Recognition: unknown
HWE-Bench: Benchmarking LLM Agents on Real-World Hardware Bug Repair Tasks
Pith reviewed 2026-05-10 11:23 UTC · model grok-4.3
The pith
LLM agents repair 70.7% of real hardware bugs from open-source projects, with success falling on complex designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HWE-Bench supplies 417 real-world hardware bug repair tasks extracted from historical pull requests in RISC-V core, SoC, and security projects. The best LLM agent resolves 70.7 percent of these tasks when operating in containerized environments that run the projects' native simulation and regression suites. Performance varies sharply with project complexity, exceeding 90 percent on small cores and dropping below 65 percent on large SoCs. Gaps between models are wider than those reported for software bug repair, and difficulty correlates with scope and bug-type mix rather than file size. Agent errors concentrate in fault localization, hardware-semantic reasoning, and cross-artifact care.
What carries the argument
HWE-Bench benchmark of 417 tasks derived from historical bug-fix pull requests across six hardware projects, executed inside containerized native simulation environments for validation.
If this is right
- Current LLM agents can already address a substantial portion of hardware debugging work.
- Project scale and the mix of bug types influence success more than the amount of code involved.
- Hardware-specific reasoning and multi-file coordination remain key obstacles for further gains.
- The benchmark supplies a concrete way to measure progress toward hardware-aware agents.
Where Pith is reading between the lines
- Specialized training on hardware description languages and simulation traces could narrow performance gaps on larger projects.
- The automated extraction pipeline allows the benchmark to grow as new hardware repositories release bug fixes.
- Improved agents on this benchmark may shorten iteration times in hardware design by automating routine repairs.
Load-bearing premise
The 417 tasks drawn from historical bug-fix pull requests constitute a representative sample of real hardware debugging problems, and the containerized simulation flows correctly verify that an edit resolves the bug without creating new problems.
What would settle it
An experiment showing that agents achieve comparable success rates on small cores and complex SoCs, or that success correlates strongly with code size rather than project scope and bug-type distribution.
Figures


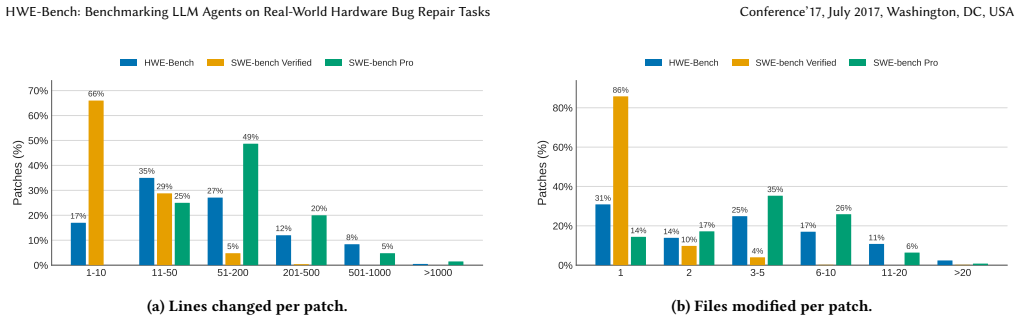

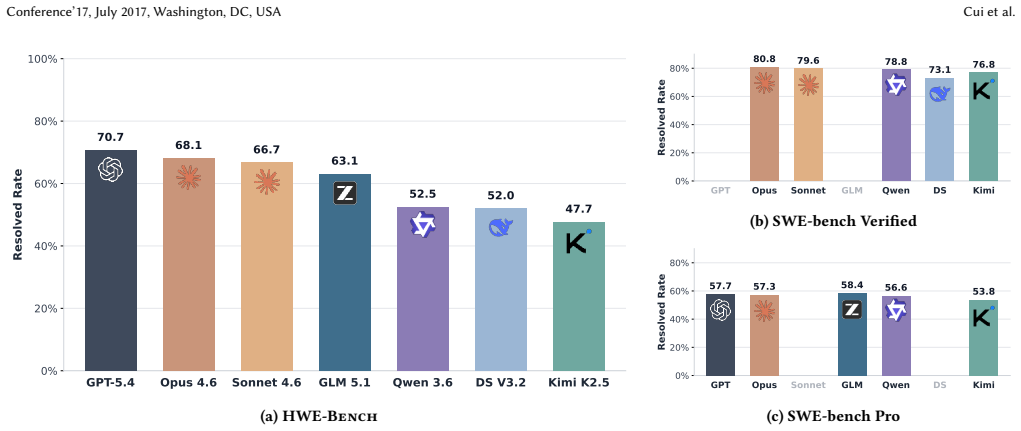
read the original abstract
Existing benchmarks for hardware design primarily evaluate Large Language Models (LLMs) on isolated, component-level tasks such as generating HDL modules from specifications, leaving repository-scale evaluation unaddressed. We introduce HWE-Bench, the first large-scale, repository-level benchmark for evaluating LLM agents on real-world hardware bug repair tasks. HWE-Bench comprises 417 task instances derived from real historical bug-fix pull requests across six major open-source projects spanning both Verilog/SystemVerilog and Chisel, covering RISC-V cores, SoCs, and security roots-of-trust. Each task is grounded in a fully containerized environment where the agent must resolve a real bug report, with correctness validated through the project's native simulation and regression flows. The benchmark is built through a largely automated pipeline that enables efficient expansion to new repositories. We evaluate seven LLMs with four agent frameworks and find that the best agent resolves 70.7% of tasks overall, with performance exceeding 90% on smaller cores but dropping below 65% on complex SoC-level projects. We observe larger performance gaps across models than commonly reported on software benchmarks, and difficulty is driven by project scope and bug-type distribution rather than code size alone. Our failure analysis traces agent failures to three stages of the debugging process: fault localization, hardware-semantic reasoning, and cross-artifact coordination across RTL, configuration, and verification components, providing concrete directions for developing more capable hardware-aware agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HWE-Bench, the first repository-scale benchmark for LLM agents on hardware bug repair, comprising 417 tasks extracted from historical bug-fix PRs across six open-source Verilog/SystemVerilog and Chisel projects (RISC-V cores, SoCs, security roots-of-trust). Tasks are executed in containerized native simulation environments with correctness checked via project regression flows. Evaluation of seven LLMs across four agent frameworks shows the best agent resolving 70.7% of tasks overall (>90% on small cores, <65% on complex SoCs), with larger model gaps than typical software benchmarks; difficulty correlates with project scope and bug-type distribution rather than code size. Failure analysis attributes errors to three stages: fault localization, hardware-semantic reasoning, and cross-artifact coordination.
Significance. If the task sample is representative and native validation is faithful, the benchmark supplies a much-needed repo-level testbed for hardware agents, quantifies performance drops on realistic SoC-scale bugs, and supplies a concrete three-stage failure taxonomy that can steer future work on hardware-aware reasoning and multi-artifact coordination. The largely automated curation pipeline is also a reusable strength.
major comments (3)
- [Task curation (abstract and methods)] The headline resolution rate (70.7%) and the claim that difficulty is driven by project scope/bug-type rather than code size rest on the representativeness of the 417 tasks. The abstract states they are 'derived from real historical bug-fix pull requests,' yet provides only high-level descriptions of selection criteria; because the source PRs are all eventually successful human fixes, the sample may systematically under-represent unfixable or corner-case bugs, directly affecting both aggregate scores and the scope-vs.-size conclusion.
- [Evaluation and validation methodology (abstract)] Correctness of proposed edits is validated solely through the projects' native simulation and regression flows. The abstract asserts this 'accurately validate[s] whether a proposed edit truly resolves the bug,' but does not report coverage metrics, whether the original bug report's triggering conditions are re-executed, or checks for side-effects outside the regression suite. Any gaps here would invalidate the per-project performance gaps and the three-stage failure taxonomy.
- [Failure analysis] The failure analysis traces errors to 'fault localization, hardware-semantic reasoning, and cross-artifact coordination.' No quantitative breakdown (e.g., percentage of failures per stage) or description of how the taxonomy was derived (manual review protocol, inter-annotator agreement) is supplied, so the diagnostic claim cannot be assessed for robustness.
minor comments (2)
- [Abstract] The abstract asserts 'larger performance gaps across models than commonly reported on software benchmarks' without citing the specific software benchmarks or gap sizes used for comparison.
- [Evaluation setup] Notation for agent frameworks and model identifiers should be introduced once with a table or explicit list to avoid ambiguity when results are discussed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revision where appropriate.
read point-by-point responses
-
Referee: [Task curation (abstract and methods)] The headline resolution rate (70.7%) and the claim that difficulty is driven by project scope/bug-type rather than code size rest on the representativeness of the 417 tasks. The abstract states they are 'derived from real historical bug-fix pull requests,' yet provides only high-level descriptions of selection criteria; because the source PRs are all eventually successful human fixes, the sample may systematically under-represent unfixable or corner-case bugs, directly affecting both aggregate scores and the scope-vs.-size conclusion.
Authors: We appreciate the referee raising this point on potential sampling bias. Our choice to use successful historical bug-fix PRs follows the standard practice in repository-level bug repair benchmarks (e.g., SWE-Bench) to ensure each task has a verifiable ground-truth patch that can be automatically validated. This design prioritizes tasks with known human fixes over unfixable cases, for which no reliable evaluation signal exists. We acknowledge that this may under-sample certain corner cases and will expand the Methods section with more granular details on the PR selection, filtering, and extraction criteria. Our empirical analysis of difficulty drivers (project scope, bug-type distribution) is derived from direct measurements across the 417 tasks and holds after controlling for code size; we will add supporting statistics to make this explicit. revision: partial
-
Referee: [Evaluation and validation methodology (abstract)] Correctness of proposed edits is validated solely through the projects' native simulation and regression flows. The abstract asserts this 'accurately validate[s] whether a proposed edit truly resolves the bug,' but does not report coverage metrics, whether the original bug report's triggering conditions are re-executed, or checks for side-effects outside the regression suite. Any gaps here would invalidate the per-project performance gaps and the three-stage failure taxonomy.
Authors: We agree that additional methodological transparency is warranted. In the revision we will clarify that the native regression flows re-execute the specific test cases and stimuli associated with the original bug report (as documented in the PRs) and verify that no new failures are introduced in the broader suite. We will also report available code coverage figures for the regression suites used. While the projects' maintainers treat these flows as the authoritative validation standard, we recognize that explicit side-effect and coverage details were insufficiently documented and will add them to the Evaluation section. revision: yes
-
Referee: [Failure analysis] The failure analysis traces errors to 'fault localization, hardware-semantic reasoning, and cross-artifact coordination.' No quantitative breakdown (e.g., percentage of failures per stage) or description of how the taxonomy was derived (manual review protocol, inter-annotator agreement) is supplied, so the diagnostic claim cannot be assessed for robustness.
Authors: The taxonomy was obtained by the authors through manual categorization of failure traces from a sampled subset of unsuccessful agent runs, mapping each error to the earliest stage where the agent diverged from a correct resolution path. We will add a quantitative breakdown (percentages of failures per stage) and a concise description of the review protocol to the revised Failure Analysis section. Formal inter-annotator agreement statistics were not computed, as the analysis was performed by the core team; we will note this limitation and make the categorization criteria fully reproducible. revision: yes
Circularity Check
No circularity: benchmark results are direct empirical measurements on external projects
full rationale
The paper introduces HWE-Bench by extracting 417 tasks from historical bug-fix PRs in six independent open-source hardware repositories and validates fixes via each project's native containerized simulation flows. Reported metrics (70.7% overall resolution, >90% on small cores, <65% on SoCs) and the three-stage failure taxonomy are direct counts and qualitative analysis of agent runs against these external ground-truth oracles. No equations, fitted parameters, predictions, or uniqueness theorems appear; no self-citations are load-bearing for the central claims; and no renaming of known results occurs. The derivation chain consists solely of task construction, agent execution, and outcome measurement, all anchored outside the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bug fixes from historical pull requests can be isolated as self-contained tasks with sufficient context for an agent to attempt repair.
- domain assumption Passing the project's native simulation and regression tests confirms that the bug has been correctly resolved.
Reference graph
Works this paper leans on
-
[1]
Hammad Ahmad, Yu Huang, and Westley Weimer. 2022. CirFix: Automatically repairing defects in hardware design code. InProceedings of the 27th ACM In- ternational Conference on Architectural Support for Programming Languages and Operating Systems. 990–1003
2022
-
[2]
Anthropic. 2025. Claude Code. https://github.com/anthropics/claude-code. Offi- cial GitHub repository
2025
-
[3]
Anthropic. 2026. Claude Opus 4.6 System Card. https://www.anthropic.com/ claude-opus-4-6-system-card. Official system card
2026
-
[4]
Anthropic. 2026. Claude Sonnet 4.6 System Card. https://www.anthropic.com/ claude-sonnet-4-6-system-card. Official system card. 8 HWE-Bench: Benchmarking LLM Agents on Real-World Hardware Bug Repair Tasks Conference’17, July 2017, Washington, DC, USA
2026
-
[5]
Fan Cui, Chenyang Yin, Kexing Zhou, Youwei Xiao, Guangyu Sun, Qiang Xu, Qipeng Guo, Yun Liang, Xingcheng Zhang, Demin Song, et al. 2024. Origen: En- hancing rtl code generation with code-to-code augmentation and self-reflection. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
-
[6]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. 2025. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941(2025)
work page internal anchor Pith review arXiv 2025
-
[7]
Weimin Fu, Shijie Li, Yier Jin, and Xiaolong Guo. 2025. HWFixBench: Bench- marking Tools for Hardware Understanding and Fault Repair. InProceedings of the Great Lakes Symposium on VLSI 2025. 427–434
2025
-
[8]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review arXiv 2023
-
[9]
Kevin Laeufer, Brandon Fajardo, Abhik Ahuja, Vighnesh Iyer, Borivoje Nikolić, and Koushik Sen. 2024. RTL-repair: Fast symbolic repair of hardware design code. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 867–881
2024
-
[10]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
-
[11]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. Ver- ilogeval: Evaluating large language models for verilog code generation. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 1–8
2023
-
[12]
Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. 2024. RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems(2024)
2024
-
[13]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. StarCoder 2 and The Stack v2: The Next Generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review arXiv 2024
-
[14]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. Rtllm: An open-source benchmark for design rtl generation with large language model. In2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 722–727
2024
-
[15]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al
-
[16]
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868(2026)
work page internal anchor Pith review arXiv 2026
-
[17]
Moonshot AI. 2025. Kimi Code CLI. https://github.com/MoonshotAI/kimi-cli. Official GitHub repository
2025
-
[18]
OpenAI. 2025. Codex CLI. https://github.com/openai/codex. Official GitHub repository
2025
-
[19]
OpenAI. 2026. GPT-5.4 Thinking System Card. https://openai.com/index/gpt-5- 4-thinking-system-card/. Official system card for GPT-5.4 Thinking
2026
-
[20]
Jingyu Pan, Guanglei Zhou, Chen-Chia Chang, Isaac Jacobson, Jiang Hu, and Yiran Chen. 2025. A survey of research in large language models for electronic design automation.ACM Transactions on Design Automation of Electronic Systems 30, 3 (2025), 1–21
2025
-
[21]
Nathaniel Pinckney, Chenhui Deng, Chia-Tung Ho, Yun-Da Tsai, Mingjie Liu, Wenfei Zhou, Brucek Khailany, and Haoxing Ren. 2025. Comprehensive Verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on rtl design and verification.arXiv preprint arXiv:2506.14074(2025)
-
[22]
Qwen Team. 2026. Qwen3.6-Plus: Towards Real World Agents. https://qwen.ai/ blog?id=qwen3.6. Official Alibaba Cloud release post
2026
-
[23]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al . 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review arXiv 2026
-
[24]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Z.ai. 2026. GLM-5.1: Towards Long-Horizon Tasks. https://z.ai/blog/glm-5.1. Official release blog
2026
- [26]
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.