Recognition: unknown
Modeling LLM Unlearning as an Asymmetric Two-Task Learning Problem
Pith reviewed 2026-05-10 11:35 UTC · model grok-4.3
The pith
Reshaping gradient geometry, rather than re-balancing losses, mitigates the trade-off in LLM unlearning between forgetting specific knowledge and retaining general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
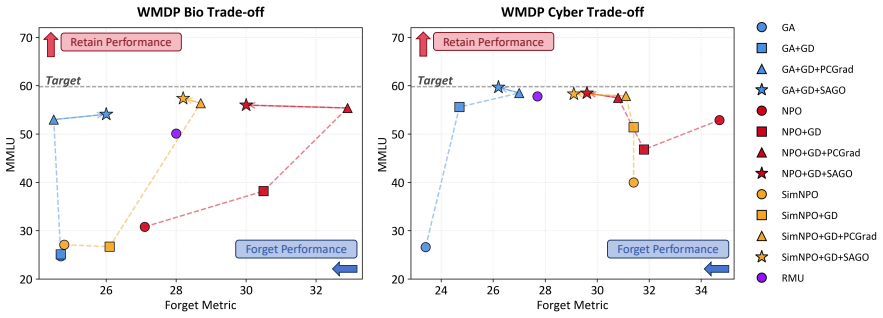
By recasting LLM unlearning as an asymmetric two-task problem with retention as the primary objective, the authors demonstrate that a gradient synthesis framework can resolve conflicts between retention and forgetting gradients. Both PCGrad and the new SAGO method guarantee non-negative cosine similarity between the synthesized gradient and the retain gradient, while SAGO further tightens alignment via sign-constrained synthesis. On WMDP benchmarks this produces superior Pareto fronts, for instance recovering 96 percent of target model MMLU performance under SimNPO+GD while maintaining forgetting strength, showing that gradient geometry reshaping outperforms simple loss re-balancing.
What carries the argument
The retention-prioritized gradient synthesis framework, which separates task-specific gradient extraction from conflict-aware combination and enforces non-negative cosine similarity with the retain gradient; SAGO is the novel sign-constrained instantiation that achieves strictly tighter alignment.
If this is right
- Unlearning procedures can be made to recover substantially more original model capability while still achieving the required forgetting level.
- Multi-task gradient conflict techniques can be directly transferred to unlearning settings once the retention task is designated primary.
- Future unlearning algorithms should prioritize geometric alignment of gradients over scalar loss weighting.
- SAGO offers a drop-in replacement for existing gradient-combination steps that yields measurable retention gains on standard benchmarks.
Where Pith is reading between the lines
- The same gradient-synthesis logic could extend to other asymmetric objectives in LLMs, such as safety alignment where a primary capability must be preserved alongside an auxiliary constraint.
- If the non-negative similarity condition proves sufficient across model scales, it may enable more parameter-efficient unlearning that avoids full retraining or heavy fine-tuning.
- The approach invites direct comparison with continual-learning methods that also seek to avoid catastrophic interference between old and new objectives.
Load-bearing premise
The assumption that gradient conflicts between retention and forgetting objectives are the dominant source of the performance trade-off and that non-negative cosine similarity with the retain gradient is sufficient to preserve capability.
What would settle it
A controlled experiment on the same WMDP Bio or Cyber benchmarks in which a loss-rebalancing baseline without any gradient synthesis achieves equivalent or better retention-forgetting Pareto performance than SAGO would falsify the claim that gradient geometry reshaping is the decisive factor.
Figures



read the original abstract
Machine unlearning for large language models (LLMs) aims to remove targeted knowledge while preserving general capability. In this paper, we recast LLM unlearning as an asymmetric two-task problem: retention is the primary objective and forgetting is an auxiliary. From this perspective, we propose a retention-prioritized gradient synthesis framework that decouples task-specific gradient extraction from conflict-aware combination. Instantiating the framework, we adapt established PCGrad to resolve gradient conflicts, and introduce SAGO, a novel retention-prioritized gradient synthesis method. Theoretically, both variants ensure non-negative cosine similarity with the retain gradient, while SAGO achieves strictly tighter alignment through constructive sign-constrained synthesis. Empirically, on WMDP Bio/Cyber and RWKU benchmarks, SAGO consistently pushes the Pareto frontier: e.g., on WMDP Bio (SimNPO+GD), recovery of target model MMLU performance progresses from 44.6% (naive) to 94.0% (+PCGrad) and further to 96.0% (+SAGO), while maintaining comparable forgetting strength. Our results show that re-shaping gradient geometry, rather than re-balancing losses, is the key to mitigating unlearning-retention trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts LLM unlearning as an asymmetric two-task problem (retention primary, forgetting auxiliary) and proposes a retention-prioritized gradient synthesis framework. It adapts PCGrad for conflict resolution and introduces SAGO, a sign-constrained synthesis method. Both ensure non-negative cosine similarity with the retain gradient (SAGO strictly tighter), with empirical results on WMDP Bio/Cyber and RWKU showing MMLU recovery gains (e.g., 44.6% naive to 96.0% +SAGO on WMDP Bio with SimNPO+GD) while preserving forgetting strength. The central claim is that reshaping gradient geometry, not loss re-balancing, mitigates the trade-off.
Significance. If the results and attribution hold, the work offers a useful reframing of unlearning via gradient geometry with concrete theoretical cosine-similarity guarantees and consistent Pareto-frontier improvements on standard benchmarks. Credit is due for the explicit non-negative alignment bounds and the reproducible-style empirical protocol on public datasets. The significance is reduced by the missing isolation of geometry from balancing, which leaves the key mechanistic claim under-supported.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): The claim that 're-shaping gradient geometry, rather than re-balancing losses, is the key' is load-bearing but unsupported by direct evidence. No ablation holds the gradient combination rule fixed while varying only the scalar loss weight λ in a baseline L = L_retain + λ L_forget (with grid search on λ) to produce a comparable Pareto curve. The reported gains (WMDP Bio row: naive 44.6% → +PCGrad 94.0% → +SAGO 96.0%) are measured against a naive joint-optimization baseline that may already embed implicit balancing, so the attribution to geometry remains unisolated.
- [§3 and §4] §3 (Method) and §4 (Theory): The framework assumes gradient conflicts (negative cosine similarity between retain and forget gradients) are the dominant source of the trade-off and that enforcing non-negative cosine similarity is sufficient to preserve capability. While Theorem 1 and the PCGrad/SAGO constructions guarantee non-negative alignment, the paper provides no diagnostic (e.g., correlation between achieved cosine similarity and downstream MMLU recovery across runs) to confirm this is the primary mechanism rather than magnitude or higher-order effects.
minor comments (2)
- [§5.2] §5.2: Table captions should explicitly state the exact loss formulation and hyper-parameters used for the 'naive' baseline to allow direct reproduction.
- [§3] Notation: The distinction between g_r (retain gradient) and g_f (forget gradient) is introduced late; early standardization in §3 would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major comment below and will revise the manuscript to incorporate additional ablations and diagnostics that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [Abstract and §5] The claim that 're-shaping gradient geometry, rather than re-balancing losses, is the key' is load-bearing but unsupported by direct evidence. No ablation holds the gradient combination rule fixed while varying only the scalar loss weight λ in a baseline L = L_retain + λ L_forget (with grid search on λ) to produce a comparable Pareto curve. The reported gains (WMDP Bio row: naive 44.6% → +PCGrad 94.0% → +SAGO 96.0%) are measured against a naive joint-optimization baseline that may already embed implicit balancing, so the attribution to geometry remains unisolated.
Authors: We agree that isolating the effect of gradient geometry from loss re-balancing requires a direct comparison against an optimized scalar weighting. Our current naive baseline uses the conventional fixed λ=1, which is standard in the literature but not necessarily optimal. To address this, we will add a new ablation in the revised §5 that performs a grid search over λ for the naive joint-optimization baseline and plots the resulting Pareto curves alongside PCGrad and SAGO on the WMDP Bio and Cyber benchmarks. This will allow readers to see whether geometry-based synthesis still yields gains beyond the best achievable loss balancing. revision: yes
-
Referee: [§3 and §4] The framework assumes gradient conflicts (negative cosine similarity between retain and forget gradients) are the dominant source of the trade-off and that enforcing non-negative cosine similarity is sufficient to preserve capability. While Theorem 1 and the PCGrad/SAGO constructions guarantee non-negative alignment, the paper provides no diagnostic (e.g., correlation between achieved cosine similarity and downstream MMLU recovery across runs) to confirm this is the primary mechanism rather than magnitude or higher-order effects.
Authors: We concur that a direct diagnostic linking achieved cosine similarity to capability recovery would strengthen the mechanistic interpretation. Although the theoretical guarantees and consistent empirical improvements support the role of alignment, we did not report such a correlation. In the revision we will add a diagnostic analysis (new figure or table in §5) that computes and correlates the cosine similarity between the synthesized gradient and the retain gradient with MMLU recovery across methods and random seeds. This will help verify whether alignment is the primary driver or whether magnitude and higher-order effects also contribute. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper recasts unlearning as an asymmetric two-task problem and constructs a retention-prioritized gradient synthesis framework from this perspective, adapting the external PCGrad method and introducing the novel SAGO synthesis rule. Theoretical guarantees on non-negative cosine similarity are derived directly from the proposed sign-constrained combination rule rather than being presupposed, and empirical Pareto improvements on WMDP/RWKU benchmarks are reported as independent measurements. No equations reduce a claimed prediction to a fitted input by construction, no load-bearing uniqueness theorem is imported via self-citation, and the central attribution to gradient geometry reshaping rests on the new synthesis construction rather than renaming or re-deriving prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient conflicts between retention and forgetting objectives are the primary cause of performance degradation in LLM unlearning
Forward citations
Cited by 1 Pith paper
-
Representation-Guided Parameter-Efficient LLM Unlearning
REGLU guides LoRA-based unlearning via representation subspaces and orthogonal regularization to outperform prior methods on forget-retain trade-off in LLM benchmarks.
Reference graph
Works this paper leans on
-
[1]
IEEE. Zhao Chen, Jiquan Ngiam, Yanping Huang, Thang Luong, Henrik Kretzschmar, Yuning Chai, and Dragomir Anguelov. 2020. Just pick a sign: Op- timizing deep multitask models with gradient sign dropout.Advances in Neural Information Processing Systems, 33:2039–2050. 9 Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha ...
-
[2]
Model merging in llms, mllms, and beyond: Methods, theories, applica- tions and opportunities,
Distract large language models for automatic jailbreak attack. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pages 16230–16244, Miami, Florida, USA. Association for Computational Linguistics. Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. 2023. Ties-merging: Re- solving interfere...
-
[3]
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher.Preprint, arXiv:2308.06463. Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. 2024. Negative preference optimization: From catastrophic collapse to effective unlearning.arXiv preprint arXiv:2404.05868. Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrik- son. 2023. Universal and transferable...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.