Recognition: unknown
SynHAT: A Two-stage Coarse-to-Fine Diffusion Framework for Synthesizing Human Activity Traces
Pith reviewed 2026-05-10 11:28 UTC · model grok-4.3
The pith
SynHAT synthesizes realistic human activity traces through a two-stage coarse-to-fine diffusion process to enable privacy-preserving data use in mobility applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SynHAT addresses the challenges of irregular spatio-temporal dependencies and high computational costs in generating human activity traces by employing a two-stage coarse-to-fine diffusion model. In the first stage, Coarse-HADiff uses a Latent Spatio-Temporal U-Net with dual Drift-Jitter branches to model overall dependencies in coarse-grained traces. The second stage applies a three-step pipeline of Behavior Pattern Extraction, Fine-HADiff, and Semantic Alignment to produce fine-grained traces, resulting in improved data fidelity, utility, privacy, and scalability as demonstrated on multi-city datasets.
What carries the argument
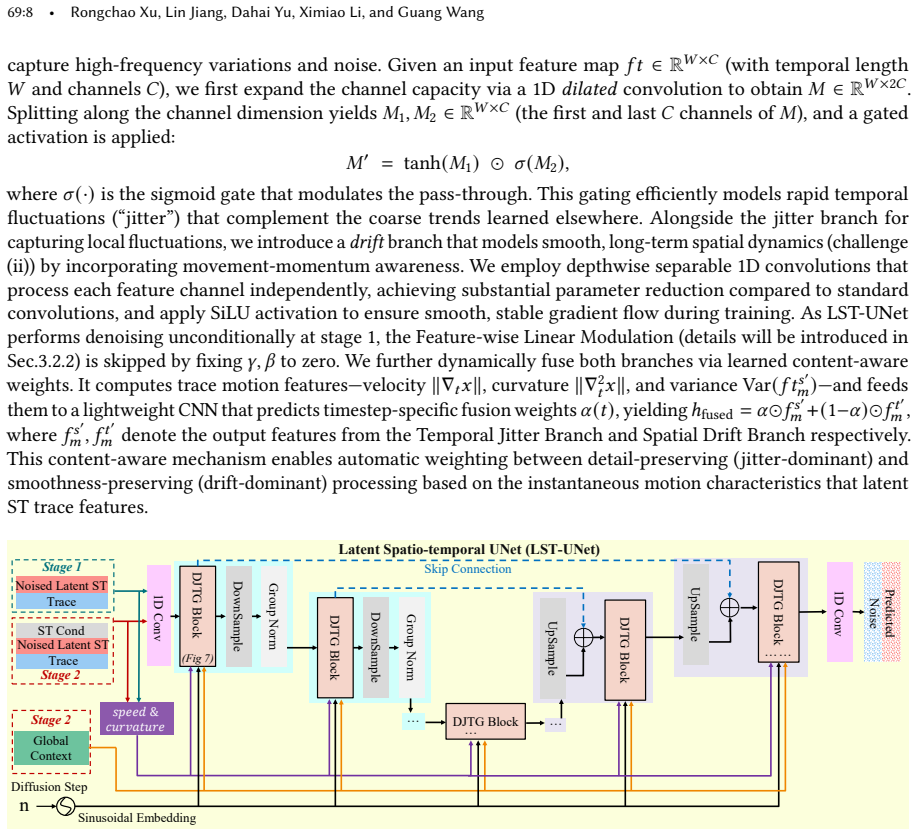
The Latent Spatio-Temporal U-Net with dual Drift-Jitter branches, which jointly models smooth spatial transitions and temporal variations in the denoising process of the diffusion model.
If this is right
- Synthetic HATs can be used for human mobility modeling without compromising user privacy.
- Downstream applications like POI recommendation gain from higher quality generated data.
- The framework scales to long-term, fine-grained synthesis efficiently.
- Evaluation shows substantial outperformance on spatial and temporal metrics across diverse real-world datasets.
Where Pith is reading between the lines
- If the method generalizes well, it could be applied to synthesize other types of irregular spatio-temporal data like vehicle movements or animal migrations.
- Improved synthetic data might lead to better training of predictive models for urban planning without needing raw private traces.
- Future work could test if combining it with other generative techniques further reduces any remaining biases in the outputs.
Load-bearing premise
The dual Drift-Jitter branches and the coarse-to-fine pipeline faithfully capture the complex, irregular distributions in real human activity traces without adding systematic errors that affect usefulness or privacy.
What would settle it
Running the model on a new large-scale HAT dataset from a city not used in training and finding that the generated traces show significantly worse spatial or temporal accuracy than real data or other methods.
Figures










read the original abstract
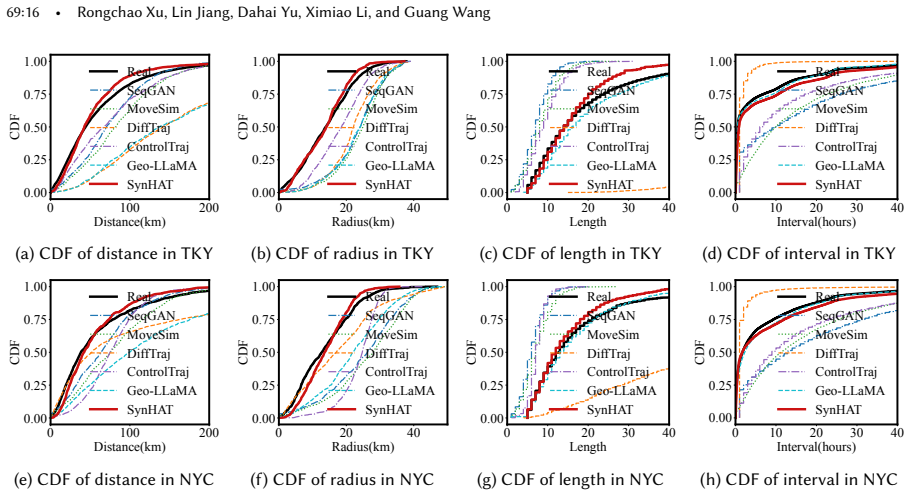
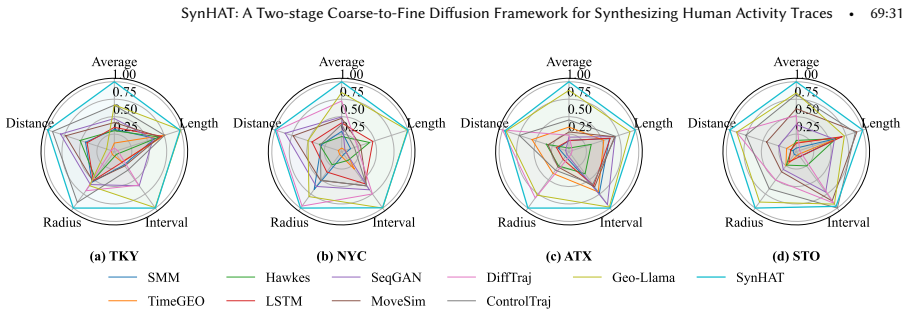
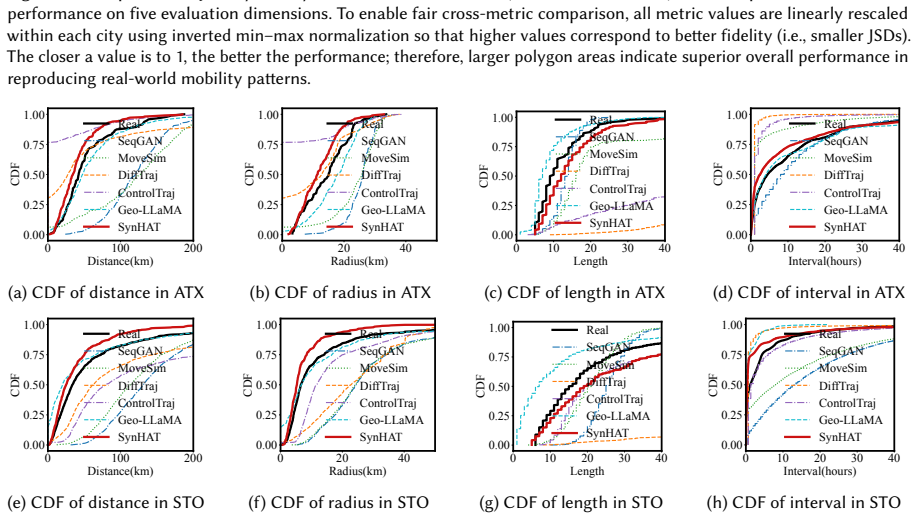
Human activity traces (HATs) are critical for many applications, including human mobility modeling and point-of-interest (POI) recommendation. However, growing privacy concerns have severely limited access to authentic large-scale HAT datasets. Recent advances in generative AI provide new opportunities to synthesize realistic and privacy-preserving HATs for such applications. Yet two major challenges remain: (i) HATs are highly irregular and dynamic, with long and varying time intervals, making it difficult to capture their complex spatio-temporal dependencies and underlying distributions; and (ii) generative models are often computationally expensive, making long-term, fine-grained HAT synthesis inefficient. To address these challenges, we propose SynHAT, a computationally efficient coarse-to-fine HAT synthesis framework built on a novel spatio-temporal denoising diffusion model. In Stage 1, we develop Coarse-HADiff, which models the overall spatio-temporal dependencies of coarse-grained latent spatio-temporal traces. It incorporates a novel Latent Spatio-Temporal U-Net with dual Drift-Jitter branches to jointly model smooth spatial transitions and temporal variations during denoising. In Stage 2, we introduce a three-step pipeline consisting of Behavior Pattern Extraction, Fine-HADiff, which shares the same architecture as Coarse-HADiff, and Semantic Alignment to generate fine-grained latent spatio-temporal traces from the Stage 1 outputs. We extensively evaluate SynHAT in terms of data fidelity, utility, privacy, robustness, and scalability. Experiments on real-world HAT datasets from four cities across three countries show that SynHAT substantially outperforms state-of-the-art baselines, achieving 52% and 33% improvements on spatial and temporal metrics, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SynHAT, a two-stage coarse-to-fine diffusion framework for synthesizing human activity traces (HATs). Stage 1 uses Coarse-HADiff with a novel Latent Spatio-Temporal U-Net incorporating dual Drift-Jitter branches to model coarse-grained spatio-temporal dependencies. Stage 2 applies a three-step pipeline (Behavior Pattern Extraction, Fine-HADiff sharing the same U-Net architecture, and Semantic Alignment) to produce fine-grained traces. Experiments on real-world HAT datasets from four cities across three countries report that SynHAT substantially outperforms state-of-the-art baselines, with 52% and 33% improvements on spatial and temporal metrics, alongside evaluations of fidelity, utility, privacy, robustness, and scalability.
Significance. If the central empirical claims hold after addressing validation gaps, this work would advance privacy-preserving synthetic data generation for human mobility modeling and POI recommendation by tackling the specific difficulties of irregular, long-interval spatio-temporal distributions. The coarse-to-fine design and specialized U-Net architecture are constructive responses to computational and modeling challenges. Credit is due for the multi-country dataset evaluation and the breadth of assessment dimensions (fidelity through privacy).
major comments (3)
- [§3.2] §3.2 (Latent Spatio-Temporal U-Net with dual Drift-Jitter branches): The formulation jointly models spatial transitions and temporal variations during denoising, but provides no explicit mechanism or analysis showing preservation of the discrete-event inter-arrival time distribution for HATs with highly variable long gaps. This is load-bearing for the 33% temporal metric improvement claim, as any implicit continuous or fixed-grid approximation risks systematic bias in generated interval statistics.
- [§5] §5 (Experiments and results): The headline 52% spatial / 33% temporal gains are presented without specification of exact baseline implementations, hyperparameter tuning protocols, statistical significance tests, error bars, data splits, or controls for post-hoc selection. This undermines verification of the central outperformance claim and must be remedied with full reproducibility details.
- [§3.4] §3.4 (Semantic Alignment in the three-step fine-grained pipeline): The alignment step between coarse Stage-1 outputs and fine Stage-2 traces lacks a quantitative demonstration that the joint spatio-temporal distribution is recovered without introducing artifacts that degrade temporal realism or downstream utility/privacy guarantees.
minor comments (3)
- [Abstract] Abstract: Define the acronym HAT on first use for clarity.
- [Figure 3] Figure 3 (U-Net architecture diagram): Add explicit labels for the Drift and Jitter branch inputs/outputs to improve readability.
- [§4] §4 (Related work): Ensure all compared baselines include precise citation details and version numbers where applicable.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects for strengthening the manuscript. We address each major comment below and commit to revisions that enhance clarity, reproducibility, and validation without misrepresenting our contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Latent Spatio-Temporal U-Net with dual Drift-Jitter branches): The formulation jointly models spatial transitions and temporal variations during denoising, but provides no explicit mechanism or analysis showing preservation of the discrete-event inter-arrival time distribution for HATs with highly variable long gaps. This is load-bearing for the 33% temporal metric improvement claim, as any implicit continuous or fixed-grid approximation risks systematic bias in generated interval statistics.
Authors: We appreciate this observation on the temporal modeling challenges. The dual Drift-Jitter branches are explicitly designed to separately handle smooth temporal drifts and stochastic jitter, enabling the model to capture irregular, long-gap inter-arrival patterns in discrete HAT events rather than relying on fixed-grid approximations. While the overall temporal metric gains and fidelity evaluations provide supporting evidence, we agree that a more targeted analysis would better substantiate the claim. In the revision, we will add quantitative validation including inter-arrival time histograms, Kolmogorov-Smirnov tests, and distribution comparisons between real and generated traces across the four cities. revision: partial
-
Referee: [§5] §5 (Experiments and results): The headline 52% spatial / 33% temporal gains are presented without specification of exact baseline implementations, hyperparameter tuning protocols, statistical significance tests, error bars, data splits, or controls for post-hoc selection. This undermines verification of the central outperformance claim and must be remedied with full reproducibility details.
Authors: We agree that the current presentation of experimental details is insufficient for full verification and reproducibility. The manuscript reports the improvements based on our implementations, but we will substantially expand Section 5 to include: exact baseline re-implementations with any adaptations and original references; comprehensive hyperparameter tuning protocols and final values; statistical significance tests (e.g., paired t-tests with p-values); error bars from multiple independent runs; precise train/validation/test splits per city; and explicit discussion of pre-specified evaluation protocols to address post-hoc selection concerns. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: [§3.4] §3.4 (Semantic Alignment in the three-step fine-grained pipeline): The alignment step between coarse Stage-1 outputs and fine Stage-2 traces lacks a quantitative demonstration that the joint spatio-temporal distribution is recovered without introducing artifacts that degrade temporal realism or downstream utility/privacy guarantees.
Authors: The Semantic Alignment step is formulated to preserve consistency while refining granularity, and the end-to-end results on fidelity, utility, and privacy metrics across datasets indicate that it does not introduce degrading artifacts. However, we acknowledge the benefit of isolating its contribution. In the revision, we will add targeted quantitative evaluations, including distribution distance metrics (e.g., MMD) on joint spatio-temporal features before and after alignment, plus ablation studies measuring impacts on temporal metrics, downstream task utility, and privacy guarantees to explicitly demonstrate recovery of the distributions without artifacts. revision: partial
Circularity Check
No significant circularity in SynHAT derivation chain
full rationale
The paper introduces SynHAT as a novel two-stage coarse-to-fine diffusion framework, with Coarse-HADiff using a Latent Spatio-Temporal U-Net with dual Drift-Jitter branches in Stage 1 and a three-step pipeline (Behavior Pattern Extraction, Fine-HADiff, Semantic Alignment) in Stage 2. All performance claims rest on direct empirical comparisons against external state-of-the-art baselines using standard spatial and temporal metrics on held-out real-world HAT datasets from four cities. No equations, fitted parameters, or self-citations are presented that would reduce any reported improvement or model component to an input by construction. The architecture and pipeline are described as original contributions addressing irregular spatio-temporal distributions, without invoking uniqueness theorems, ansatzes, or renamings from prior self-work that would create circularity. The evaluation remains independent and falsifiable against external data.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion noise schedule and U-Net hyperparameters
axioms (1)
- domain assumption Irregular HATs with varying time intervals can be effectively modeled via latent-space denoising diffusion processes.
Forward citations
Cited by 1 Pith paper
-
LatentRouter: Can We Choose the Right Multimodal Model Before Seeing Its Answer?
LatentRouter routes image-question queries to the best MLLM by predicting counterfactual performance via latent communication between learned query capsules and model capability tokens.
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. 2021. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems34 (2021), 17981–17993
2021
-
[2]
Kunlin Cai, Jinghuai Zhang, Will Shand, Zhiqing Hong, Guang Wang, Desheng Zhang, Jianfeng Chi, and Yuan Tian. 2024. Where have you been? A Study of Privacy Risk for Point-of-Interest Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1–12
2024
-
[3]
Mingfei Cai, Yanbo Pang, Takehiro Kashiyama, and Yoshihide Sekimoto. 2021. Simulating human mobility with agent-based modeling and particle filter following mobile spatial statistics. InProceedings of the 29th International Conference on Advances in Geographic Information Systems. 411–414
2021
-
[4]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. 2022. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11315–11325
2022
-
[5]
Yung-Ju Chang, Chu-Yuan Yang, Ying-Hsuan Kuo, Wen-Hao Cheng, Chun-Liang Yang, Fang-Yu Lin, I-Hui Yeh, Chih-Kuan Hsieh, Ching-Yu Hsieh, and Yu-Shuen Wang. 2019. Tourgether: Exploring tourists’ real-time sharing of experiences as a means of encouraging point-of-interest exploration.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Techn...
2019
-
[6]
Weiss, Mohammad Norouzi, and William Chan
Nanxin Chen, Yu Zhang, Heiga Zen, Ron J. Weiss, Mohammad Norouzi, and William Chan. 2021. WaveGrad: Estimating Gradients for Waveform Generation. InInternational Conference on Learning Representations (ICLR)
2021
-
[7]
Xueqi Cheng, Catherine Yang, Yuying Zhao, Yu Wang, Hamid Karimi, and Tyler Derr. 2025. BTS: A Comprehensive Benchmark for Tie Strength Prediction. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5345–5354
2025
-
[8]
Eunjoon Cho, Seth A Myers, and Jure Leskovec. 2011. Friendship and mobility: user movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 1082–1090
2011
-
[9]
Hidalgo, Michel Verleysen, and Vincent D
Yves-Alexandre de Montjoye, César A. Hidalgo, Michel Verleysen, and Vincent D. Blondel. 2013. Unique in the Crowd: The Privacy Bounds of Human Mobility.Scientific Reports3 (2013), 1376. https://doi.org/10.1038/srep01376
-
[10]
Yves-Alexandre De Montjoye, Laura Radaelli, Vivek Kumar Singh, and Alex “Sandy” Pentland. 2015. Unique in the shopping mall: On the reidentifiability of credit card metadata.Science347, 6221 (2015), 536–539. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., Vol. 10, No. 2, Article 69. Publication date: June 2026. 69:26•Rongchao Xu, Lin Jiang, Dahai Y...
2015
-
[11]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
2021
-
[12]
Yi Ding, Ling Liu, Yu Yang, Yunhuai Liu, Desheng Zhang, and Tian He. 2021. From conception to retirement: a lifetime story of a 3-year-old wireless beacon system in the wild.IEEE/ACM Transactions on Networking30, 1 (2021), 47–61
2021
-
[13]
Yi Ding, Yu Yang, Wenchao Jiang, Yunhuai Liu, Tian He, and Desheng Zhang. 2021. Nationwide deployment and operation of a virtual arrival detection system in the wild. InProceedings of the 2021 ACM SIGCOMM 2021 Conference. 705–717
2021
-
[14]
Aiden Doherty, Dan Jackson, Nils Hammerla, Thomas Plötz, Patrick Olivier, Malcolm H Granat, Tom White, Vincent T Van Hees, Michael I Trenell, Christoper G Owen, et al. 2017. Large scale population assessment of physical activity using wrist worn accelerometers: the UK biobank study.PloS one12, 2 (2017), e0169649
2017
-
[15]
Jie Feng, Zeyu Yang, Fengli Xu, Haisu Yu, Mudan Wang, and Yong Li. 2020. Learning to simulate human mobility. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3426–3433
2020
-
[16]
Letian Gong, Yan Lin, Xinyue Zhang, Yiwen Lu, Xuedi Han, Yichen Liu, Shengnan Guo, Youfang Lin, and Huaiyu Wan. 2024. Mobility-llm: Learning visiting intentions and travel preference from human mobility data with large language models.Advances in Neural Information Processing Systems37 (2024), 36185–36217
2024
-
[17]
Baoshen Guo, Zhiqing Hong, Lidan Cao, Donghang Li, Junyi Li, Can Rong, Alok Prakash, Shenhao Wang, and Jinhua Zhao. 2025. Language Models Meet Urban Mobility: A Data-Centric Review.Authorea Preprints(2025)
2025
- [18]
-
[19]
Baoshen Guo, Weijian Zuo, Shuai Wang, Wenjun Lyu, Zhiqing Hong, Yi Ding, Tian He, and Desheng Zhang. 2022. Wepos: Weak- supervised indoor positioning with unlabeled wifi for on-demand delivery.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 2 (2022), 1–25
2022
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[21]
Zhiqing Hong, Baoshen Guo, Wenjun Lyu, Haotian Wang, Yunhuai Liu, Guang Wang, Tian He, and Desheng Zhang. 2026. UrbanPOI: Updating Urban POIs with Large-scale Crowdsourcing for Location-based Services.IEEE Transactions on Mobile Computing(2026)
2026
-
[22]
Zhiqing Hong, Zelong Li, Shuxin Zhong, Wenjun Lyu, Haotian Wang, Yi Ding, Tian He, and Desheng Zhang. 2024. Crosshar: Generalizing cross-dataset human activity recognition via hierarchical self-supervised pretraining.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 2 (2024), 1–26
2024
-
[23]
Zhiqing Hong, Yiwei Song, Zelong Li, Anlan Yu, Shuxin Zhong, Yi Ding, Tian He, and Desheng Zhang. 2025. Llm4har: Generalizable on-device human activity recognition with pretrained llms. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4511–4521
2025
-
[24]
Zhiqing Hong, Weibing Wang, Anlan Yu, Shuxin Zhong, Haotian Wang, Yi Ding, Tian He, and Desheng Zhang. 2025. Experience Paper: Nationwide Human Behavior Sensing in Last-mile Delivery. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking. 682–696
2025
-
[25]
Renjun Hu, Jingbo Zhou, Xinjiang Lu, Hengshu Zhu, Shuai Ma, and Hui Xiong. 2020. NCF: A Neural Context Fusion Approach to Raw Mobility Annotation.IEEE Transactions on Mobile Computing21, 1 (2020), 226–238
2020
-
[26]
Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. 2022. Prodiff: Progressive fast diffusion model for high-quality text-to-speech. InProceedings of the 30th ACM International Conference on Multimedia. 2595–2605
2022
-
[27]
Sibren Isaacman, Richard Becker, Ramón Cáceres, Margaret Martonosi, James Rowland, Alexander Varshavsky, and Walter Willinger
-
[28]
InProceedings of the 10th international conference on Mobile systems, applications, and services
Human mobility modeling at metropolitan scales. InProceedings of the 10th international conference on Mobile systems, applications, and services. 239–252
-
[29]
Lin Jiang, Yu Yang, and Guang Wang. 2025. HCRide: harmonizing passenger fairness and driver preference for human-centered ride-hailing. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. 10289–10297
2025
-
[30]
Lin Jiang, Dahai Yu, Rongchao Xu, Tian Tang, and Guang Wang. 2025. Uncertainty-aware predict-then-optimize framework for equitable post-disaster power restoration. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. 9719–9727
2025
-
[31]
Adapting large language models by integrating collaborative semantics for recommen- dation
N. Jiang, H. Yuan, J. Si, M. Chen, and S. Wang. 2024. Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE Computer Society, Los Alamitos, CA, USA, 5061–5074. https://doi.org/10.1109/ICDE60146.2024.00104
-
[32]
Renhe Jiang, Xuan Song, Zipei Fan, Tianqi Xia, Zhaonan Wang, Quanjun Chen, Zekun Cai, and Ryosuke Shibasaki. 2021. Transfer urban human mobility via poi embedding over multiple cities.ACM Transactions on Data Science2, 1 (2021), 1–26
2021
-
[33]
Shan Jiang, Yingxiang Yang, Siddharth Gupta, Daniele Veneziano, Shounak Athavale, and Marta C González. 2016. The TimeGeo modeling framework for urban mobility without travel surveys.Proceedings of the National Academy of Sciences113, 37 (2016), E5370–E5378
2016
-
[34]
Youngji Koh, Chanhee Lee, Eunki Joung, Hyunsoo Lee, and Uichin Lee. 2025. Harnessing Home IoT for Self-tracking Emotional Wellbeing: Behavioral Patterns, Self-reflection, and Privacy Concerns.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–36. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., Vol. 10,...
2025
-
[35]
Xiangjie Kong, Qiao Chen, Mingliang Hou, Hui Wang, and Feng Xia. 2023. Mobility trajectory generation: a survey.Artificial Intelligence Review56, Suppl 3 (2023), 3057–3098
2023
-
[36]
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. 2020. DiffWave: A Versatile Diffusion Model for Audio Synthesis. arXiv preprint arXiv:2009.09761(2020)
work page internal anchor Pith review arXiv 2020
-
[37]
Vladimir Kulikov, Shahar Yadin, Matan Kleiner, and Tomer Michaeli. 2023. Sinddm: A single image denoising diffusion model. In International Conference on Machine Learning. PMLR, 17920–17930
2023
- [38]
-
[39]
Huoran Li, Fuqi Lin, Xuan Lu, Chenren Xu, Gang Huang, Jun Zhang, Qiaozhu Mei, and Xuanzhe Liu. 2020. Systematic analysis of fine-grained mobility prediction with on-device contextual data.IEEE Transactions on Mobile Computing21, 3 (2020), 1096–1109
2020
-
[40]
Lincan Li, Eren Erman Ozguven, Yue Zhao, Guang Wang, Yiqun Xie, and Yushun Dong. 2025. TyphoFormer: Language-Augmented Transformer for Accurate Typhoon Track Forecasting. InProceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’25). Association for Computing Machinery, New York, NY, USA, 1174–1177. ...
-
[41]
Lincan Li, Kaixiang Yang, Jichao Bi, and Fengji Luo. 2024. STS-CCL: Spatial-Temporal Synchronous Contextual Contrastive Learning for Urban Traffic Forecasting. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 6705–6709. https://doi.org/10.1109/ICASSP48485.2024.10446624
- [42]
-
[43]
Siyu Li, Toan Tran, Haowen Lin, John Krumm, Cyrus Shahabi, Lingyi Zhao, Khurram Shafique, and Li Xiong. 2025. Geo-Llama: Leveraging LLMs for Human Mobility Trajectory Generation with Constraints. In2025 26th IEEE International Conference on Mobile Data Management (MDM). IEEE, 20–31
2025
-
[44]
Xi’ang Li, Jinqi Luo, and Rabih Younes. 2020. ActivityGAN: Generative adversarial networks for data augmentation in sensor-based human activity recognition. InAdjunct proceedings of the 2020 ACM international joint conference on pervasive and ubiquitous computing and proceedings of the 2020 ACM international symposium on wearable computers. 249–254
2020
-
[45]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. 2022. Diffusion-lm improves controllable text generation.Advances in neural information processing systems35 (2022), 4328–4343
2022
-
[46]
Zhonghang Li, Lianghao Xia, Jiabin Tang, Yong Xu, Lei Shi, Long Xia, Dawei Yin, and Chao Huang. 2024. Urbangpt: Spatio-temporal large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5351–5362
2024
-
[47]
Chengwu Liao, Chao Chen, Suiming Guo, Zhu Wang, Yaxiao Liu, Ke Xu, and Daqing Zhang. 2022. Wheels know why you travel: Predicting trip purpose via a dual-attention graph embedding network.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 1 (2022), 1–22
2022
-
[48]
J. Lin. 1991. Divergence measures based on the Shannon entropy.IEEE Transactions on Information Theory37, 1 (1991), 145–151. https://doi.org/10.1109/18.61115
-
[49]
Feng Lyu, Jie Zhang, Huali Lu, Huaqing Wu, Fan Wu, Yongmin Zhang, and Yaoxue Zhang. 2024. SynthCAT: Synthesizing Cellular Association Traces with Fusion of Model-Based and Data-Driven Approaches.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 4 (2024), 1–24
2024
-
[50]
Haojie Ma, Zhijie Zhang, Wenzhong Li, and Sanglu Lu. 2021. Unsupervised human activity representation learning with multi-task deep clustering.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 1 (2021), 1–25
2021
-
[51]
Leandros A Maglaras and Dimitrios Katsaros. 2015. Social clustering of vehicles based on semi-Markov processes.IEEE Transactions on Vehicular Technology65, 1 (2015), 318–332
2015
- [52]
-
[53]
Suraj Nair, Kiran Javkar, Jiahui Wu, and Vanessa Frias-Martinez. 2019. Understanding cycling trip purpose and route choice using GPS traces and open data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies3, 1 (2019), 1–26
2019
-
[54]
Kyosuke Nishida, Hiroyuki Toda, Takeshi Kurashima, and Yoshihiko Suhara. 2014. Probabilistic identification of visited point-of-interest for personalized automatic check-in. InProceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing. 631–642
2014
-
[55]
Kun Ouyang, Reza Shokri, David S Rosenblum, and Wenzhuo Yang. 2018. A non-parametric generative model for human trajectories.. InIJCAI, Vol. 18. 3812–3817
2018
-
[56]
Farshid Salemi Parizi, Eric Whitmire, and Shwetak Patel. 2019. Auraring: Precise electromagnetic finger tracking.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies3, 4 (2019), 1–28
2019
-
[57]
Bo Qiang, Yuxuan Song, Minkai Xu, Jingjing Gong, Bowen Gao, Hao Zhou, Wei-Ying Ma, and Yanyan Lan. 2023. Coarse-to-fine: a hierarchical diffusion model for molecule generation in 3d. InInternational conference on machine learning. PMLR, 28277–28299
2023
-
[58]
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland Vollgraf. 2021. Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting. InProceedings of the 38th International Conference on Machine Learning (ICML). PMLR. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., Vol. 10, No. 2, Article 69. Publication date: ...
2021
-
[59]
Luca Rossi, Andrea Ajmar, Marina Paolanti, and Roberto Pierdicca. 2021. Vehicle trajectory prediction and generation using LSTM models and GANs.Plos one16, 7 (2021), e0253868
2021
-
[60]
Stefan Schestakov and Simon Gottschalk. 2025. Trajectory Representation Learning on Grids and Road Networks with Spatio-Temporal Dynamics.ACM Transactions on Intelligent Systems and Technology(2025)
2025
- [61]
-
[62]
Bolin Shen, Eren Ozguven, Yue Zhao, Guang Wang, Yiqun Xie, and Yushun Dong. 2025. Learning from the Storm: A Multivariate Machine Learning Approach to Predicting Hurricane-Induced Economic Losses. InProceedings of the 1st ACM SIGSPATIAL International Workshop on Spatial Intelligence for Smart and Connected Communities. 1–4
2025
- [63]
-
[64]
Mahan Tabatabaie, Suining He, and Kang G Shin. 2023. Cross-modality graph-based language and sensor data co-learning of human- mobility interaction.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 3 (2023), 1–25
2023
-
[65]
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. 2021. CSDI: Conditional Score-based Diffusion Models for Imputation of Missing Values in Time Series. InAdvances in Neural Information Processing Systems (NeurIPS)
2021
-
[66]
Farbod Taymouri, Marcello La Rosa, and Sarah M Erfani. 2021. A deep adversarial model for suffix and remaining time prediction of event sequences. InProceedings of the 2021 SIAM International Conference on Data Mining (SDM). SIAM, 522–530
2021
-
[67]
Ekin Uğurel, Shuai Huang, and Cynthia Chen. 2024. Learning to generate synthetic human mobility data: A physics-regularized Gaussian process approach based on multiple kernel learning.Transportation Research Part B: Methodological189 (2024), 103064
2024
-
[68]
Sumer S Vaid, Saeed Abdullah, Edison Thomaz, and Gabriella M Harari. 2021. Ubiquitous computing for person-environment research: Opportunities, considerations, and future directions. InMeasuring and modeling persons and situations. Elsevier, 103–143
2021
-
[69]
Yonatan Vaizman, Katherine Ellis, and Gert Lanckriet. 2017. Recognizing detailed human context in the wild from smartphones and smartwatches.IEEE pervasive computing16, 4 (2017), 62–74
2017
-
[70]
Tim Van Erven and Peter Harremos. 2014. Rényi divergence and Kullback-Leibler divergence.IEEE Transactions on Information Theory 60, 7 (2014), 3797–3820
2014
- [71]
-
[72]
Jinzhong Wang, Xiangjie Kong, Feng Xia, and Lijun Sun. 2019. Urban human mobility: Data-driven modeling and prediction.ACM SIGKDD explorations newsletter21, 1 (2019), 1–19
2019
-
[73]
Qingxin Wei, Jiaming Huang, Yi Gao, and Wei Dong. 2025. One Model to Fit Them All: Universal IMU-based Human Activity Recognition with LLM-assisted Cross-dataset Representation.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–22
2025
-
[74]
Min Xie, Hongzhi Yin, Hao Wang, Fanjiang Xu, Weitong Chen, and Sen Wang. 2016. Learning graph-based poi embedding for location-based recommendation. InProceedings of the 25th ACM international on conference on information and knowledge management. 15–24
2016
-
[75]
Rongchao Xu, Kunlin Cai, Lin Jiang, Zhiqing Hong, Yuan Tian, and Guang Wang. 2026. GeoGen: A Two-stage Coarse-to-Fine Framework for Fine-grained Synthetic Location-based Social Network Trajectory Generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 1373–1381
2026
-
[76]
Rongchao Xu, Zhiqing Hong, and Guang Wang. 2025. AutoSTDiff: Autoregressive Spatio-Temporal Denoising Diffusion Model for Asynchronous Trajectory Generation. InProceedings of the 2025 SIAM International Conference on Data Mining (SDM). SIAM, 538–547
2025
-
[77]
Zhixian Yan, Dipanjan Chakraborty, Christine Parent, Stefano Spaccapietra, and Karl Aberer. 2013. Semantic trajectories: Mobility data computation and annotation.ACM Transactions on Intelligent Systems and Technology (TIST)4, 3 (2013), 1–38
2013
-
[78]
Dingqi Yang, Daqing Zhang, and Bingqing Qu. 2016. Participatory cultural mapping based on collective behavior data in location-based social networks.ACM Transactions on Intelligent Systems and Technology (TIST)7, 3 (2016), 1–23
2016
-
[79]
Dingqi Yang, Daqing Zhang, Vincent W Zheng, and Zhiyong Yu. 2014. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs.IEEE Transactions on Systems, Man, and Cybernetics: Systems45, 1 (2014), 129–142
2014
-
[80]
Xi Yang, Suining He, Bing Wang, and Mahan Tabatabaie. 2021. Spatio-temporal graph attention embedding for joint crowd flow and transition predictions: A Wi-Fi-based mobility case study.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 4 (2021), 1–24
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.