine whether the iterative prompting and execution feedback loop reliably mitigates the stochasticity and hallucination problems the authors themselves flag.
- [Method section (second stage)] The description of the second-stage iterative validation process (code generation, execution, and feedback) lacks concrete operational details such as the typical number of iterations required, the distribution of execution failure modes encountered, or the extent of human corrections needed per successful run. These metrics are necessary to evaluate whether the claimed partial successes can be achieved with acceptable human effort.
minor comments (2)
- [Abstract] The abstract would be strengthened by the inclusion of at least one concrete quantitative indicator (e.g., fraction of selection criteria recovered or success rate across runs) to give readers an immediate sense of scale.
- [Benchmark and Evaluation] Clarify the exact criteria used to declare a 'match' between generated and baseline code outputs, including any tolerance for floating-point differences or ordering of cuts.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the constructive major comments. We agree that additional quantitative and operational details will strengthen the manuscript and clarify the current capabilities and limitations of the system. We respond to each comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Results section] The central claim in the abstract and results that LLMs 'in some runs' generate code whose output 'fully matching a baseline implementation at the event level' is load-bearing for the paper's assessment of current capabilities, yet no quantitative details are supplied: number of trials performed, success fraction, definition of event-level match (e.g., identical cutflow tables versus per-event agreement on the Open Data sample), or precision/recall for the extraction stage. Without these, it is impossible to determine whether the iterative prompting and execution feedback loop reliably mitigates the stochasticity and hallucination problems the authors themselves flag.
Authors: We agree that the manuscript would benefit from more quantitative information to support the claims. The current presentation is qualitative because the work is a proof-of-concept demonstration of the two-stage system. To address the referee's concern, we will revise the abstract and results section to include quantitative details from our evaluation runs, such as the number of trials performed for code generation, the fraction of runs achieving full event-level match, a clear definition of what constitutes an event-level match, and precision/recall metrics for the selection extraction stage. This will provide a better basis for assessing the effectiveness of the iterative feedback loop in handling stochasticity and hallucination. revision: yes
-
Referee: [Method section (second stage)] The description of the second-stage iterative validation process (code generation, execution, and feedback) lacks concrete operational details such as the typical number of iterations required, the distribution of execution failure modes encountered, or the extent of human corrections needed per successful run. These metrics are necessary to evaluate whether the claimed partial successes can be achieved with acceptable human effort.
Authors: We concur that more concrete details on the iterative process are needed to assess the practicality of the system. In the revised manuscript, we will expand the method section to describe the operational aspects of the second stage, including the typical number of iterations in the validation loop, the main categories of execution failures observed, and the nature and extent of any human corrections applied in successful cases. These additions will help readers understand the human effort required for the partial successes reported. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Open-weight LLMs can extract complex, domain-specific selection criteria from scientific text and references with usable accuracy when prompted appropriately
Reference graph
Works this paper leans on
- [1]
-
[2]
E. Gendreau-Distler, J. Ho, D. Kim, L.T.L. Pottier, H. Wang and C. Yang,Automating High Energy Physics Data Analysis with LLM-Powered Agents, 2025. arXiv:2512.07785 [physics.data-an]
-
[3]
Ai agents can already autonomously perform experimental high energy physics,
E.A. Moreno, S. Bright-Thonney, A. Novak, D. Garcia and P. Harris,AI Agents Can Already Autonomously Perform Experimental High Energy Physics, 2026. arXiv:2603.20179 [hep-ex]
-
[4]
ATLAS Collaboration,Measurement of the Higgs boson mass in the𝐻→𝑍 𝑍∗ →4ℓand 𝐻→𝛾𝛾channels with √𝑠=13 TeV pp collisions using the ATLAS detector,Physics Letters B 784(2018) 345
2018
-
[5]
http://doi.org/10.7483/OPENDATA.ATLAS.AOQL.8TT3
ATLAS Collaboration,ATLAS DAOD_PHYSLITE format Run 2 2015 proton-proton collision data, 2024. http://doi.org/10.7483/OPENDATA.ATLAS.AOQL.8TT3
-
[6]
http://doi.org/10.7483/OPENDATA.ATLAS.4ZES.DJHA
ATLAS Collaboration,ATLAS DAOD_PHYSLITE format Run 2 2016 proton-proton collision data, 2024. http://doi.org/10.7483/OPENDATA.ATLAS.4ZES.DJHA
-
[7]
http://doi.org/10.7483/OPENDATA.ATLAS.Z2J9.709J
ATLAS Collaboration,ATLAS DAOD_PHYSLITE format MC simulation Higgs nominal samples, 2024. http://doi.org/10.7483/OPENDATA.ATLAS.Z2J9.709J
-
[8]
http://doi.org/10.7483/OPENDATA.ATLAS.K5SU.X65Y
ATLAS Collaboration,ATLAS DAOD_PHYSLITE format MC simulation electroweak boson nominal samples, 2024. http://doi.org/10.7483/OPENDATA.ATLAS.K5SU.X65Y
-
[9]
ATLAS Collaboration,Measurement of inclusive and differential cross sections in the 𝐻→𝑍 𝑍 ∗ →4ℓdecay channel in pp collisions at√𝑠= 13 TeV with the ATLAS detector, Journal of High Energy Physics2017(2017) 132
2017
-
[10]
“Marker.” https://github.com/datalab-to/marker
-
[11]
Chase,LangChain, Oct., 2022
H. Chase,LangChain, Oct., 2022. https://github.com/langchain-ai/langchain
2022
-
[12]
LangGraph
“LangGraph.” https://github.com/langchain-ai/langgraph
-
[13]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C.H. Yu et al.,Efficient Memory Management for Large Language Model Serving with PagedAttention, inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[14]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng et al.,Qwen3 Technical Report, 2025. arXiv:2505.09388 [cs.CL]. 9 Automatic Code Generation from HEP PublicationsMasahiko Saito
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI,gpt-oss-120b & gpt-oss-20b Model Card, 2025. arXiv:2508.10925 [cs.CL]
work page internal anchor Pith review arXiv 2025
-
[16]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon et al.,Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025. arXiv:2507.06261 [cs.CL]. A. Benchmark dataset Table3summarizestheeventselectioncriteriausedasthegroundtruthforStep1extractionand the inpu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Pre-selection 1.1 (*) Good Run List 1.2 (*) Trigger requirements 1.3 Number of primary vertices>0
-
[18]
Electron 2.1 Loose criteria 2.2𝐸 T >7GeV 2.3|𝜂|<2.47 2.4(𝑝 cone20 T /𝐸T)<0.15 2.5(𝐸 cone20 T /𝐸T)<0.20 2.6|𝑧 0 sin𝜃|<0.5mm 2.7|𝑑 0/𝜎(𝑑 0)|<5
-
[19]
Muon 3.1|𝜂|<2.7 3.1.1|𝜂|<0.1for Segmented-tagged muon and Calo-tagged muon 3.1.20.1<|𝜂|<2.5for Combined muons 3.1.32.4<|𝜂|<2.7for Muon-Spectrometer standalone muons 3.2𝑝 T >5GeV 3.2.1𝑝 T >15 GeVfor Calo-tagged muon 3.3𝑝 cone30 T /𝑝 T <0.15 3.4𝐸 cone20 T /𝑝 T <0.30 3.5|𝑧 0 sin𝜃|<0.5 mm 3.6|𝑑 0/𝜎(𝑑 0)|<3 3.7|𝑑 0|<1 mm
-
[20]
Quadruplet 4.1 Number of same-flavour opposite-sign lepton pairs≥2 4.250< 𝑚 12 <106 GeV 4.312< 𝑚 34 <115 GeV 4.4𝑝 T >20,15,10 GeVfor 1st, 2nd, 3rd leptons 4.5Δ𝑅(ℓ, ℓ)>0.1(0.2)for same-flavour (opposite-flavour) 4.6𝑚 ℓℓ >5 GeVfor same-flavour opposite-sign leptons 4.7 (*) 4 leptons vertex fit 4.8 Number of Combined muons≥3for4𝜇channel 4.9 (*)𝑍mass constrai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.