Recognition: unknown
Gating Enables Curvature: A Geometric Expressivity Gap in Attention
Pith reviewed 2026-05-10 11:06 UTC · model grok-4.3
The pith
Ungated attention is confined to flat statistical manifolds while multiplicative gating enables positively curved geometries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
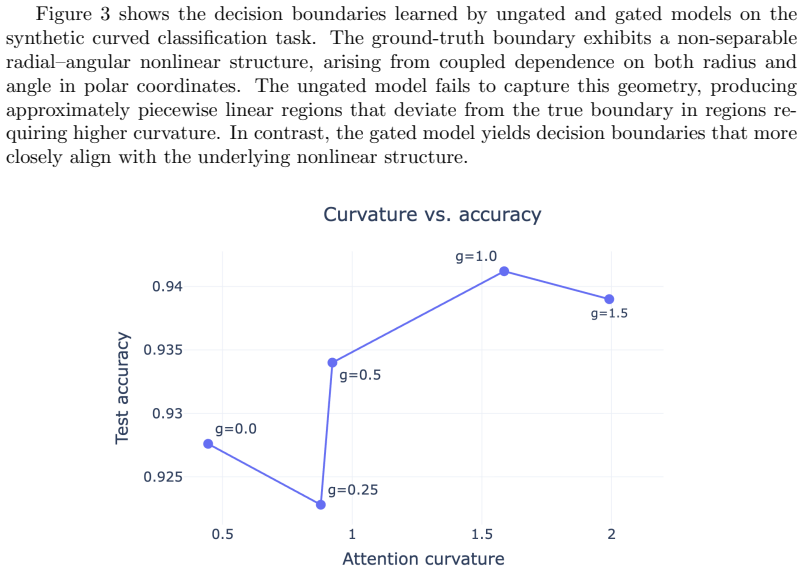
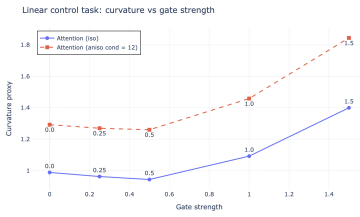
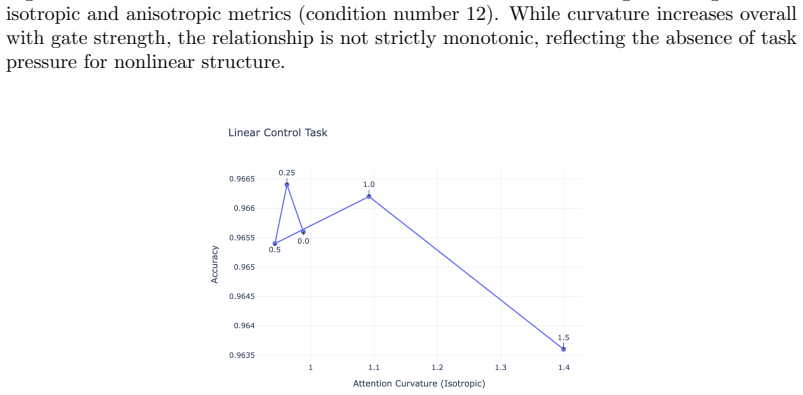
The ungated attention operator is restricted to intrinsically flat statistical manifolds due to its affine structure, while multiplicative gating enables non-flat geometries, including positively curved manifolds that are unattainable in the ungated setting. These results establish a geometric expressivity gap between ungated and gated attention. Empirically, gated models exhibit higher representation curvature and improved performance on tasks requiring nonlinear decision boundaries whereas they provide no consistent advantage on tasks with linear decision boundaries, and curvature accumulates under composition to produce a depth amplification effect.
What carries the argument
The Fisher-Rao geometry on the mean parameters of Gaussian distributions that model attention outputs, which is flat for ungated attention but can acquire positive curvature once multiplicative gating is introduced.
Load-bearing premise
Modeling attention outputs as mean parameters of Gaussian distributions and analyzing them with Fisher-Rao geometry accurately reflects the expressivity properties that matter for neural network task performance.
What would settle it
An empirical demonstration that an ungated attention model achieves measurable positive curvature in its representation manifold on a task where gated attention does not, or that gated attention fails to improve nonlinear-boundary performance despite the predicted curvature increase.
Figures






read the original abstract
Multiplicative gating is widely used in neural architectures and has recently been applied to attention layers to improve performance and training stability in large language models. Despite the success of gated attention, the mathematical implications of gated attention mechanisms remain poorly understood. We study attention through the geometry of its representations by modeling outputs as mean parameters of Gaussian distributions and analyzing the induced Fisher--Rao geometry. We show that ungated attention operator is restricted to intrinsically flat statistical manifolds due to its affine structure, while multiplicative gating enables non-flat geometries, including positively curved manifolds that are unattainable in the ungated setting. These results establish a geometric expressivity gap between ungated and gated attention. Empirically, we show that gated models exhibit higher representation curvature and improved performance on tasks requiring nonlinear decision boundaries whereas they provide no consistent advantage on tasks with linear decision boundaries. Furthermore, we identify a structured regime in which curvature accumulates under composition, yielding a systematic depth amplification effect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ungated attention is restricted to intrinsically flat statistical manifolds due to its affine structure, while multiplicative gating enables non-flat geometries including positive curvature unattainable in the ungated case. This is shown by modeling attention outputs as mean parameters of Gaussian distributions and analyzing the induced Fisher-Rao geometry, establishing a geometric expressivity gap. Empirically, gated models exhibit higher representation curvature, improved performance on nonlinear decision boundary tasks, no consistent advantage on linear ones, and a depth amplification effect where curvature accumulates under composition.
Significance. If the geometric distinction and its link to task performance hold, the work offers a principled explanation for the benefits of gating in attention layers, connecting affine vs. multiplicative operations to manifold curvature and expressivity. This could inform architecture choices in large models and highlight depth-dependent effects. The empirical correlations provide supporting evidence, though the proxy role of the chosen statistical geometry for actual neural expressivity remains a key point of validation.
major comments (2)
- [Abstract and §3] The central modeling decision to represent attention outputs as mean parameters of fixed-covariance Gaussians and to interpret the induced Fisher-Rao geometry as capturing task-relevant expressivity (abstract and §3) requires stronger justification. The ambient Fisher-Rao metric on this family is Euclidean, so any claimed curvature arises only from the nonlinear embedding; it is unclear why this auxiliary construction, rather than the operator's action on the original feature space or optimization dynamics, governs approximation power or decision-boundary nonlinearity.
- [Empirical evaluation section] The empirical claims that gated models exhibit higher curvature and improved performance specifically on nonlinear tasks (and no advantage on linear ones) rest on correlations without sufficient controls to rule out confounding effects of gating (e.g., altered gradient flow or capacity unrelated to curvature). The depth amplification result similarly needs explicit ablation to confirm accumulation is geometric rather than architectural.
minor comments (2)
- [§2] Notation for the attention operator and the gating function should be introduced with explicit equations early in the theoretical section to avoid ambiguity when transitioning between affine and multiplicative cases.
- [Figures in empirical section] Figure captions for curvature visualizations should include the exact task, model depth, and metric computation details to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing our response and indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] The central modeling decision to represent attention outputs as mean parameters of fixed-covariance Gaussians and to interpret the induced Fisher-Rao geometry as capturing task-relevant expressivity (abstract and §3) requires stronger justification. The ambient Fisher-Rao metric on this family is Euclidean, so any claimed curvature arises only from the nonlinear embedding; it is unclear why this auxiliary construction, rather than the operator's action on the original feature space or optimization dynamics, governs approximation power or decision-boundary nonlinearity.
Authors: We appreciate the referee's call for stronger justification of the modeling choice. The construction equips the space of attention outputs with the Fisher-Rao metric by treating them as mean parameters of fixed-covariance Gaussians; the ambient metric is indeed Euclidean in these parameters, and curvature is induced by the nonlinear embedding realized by the attention map. This choice is motivated because the geometry of the image manifold directly constrains the nonlinearity of functions that can be realized when a downstream linear layer operates on the representations. An affine (ungated) map necessarily embeds into a flat affine subspace, while multiplicative gating permits non-flat, positively curved images. We view this as a principled proxy for expressivity relevant to decision-boundary complexity, complementary to direct operator analysis or dynamics. We will expand the motivation and discussion of this proxy in the abstract and Section 3, including additional remarks on its relation to approximation power. revision: partial
-
Referee: [Empirical evaluation section] The empirical claims that gated models exhibit higher curvature and improved performance specifically on nonlinear tasks (and no advantage on linear ones) rest on correlations without sufficient controls to rule out confounding effects of gating (e.g., altered gradient flow or capacity unrelated to curvature). The depth amplification result similarly needs explicit ablation to confirm accumulation is geometric rather than architectural.
Authors: We agree that the empirical claims would be strengthened by explicit controls and ablations. We will revise the evaluation section to include capacity-matched baselines (e.g., by adjusting hidden dimensions or adding parameters to ungated models) and training-dynamic controls (e.g., gradient clipping or normalization adjustments to isolate flow differences). For the depth amplification effect, we will add ablations that vary depth while holding gating and other architectural elements fixed, reporting curvature metrics at each layer to demonstrate accumulation attributable to the geometric mechanism rather than generic depth effects. These additions will better isolate the contribution of the curvature gap. revision: yes
Circularity Check
No significant circularity in geometric analysis of attention
full rationale
The paper explicitly adopts the modeling choice of representing attention outputs as mean parameters of fixed-covariance Gaussians and then applies the standard Fisher-Rao metric on that parameter space. From this setup it derives that the affine algebraic structure of the ungated operator maps into flat submanifolds while the multiplicative structure of gating produces nonlinear embeddings that can realize positive curvature. Both conclusions follow directly from the definitions of affine maps (which preserve flatness) and the known geometry of the chosen statistical manifold; no parameter is fitted to data and then relabeled as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and no quantity is defined in terms of itself. The derivation therefore remains self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attention outputs can be modeled as mean parameters of Gaussian distributions
- domain assumption Fisher-Rao geometry is the relevant metric for assessing statistical manifold curvature in neural representations
Reference graph
Works this paper leans on
-
[1]
Amari.Differential-Geometrical Methods in Statistics
S.-i. Amari.Differential-Geometrical Methods in Statistics. Springer, 1985
1985
-
[2]
Amari.Information Geometry and Its Applications
S.-i. Amari.Information Geometry and Its Applications. Springer, 2016
2016
-
[3]
Amari, R
S.-i. Amari, R. Karakida, and M. Oizumi. Fisher information and natural gradient learning in random deep networks. In K. Chaudhuri and M. Sugiyama, editors,Pro- ceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 694–702. PMLR, 16–18 Apr 2019
2019
-
[4]
Amari and H
S.-i. Amari and H. Nagaoka.Methods of Information Geometry. American Mathemat- ical Society, 2000
2000
-
[5]
K. Cho, B. van Merri¨ enboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation.Proceedings of EMNLP, 2014
2014
-
[6]
Danihelka, G
I. Danihelka, G. Wayne, B. Uria, N. Kalchbrenner, and A. Graves. Associative long short-term memory.Proceedings of ICML, 2016
2016
-
[7]
Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier. Language modeling with gated convolutional networks. In D. Precup and Y. W. Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 933–941. PMLR, 06–11 Aug 2017
2017
-
[8]
M. Kim, D. Li, S. X. Hu, and T. Hospedales. Fisher SAM: Information geometry and sharpness aware minimisation. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 11148–11161. PMLR, 17–23 Jul 2022
2022
-
[9]
Krishnamurthy, T
K. Krishnamurthy, T. Can, and D. J. Schwab. Theory of gating in recurrent neural networks.Phys. Rev. X, 12:011011, Jan 2022. 22
2022
-
[10]
Levine, N
Y. Levine, N. Wies, O. Sharir, H. Bata, and A. Shashua. Limits to depth efficiencies of self-attention. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 22640–22651. Curran Associates, Inc., 2020
2020
-
[11]
Liang, T
T. Liang, T. Poggio, A. Rakhlin, and J. Stokes. Fisher-rao metric, geometry, and complexity of neural networks. In K. Chaudhuri and M. Sugiyama, editors,Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 888–896. PMLR, 16–18 Apr 2019
2019
-
[12]
Mont´ ufar, R
G. Mont´ ufar, R. Pascanu, K. Cho, and Y. Bengio. On the number of linear regions of deep neural networks. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, editors,Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014
2014
-
[13]
P´ erez, J
J. P´ erez, J. Marinkovi´ c, and P. Barcel´ o. On the turing completeness of modern neural network architectures. InInternational Conference on Learning Representations, 2019
2019
-
[14]
Z. Qiu, Z. Wang, B. Zheng, Z. Huang, K. Wen, S. Yang, R. Men, L. Yu, F. Huang, S. Huang, D. Liu, J. Zhou, and J. Lin. Gated attention for large language models: Non- linearity, sparsity, and attention-sink-free. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[15]
C. R. Rao. Information and the accuracy attainable in the estimation of statistical parameters.Bulletin of the Calcutta Mathematical Society, 37:81–91, 1945
1945
-
[16]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[17]
Wang and W
M. Wang and W. E. Understanding the expressive power and mechanisms of trans- former for sequence modeling. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[18]
Y. Wu, S. Zhang, Y. Zhang, Y. Bengio, and R. R. Salakhutdinov. On multiplicative integration with recurrent neural networks. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
2016
- [19]
-
[20]
Zhang, S
Y. Zhang, S. Yang, R. Zhu, Y. Zhang, L. Cui, Y. Wang, B. Wang, F. Shi, B. Wang, W. Bi, P. Zhou, and G. Fu. Gated slot attention for efficient linear-time sequence modeling. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 116870–116898. Curran ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.