Recognition: unknown
RELOAD: A Robust and Efficient Learned Query Optimizer for Database Systems
Pith reviewed 2026-05-10 10:05 UTC · model grok-4.3
The pith
RELOAD is a learned query optimizer that reduces individual query performance regressions and reaches expert plan quality faster than prior reinforcement learning methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
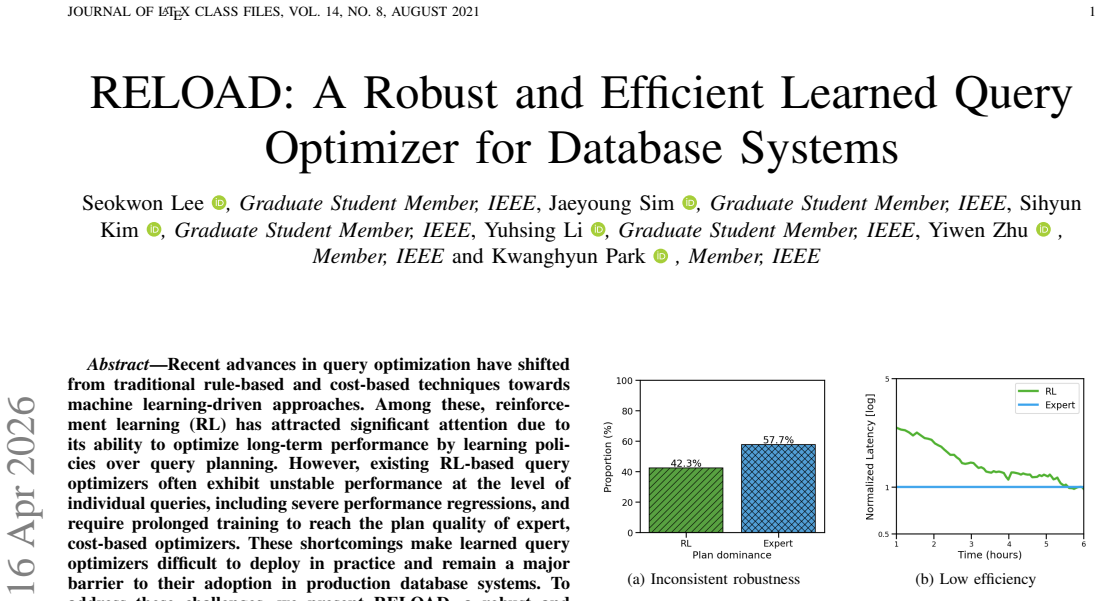
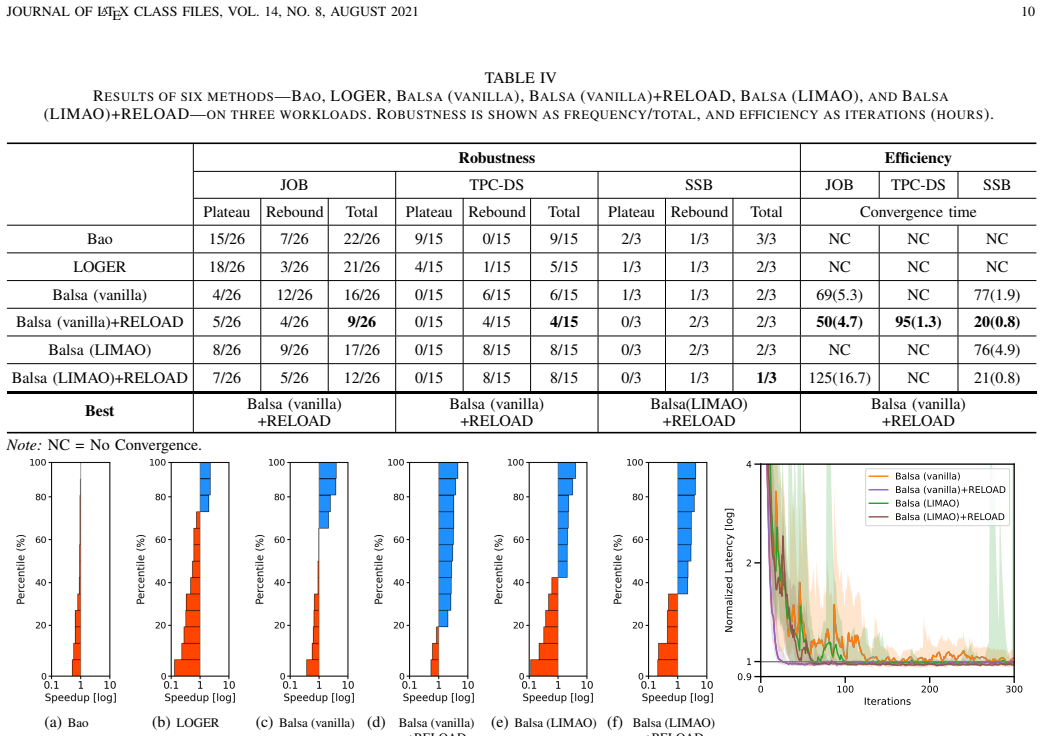
RELOAD is a robust and efficient learned query optimizer for database systems that minimizes query-level performance regressions and ensures consistent optimization behavior across executions while accelerating convergence to the plan quality of expert cost-based optimizers, demonstrated through experiments on the Join Order Benchmark, TPC-DS, and Star Schema Benchmark to achieve up to 2.4x higher robustness and 3.1x greater efficiency compared to state-of-the-art RL-based query optimization techniques.
What carries the argument
RELOAD's dual focus on minimizing query-level performance regressions for robustness and accelerating convergence to expert-level plan quality for efficiency.
If this is right
- Reinforcement learning based query optimizers can avoid severe performance regressions on individual queries.
- Training for learned optimizers reaches expert plan quality with substantially less time and compute.
- Optimization behavior becomes consistent across repeated executions of the same query.
- Learned query optimizers become easier to deploy in production database systems by addressing instability and slow training.
Where Pith is reading between the lines
- If the gains hold beyond the tested benchmarks, learned methods could replace or augment cost-based optimizers in more database systems.
- The same robustness techniques might reduce risk when applying reinforcement learning to other database tuning tasks like indexing or resource allocation.
- Production systems could adopt such optimizers with lower monitoring overhead if regressions are reliably bounded.
Load-bearing premise
The robustness and efficiency improvements measured on three standard benchmarks will hold for arbitrary real-world database workloads, schema changes, and hardware without extra tuning or unexpected drops.
What would settle it
A new benchmark workload or production trace where RELOAD produces at least one query plan whose execution time exceeds the best traditional optimizer by a larger margin than reported in the paper's experiments.
Figures






read the original abstract
Recent advances in query optimization have shifted from traditional rule-based and cost-based techniques towards machine learning-driven approaches. Among these, reinforcement learning (RL) has attracted significant attention due to its ability to optimize long-term performance by learning policies over query planning. However, existing RL-based query optimizers often exhibit unstable performance at the level of individual queries, including severe performance regressions, and require prolonged training to reach the plan quality of expert, cost-based optimizers. These shortcomings make learned query optimizers difficult to deploy in practice and remain a major barrier to their adoption in production database systems. To address these challenges, we present RELOAD, a robust and efficient learned query optimizer for database systems. RELOAD focuses on (i) robustness, by minimizing query-level performance regressions and ensuring consistent optimization behavior across executions, and (ii) efficiency, by accelerating convergence to expert-level plan quality. Through extensive experiments on standard benchmarks, including Join Order Benchmark, TPC-DS, and Star Schema Benchmark, RELOAD demonstrates up to 2.4x higher robustness and 3.1x greater efficiency compared to state-of-the-art RL-based query optimization techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RELOAD, a reinforcement learning-based learned query optimizer for database systems. It targets two main issues in prior RL query optimizers: unstable per-query performance (including regressions) and slow convergence to the plan quality of expert cost-based optimizers. RELOAD claims to improve robustness by minimizing query-level regressions and ensuring consistent behavior, and efficiency by accelerating training. Experiments on the Join Order Benchmark, TPC-DS, and Star Schema Benchmark are reported to yield up to 2.4x higher robustness and 3.1x greater efficiency relative to state-of-the-art RL-based techniques.
Significance. If the robustness and efficiency gains are reproducible and the approach generalizes, the work could meaningfully lower barriers to deploying learned query optimizers in production systems. Addressing per-query instability and training time directly tackles practical adoption hurdles that have limited prior RL methods.
major comments (2)
- [Experiments] Experiments section: The reported 2.4x robustness and 3.1x efficiency gains are demonstrated only on JOB, TPC-DS, and SSB. These benchmarks share similar join structures, data scales, and query templates; no results are shown for schema evolution, data distribution shifts, or production-style ad-hoc queries. This leaves the central claim of robustness for arbitrary real-world workloads without direct support.
- [Methods] Methods and evaluation protocol: The abstract and reported results provide no details on experimental protocol, statistical significance testing, hyperparameter search procedure, number of runs, or controls for post-hoc selection of reported numbers. Without these, the quantitative claims cannot be fully assessed for soundness.
minor comments (2)
- [Abstract] The abstract would be strengthened by a concise statement of the core algorithmic modifications in RELOAD (e.g., specific changes to the RL policy or reward function) rather than remaining at a high-level description.
- Notation for robustness and efficiency metrics should be defined explicitly when first introduced to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, providing honest clarifications based on the current manuscript and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported 2.4x robustness and 3.1x efficiency gains are demonstrated only on JOB, TPC-DS, and SSB. These benchmarks share similar join structures, data scales, and query templates; no results are shown for schema evolution, data distribution shifts, or production-style ad-hoc queries. This leaves the central claim of robustness for arbitrary real-world workloads without direct support.
Authors: We agree that the evaluation is confined to JOB, TPC-DS, and SSB, which are standard benchmarks in the query optimization literature but do not encompass schema evolution, data distribution shifts, or fully ad-hoc production queries. However, the manuscript does not assert robustness for arbitrary real-world workloads; the claims of up to 2.4x higher robustness and 3.1x greater efficiency are explicitly tied to results on these three benchmarks, which include diverse join orders, query templates, and data scales. To address the concern, we will make a partial revision by adding an explicit limitations subsection in the revised manuscript that discusses the scope of the claims, potential generalization challenges, and directions for future work on more dynamic workloads. No new experiments are added at this stage, as the current results remain valid for the evaluated settings. revision: partial
-
Referee: [Methods] Methods and evaluation protocol: The abstract and reported results provide no details on experimental protocol, statistical significance testing, hyperparameter search procedure, number of runs, or controls for post-hoc selection of reported numbers. Without these, the quantitative claims cannot be fully assessed for soundness.
Authors: We acknowledge that the manuscript currently provides insufficient detail on the experimental protocol, which limits full assessment of the results. In the revised version, we will expand the Experiments section (and add a dedicated subsection if needed) to include: the complete experimental protocol; statistical significance testing (reporting means, standard deviations over multiple runs, and p-values from paired t-tests); the hyperparameter search procedure and ranges; the number of independent runs (five runs with different random seeds); and controls against post-hoc selection (pre-specified metrics and reporting of all relevant outcomes). These additions will directly improve the soundness and reproducibility of the quantitative claims. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper is an empirical systems contribution whose central claims (robustness and efficiency gains) are established solely by direct experimental comparison against prior RL-based optimizers on the fixed, publicly available JOB/TPC-DS/SSB workloads. No equations, parameter-fitting steps, uniqueness theorems, or ansatzes appear in the abstract or described derivation chain; the reported 2.4×/3.1× factors are measured outcomes, not quantities defined in terms of themselves or recovered by construction from the same training data. The work therefore contains no self-definitional, fitted-input-called-prediction, or self-citation-load-bearing reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LEON: A New Framework for ML- Aided Query Optimization,
X. Chen, H. Chen, Z. Liang, S. Liu, J. Wang, K. Zeng, H. Su, and K. Zheng, “LEON: A New Framework for ML- Aided Query Optimization,”Proceedings of the VLDB Endowment, vol. 16, no. 9, pp. 2261–2273, May 2023. [Online]. Available: https://dl.acm.org/doi/10.14778/3598581.3598597
-
[2]
How good are query optimizers, really?
V . Leis, A. Gubichev, A. Mirchev, P. Boncz, A. Kemper, and T. Neumann, “How good are query optimizers, really?”Proc. VLDB Endow., vol. 9, no. 3, pp. 204–215, Nov. 2015. [Online]. Available: https://dl.acm.org/doi/10.14778/2850583.2850594 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
-
[3]
R. Marcus, P. Negi, H. Mao, C. Zhang, M. Alizadeh, T. Kraska, O. Papaemmanouil, and N. Tatbul, “Neo: A Learned Query Optimizer,” Proceedings of the VLDB Endowment, vol. 12, no. 11, pp. 1705–1718, Jul. 2019, arXiv:1904.03711 [cs]. [Online]. Available: http://arxiv.org/abs/1904.03711
-
[4]
Query optimization,
Y . E. Ioannidis, “Query optimization,”ACM Computing Surveys, vol. 28, no. 1, pp. 121–123, Mar. 1996
1996
-
[5]
Iterative dynamic programming: A new class of query optimization algorithms,
D. Kossmann and K. Stocker, “Iterative dynamic programming: A new class of query optimization algorithms,”ACM Transactions on Database Systems, vol. 25, no. 1, pp. 43–82, Mar. 2000
2000
-
[6]
Model-based Reinforcement Learning: A Survey,
T. M. Moerland, J. Broekens, A. Plaat, and C. M. Jonker, “Model-based Reinforcement Learning: A Survey,” Mar. 2022
2022
-
[7]
Learn- ing to Optimize Join Queries With Deep Reinforcement Learning,
S. Krishnan, Z. Yang, K. Goldberg, J. Hellerstein, and I. Stoica, “Learn- ing to Optimize Join Queries With Deep Reinforcement Learning,” Jan. 2019
2019
-
[8]
Towards a Hands-Free Query Optimizer through Deep Learning,
R. Marcus and O. Papaemmanouil, “Towards a Hands-Free Query Optimizer through Deep Learning,” Dec. 2018
2018
-
[9]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, ser. Adaptive Computation and Machine Learning. Cambridge, Mass: MIT Press, 1998
1998
-
[10]
Learning to predict by the methods of temporal differ- ences,
R. S. Sutton, “Learning to predict by the methods of temporal differ- ences,”Machine Learning, vol. 3, no. 1, pp. 9–44, Aug. 1988
1988
-
[11]
Bao: Making Learned Query Optimization Practical,
R. Marcus, P. Negi, H. Mao, N. Tatbul, M. Alizadeh, and T. Kraska, “Bao: Making Learned Query Optimization Practical,” in Proceedings of the 2021 International Conference on Management of Data, ser. SIGMOD ’21. New York, NY , USA: Association for Computing Machinery, Jun. 2021, pp. 1275–1288. [Online]. Available: https://dl.acm.org/doi/10.1145/3448016.3452838
-
[12]
Balsa: Learning a Query Optimizer Without Expert Demonstrations,
Z. Yang, W.-L. Chiang, S. Luan, G. Mittal, M. Luo, and I. Stoica, “Balsa: Learning a Query Optimizer Without Expert Demonstrations,” inProceedings of the 2022 International Conference on Management of Data, ser. SIGMOD ’22. New York, NY , USA: Association for Computing Machinery, Jun. 2022, pp. 931–944. [Online]. Available: https://dl.acm.org/doi/10.1145/...
-
[13]
LOGER: A Learned Optimizer Towards Generating Efficient and Robust Query Execution Plans,
T. Chen, J. Gao, H. Chen, and Y . Tu, “LOGER: A Learned Optimizer Towards Generating Efficient and Robust Query Execution Plans,”Proceedings of the VLDB Endowment, vol. 16, no. 7, pp. 1777–1789, Mar. 2023. [Online]. Available: https://dl.acm.org/doi/10. 14778/3587136.3587150
-
[14]
LIMAO: A Framework for Lifelong Modular Learned Query Optimization,
Q. Zhang, S. Xie, and I. Sabek, “LIMAO: A Framework for Lifelong Modular Learned Query Optimization,” Jun. 2025
2025
-
[15]
Glo: Towards generalized learned query optimization,
T. Chen, J. Gao, Y . Tu, and M. Xu, “Glo: Towards generalized learned query optimization,” in2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 4843–4855
2024
-
[16]
Eraser: Eliminating performance regression on learned query optimizer,
L. Weng, R. Zhu, D. Wu, B. Ding, B. Zheng, and J. Zhou, “Eraser: Eliminating performance regression on learned query optimizer,”Pro- ceedings of the VLDB Endowment, vol. 17, no. 5, pp. 926–938, 2024
2024
-
[17]
Athena: An effective learning-based framework for query optimizer performance improvement,
R. Li, Q. Li, H. Liu, R. Mao, Q. Li, and B. Tang, “Athena: An effective learning-based framework for query optimizer performance improvement,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–24, 2025
2025
-
[18]
Transfer Learning in Deep Reinforcement Learning: A Survey,
Z. Zhu, K. Lin, A. K. Jain, and J. Zhou, “Transfer Learning in Deep Reinforcement Learning: A Survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 13 344–13 362, Nov. 2023. [Online]. Available: https://ieeexplore.ieee.org/document/ 10172347/
2023
-
[19]
Towards Continual Reinforcement Learning: A Review and Perspectives,
K. Khetarpal, M. Riemer, I. Rish, and D. Precup, “Towards Continual Reinforcement Learning: A Review and Perspectives,”Journal of Arti- ficial Intelligence Research, vol. 75, pp. 1401–1476, Dec. 2022
2022
-
[20]
Self-improving reactive agents based on reinforcement learn- ing, planning and teaching,
L.-J. Lin, “Self-improving reactive agents based on reinforcement learn- ing, planning and teaching,”Machine Learning, vol. 8, no. 3, pp. 293– 321, May 1992
1992
-
[21]
Prioritized Experience Replay,
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized Experience Replay,” Feb. 2016
2016
-
[22]
Transfer Learning for Reinforcement Learning Domains: A Survey,
M. E. Taylor and P. Stone, “Transfer Learning for Reinforcement Learning Domains: A Survey,”J. Mach. Learn. Res., vol. 10, pp. 1633– 1685, 2009
2009
-
[23]
Learning to learn: Introduction and overview,
S. Thrun and L. Pratt, “Learning to learn: Introduction and overview,” inLearning to learn. Springer, 1998, pp. 3–17
1998
-
[24]
A Survey of Meta-Reinforcement Learning,
J. Beck, R. Vuorio, E. Z. Liu, Z. Xiong, L. Zintgraf, C. Finn, and S. Whiteson, “A Survey of Meta-Reinforcement Learning,” Aug. 2024
2024
-
[25]
Learning State Representations for Query Optimization with Deep Reinforcement Learning,
J. Ortiz, M. Balazinska, J. Gehrke, and S. S. Keerthi, “Learning State Representations for Query Optimization with Deep Reinforcement Learning,” inProceedings of the Second Workshop on Data Management for End-To-End Machine Learning, ser. DEEM’18. New York, NY , USA: Association for Computing Machinery, 2018, pp. 1–4
2018
-
[26]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,
C. Finn, P. Abbeel, and S. Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,” inProceedings of the 34th International Conference on Machine Learning. PMLR, Jul. 2017, pp. 1126–1135
2017
-
[27]
Generalization of Model- Agnostic Meta-Learning Algorithms: Recurring and Unseen Tasks,
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Generalization of Model- Agnostic Meta-Learning Algorithms: Recurring and Unseen Tasks,” in Advances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 5469–5480
2021
-
[28]
Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML,
A. Raghu, M. Raghu, S. Bengio, and O. Vinyals, “Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML,” Feb. 2020
2020
-
[29]
A Cluster Separation Measure,
D. L. Davies and D. W. Bouldin, “A Cluster Separation Measure,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PAMI- 1, no. 2, pp. 224–227, Apr. 1979
1979
-
[30]
An extensive comparative study of cluster validity indices,
O. Arbelaitz, I. Gurrutxaga, J. Muguerza, J. M. P ´erez, and I. Perona, “An extensive comparative study of cluster validity indices,”Pattern Recognition, vol. 46, no. 1, pp. 243–256, Jan. 2013
2013
-
[31]
Measuring Query Complexity in SQLShare Workload,
A. Vashistha and S. Jain, “Measuring Query Complexity in SQLShare Workload,” inProceedings of the 2019 International Conference on Management of Data, 2016
2019
-
[32]
H. Lan, Z. Bao, and Y . Peng, “A Survey on Advancing the DBMS Query Optimizer: Cardinality Estimation, Cost Model, and Plan Enumeration,” Jan. 2021. [Online]. Available: https://arxiv.org/abs/2101.01507v1
-
[33]
How to Distribute Data across Tasks for Meta-Learning?
A. Cioba, M. Bromberg, Q. Wang, R. Niyogi, G. Batzolis, J. Garcia, D.-s. Shiu, and A. Bernacchia, “How to Distribute Data across Tasks for Meta-Learning?”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 6, pp. 6394–6401, Jun. 2022
2022
-
[34]
FOSS: A Self-Learned Doctor for Query Optimizer,
K. Zhong, L. Sun, T. Ji, C. Li, and H. Chen, “FOSS: A Self-Learned Doctor for Query Optimizer,” in2024 IEEE 40th International Conference on Data Engineering (ICDE), May 2024, pp. 4329–4342, arXiv:2312.06357 [cs]. [Online]. Available: http: //arxiv.org/abs/2312.06357
-
[35]
TPC-DS, taking decision support benchmarking to the next level,
M. Poess, B. Smith, L. Kollar, and P. Larson, “TPC-DS, taking decision support benchmarking to the next level,” inProceedings of the 2002 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’02. New York, NY , USA: Association for Computing Machinery, 2002, pp. 582–587
2002
-
[36]
The star schema bench- mark and augmented fact table indexing,
P. O’Neil, E. O’Neil, X. Chen, and S. Revilak, “The star schema bench- mark and augmented fact table indexing,” inPerformance Evaluation and Benchmarking, R. Nambiar and M. Poess, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 237–252
2009
-
[37]
Is Your Learned Query Optimizer Behaving As You Expect? A Machine Learning Perspective,
C. Lehmann, P. Sulimov, and K. Stockinger, “Is Your Learned Query Optimizer Behaving As You Expect? A Machine Learning Perspective,” Proc. VLDB Endow., vol. 17, no. 7, pp. 1565–1577, May 2024. [Online]. Available: https://dl.acm.org/doi/10.14778/3654621.3654625
-
[38]
Why You Should Run TPC-DS: A Workload Analysis,
M. P ¨oss, R. Nambiar, and D. Walrath, “Why You Should Run TPC-DS: A Workload Analysis,” Sep. 2007. [Online]. Available: https://www.semanticscholar.org/paper/ Why-You-Should-Run-TPC-DS%3A-A-Workload-Analysis-P% C3%B6ss-Nambiar/660aa29ca30b1e73f7a85abd97496435b76e0e8d
2007
-
[39]
Variations of the star schema benchmark to test the effects of data skew on query performance,
T. Rabl, M. Poess, H.-A. Jacobsen, P. O’Neil, and E. O’Neil, “Variations of the star schema benchmark to test the effects of data skew on query performance,” inProceedings of the 4th ACM/SPEC International Conference on Performance Engineering, ser. ICPE ’13. New York, NY , USA: Association for Computing Machinery, 2013, pp. 361–372
2013
-
[40]
Learned Query Optimizer: What is New and What is Next,
R. Zhu, L. Weng, B. Ding, and J. Zhou, “Learned Query Optimizer: What is New and What is Next,” inCompanion of the 2024 International Conference on Management of Data, ser. SIGMOD/PODS ’24. New York, NY , USA: Association for Computing Machinery, Jun. 2024, pp. 561–569. [Online]. Available: https://dl.acm.org/doi/10.1145/3626246.3654692
-
[41]
Deep Reinforcement Learning for Join Order Enumeration,
R. Marcus and O. Papaemmanouil, “Deep Reinforcement Learning for Join Order Enumeration,” inProceedings of the First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, Jun. 2018, pp. 1–4, arXiv:1803.00055 [cs]. [Online]. Available: http://arxiv.org/abs/1803.00055
-
[42]
Lero: A Learning-to-Rank Query Optimizer,
R. Zhu, W. Chen, B. Ding, X. Chen, A. Pfadler, Z. Wu, and J. Zhou, “Lero: A Learning-to-Rank Query Optimizer,”Proc. VLDB Endow., vol. 16, no. 6, pp. 1466–1479, Feb. 2023. [Online]. Available: https://dl.acm.org/doi/10.14778/3583140.3583160
-
[43]
Eraser: Eliminating Performance Regression on Learned Query Optimizer,
L. Weng, R. Zhu, D. Wu, B. Ding, B. Zheng, and J. Zhou, “Eraser: Eliminating Performance Regression on Learned Query Optimizer,” Proc. VLDB Endow., vol. 17, no. 5, pp. 926–938, May 2024. [Online]. Available: https://dl.acm.org/doi/10.14778/3641204.3641205
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.