Recognition: unknown
Nautilus: An Auto-Scheduling Tensor Compiler for Efficient Tiled GPU Kernels
Pith reviewed 2026-05-10 10:18 UTC · model grok-4.3
The pith
Nautilus automatically converts high-level algebraic tensor descriptions into efficient tiled GPU kernels without manual tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
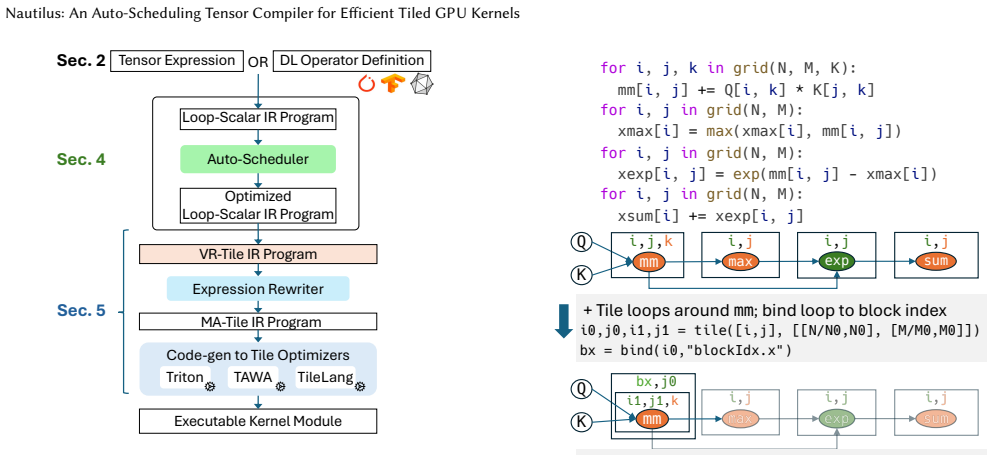
Nautilus compiles high-level algebraic specifications of tensor operators into efficient tiled GPU kernels through successive lowering that jointly applies high-level optimizations, expression rewrites, and tile optimizations; its novel auto-scheduler discovers sequences of high-level optimizations that preserve the regular program structure required by tile optimizers while capturing complex interactions such as advanced reduction fusion, making it the first end-to-end system able to start from a math-like description of attention and automatically discover FlashAttention-3-like kernels.
What carries the argument
The successive lowering pipeline together with an auto-scheduler that enumerates high-level optimization sequences while maintaining structure compatible with downstream tile optimizers.
Load-bearing premise
The auto-scheduler can reliably discover sequences of high-level optimizations that both keep the program structure regular for tile optimizers and incorporate complex global transformations like advanced reduction fusion.
What would settle it
Compile a standard mathematical description of multi-head attention with Nautilus and observe that the generated kernel is either slower than a manually tuned FlashAttention-3 implementation or fails to apply the expected fusion and tiling patterns on the same GPU.
Figures





read the original abstract
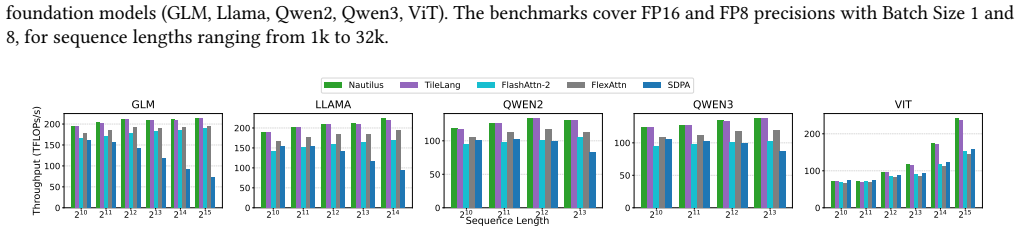
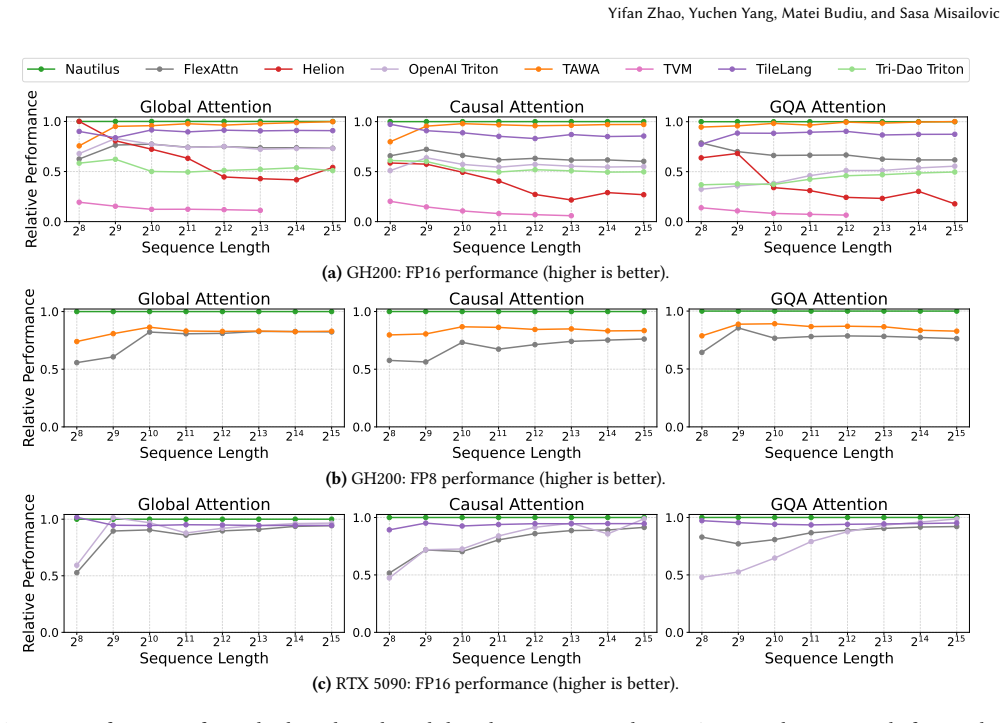
We present Nautilus, a novel tensor compiler that moves toward fully automated math-to-kernel optimization. Nautilus compiles a high-level algebraic specification of tensor operators into efficient tiled GPU kernels. Nautilus's successive lowering design allows high-level optimizations, expression rewrites, and tile optimizations to be jointly applied in a single end-to-end system. Nautilus presents a novel auto-scheduler that discovers sequences of high-level optimizations, while preserving the regular program structure needed by tile optimizers. Nautilus's auto-scheduler captures complex interactions and trade-offs in the high-level optimizations, including aggressive global transformations like advanced reduction fusion. Nautilus is the first end-to-end tensor compiler capable of starting from a math-like description of attention and automatically discovering FlashAttention-3-like kernels, offloading the entire burden of optimization from the programmer to the compiler. Across five transformer-based models and 150 evaluation configurations on NVIDIA GH200 and RTX 5090 GPUs, Nautilus achieves up to 23% higher throughput than state-of-the-art compilers on GH200 and up to 42% on RTX 5090, while matching or exceeding manually written cuDNN kernels on many long-sequence configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Nautilus, a tensor compiler that compiles high-level algebraic specifications of tensor operators into efficient tiled GPU kernels using successive lowering. It features a novel auto-scheduler that discovers sequences of high-level optimizations, including aggressive global transformations like advanced reduction fusion, while preserving regular program structure for tile optimizers. Nautilus claims to be the first end-to-end system to automatically discover FlashAttention-3-like kernels from a math-like description of attention, and reports up to 23% higher throughput than SOTA compilers on GH200 and 42% on RTX 5090, matching or exceeding cuDNN on many configurations across five transformer models and 150 setups.
Significance. If the results hold, Nautilus would mark a notable step toward fully automated math-to-kernel optimization for complex tensor operations in ML, potentially reducing reliance on expert-written kernels like cuDNN and FlashAttention. The joint application of high-level rewrites and tile optimizations in one framework could influence future tensor compiler designs, especially for attention mechanisms in transformers.
major comments (2)
- [Evaluation] The abstract and evaluation report concrete throughput gains (23% on GH200, 42% on RTX 5090) but provide no methodology details, error bars, ablation studies, or search traces showing how the auto-scheduler discovers the FlashAttention-3-like kernels from the high-level attention specification (QK^T, softmax, SV). This undermines the central claim that the entire optimization burden is offloaded to the compiler.
- [Auto-scheduler description] The novel auto-scheduler is asserted to capture complex interactions such as advanced reduction fusion while preserving tile-friendly structure, but no example derivation trace, search-space definition, or cost-model details are provided to demonstrate this capability on the attention case.
minor comments (1)
- The paper would benefit from clearer notation or diagrams illustrating the successive lowering process from math spec to tiled kernel.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of Nautilus. We address each major comment below and will incorporate the requested details and examples in the revised manuscript to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Evaluation] The abstract and evaluation report concrete throughput gains (23% on GH200, 42% on RTX 5090) but provide no methodology details, error bars, ablation studies, or search traces showing how the auto-scheduler discovers the FlashAttention-3-like kernels from the high-level attention specification (QK^T, softmax, SV). This undermines the central claim that the entire optimization burden is offloaded to the compiler.
Authors: We agree that additional methodological details are needed to fully substantiate the central claim. In the revision we will expand the evaluation section with: a precise description of the measurement methodology and hardware setup; error bars computed from repeated runs; ablation studies that isolate the impact of the auto-scheduler and high-level rewrites; and an explicit search trace (or derivation example) for the attention operator that starts from the mathematical specification (QK^T, softmax, SV) and shows the sequence of optimizations discovered by the scheduler. These additions will directly support the assertion that the optimization burden is offloaded to the compiler. revision: yes
-
Referee: [Auto-scheduler description] The novel auto-scheduler is asserted to capture complex interactions such as advanced reduction fusion while preserving tile-friendly structure, but no example derivation trace, search-space definition, or cost-model details are provided to demonstrate this capability on the attention case.
Authors: We concur that concrete illustrations would make the auto-scheduler's behavior clearer. We will add to the manuscript: a step-by-step derivation trace for the attention case that exhibits advanced reduction fusion and other high-level transformations; a formal definition of the search space explored by the scheduler; and details of the cost model used to rank candidate sequences while ensuring the resulting program remains amenable to tile-level optimizations. These elements will demonstrate the claimed capability without altering the reported performance results. revision: yes
Circularity Check
No circularity: empirical systems results stand independently of any self-referential derivation.
full rationale
The paper's core contribution is an implemented tensor compiler whose performance claims rest on direct throughput measurements across five models and 150 configurations, compared against external baselines (cuDNN, other compilers). No equations, fitted parameters, or first-principles derivations are presented that could reduce to their own inputs. The auto-scheduler is described as novel but its behavior is validated experimentally rather than asserted via self-citation chains, uniqueness theorems, or ansatzes imported from prior author work. The evaluation is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irv- ing, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: A System f...
2016
-
[2]
Andrew Adams, Karima Ma, Luke Anderson, Riyadh Baghdadi, Tzu- Mao Li, Michaël Gharbi, Benoit Steiner, Steven Johnson, Kayvon Fata- halian, Frédo Durand, and Jonathan Ragan-Kelley. 2019. Learning to optimize halide with tree search and random programs.ACM Trans. Graph.38, 4, Article 121 (July 2019), 12 pages. doi:10.1145/3306346.33 22967
-
[3]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. InSC ’22: Proceedings of the International Conference for High Performance Computing, N...
-
[4]
Riyadh Baghdadi, Jessica Ray, Malek Ben Romdhane, Emanuele Del Sozzo, Abdurrahman Akkas, Yunming Zhang, Patricia Suriana, Shoaib Kamil, and Saman Amarasinghe. 2019. Tiramisu: A Polyhedral Com- piler for Expressing Fast and Portable Code. In2019 IEEE/ACM In- ternational Symposium on Code Generation and Optimization (CGO). 193–205. doi:10.1109/CGO.2019.8661197
-
[5]
Jonathan Bentz and Tony Scudiero. 2025. Simplify GPU Programming with NVIDIA CUDA Tile in Python.https://developer.nvidia.com/b log/simplify-gpu-programming-with-nvidia-cuda-tile-in-python/. NVIDIA Technical Blog
2025
-
[6]
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. 2023. AudioLM: a Language Modeling Approach to Audio Generation. arXiv:2209.03143 [cs.SD]https://arxiv.org/abs/2209.03143
-
[7]
Hongzheng Chen, Bin Fan, Alexander Collins, Bastian Hagedorn, Evghenii Gaburov, Masahiro Masuda, Matthew Brookhart, Chris Sul- livan, Jason Knight, Zhiru Zhang, and Vinod Grover. 2025. Tawa: Automatic Warp Specialization for Modern GPUs with Asynchronous References. arXiv:2510.14719 [cs.LG]https://arxiv.org/abs/2510.14719
-
[8]
Available: https://doi.org/10.48550/arXiv.1802.04799
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Haichen Shen, Eddie Q. Yan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. TVM: End-to-End Optimization Stack for Deep Learning.CoRRabs/1802.04799 (2018). arXiv:1802.04799http://arxiv. org/abs/1802.04799
-
[9]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Paral- lelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[10]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[11]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
-
[12]
Tri Dao, Grigory Sizov, Francisco Massa, and Daniel Haziza. 2023. Flash-decoding for long-context inference.https://pytorch.org/blog /flash-decoding/
2023
-
[13]
Dao-AILab. 2023. FlashAttention.https://github.com/Dao-AILab/flas h-attention
2023
-
[14]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale. arXiv:2010.11929 [cs.CV] https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [15]
-
[16]
Huawei Technologies Co. Ltd. 2020. AKG: Automatic Kernel Genera- tion in MindSpore. MindSpore Auto Kernel Generator (AKG) compiler documentation.https://www.mindspore.cn, accessed 2025-12-09
2020
-
[17]
Google JAX Authors. 2024. Pallas: a JAX kernel language.https: //docs.jax.dev/en/latest/pallas/index.html
2024
-
[18]
Zhihao Jia, Oded Padon, James Thomas, Todd Warszawski, Matei Za- haria, and Alex Aiken. 2019. TASO: optimizing deep learning computa- tion with automatic generation of graph substitutions. InProceedings of the 27th ACM Symposium on Operating Systems Principles. 47–62
2019
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[20]
Efficient memory management for large language model serving with pagedattention
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP ’23). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3600006.3613165 Nautilus: An Auto-Scheduling Tensor Compiler for Efficient Tiled GPU Kernels
-
[21]
Alameldeen, Marco Guarnieri, Mark Silberstein, Oleksii Oleksenko, and Gururaj Saileshwar
Ruihang Lai, Junru Shao, Siyuan Feng, Steven Lyubomirsky, Bohan Hou, Wuwei Lin, Zihao Ye, Hongyi Jin, Yuchen Jin, Jiawei Liu, Lesheng Jin, Yaxing Cai, Ziheng Jiang, Yong Wu, Sunghyun Park, Prakalp Srivastava, Jared Roesch, Todd C. Mowry, and Tianqi Chen. 2025. Relax: Composable Abstractions for End-to-End Dynamic Machine Learning. InProceedings of the 30t...
- [22]
-
[23]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vain- brand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. arXiv:2104.04473 [cs.CL]https://arxiv.org/abs/2104.04473
-
[24]
John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. 2008. Scalable Parallel Programming with CUDA. ACM SIGGRAPH.https: //dl.acm.org/doi/abs/10.1145/1401132.1401152
-
[25]
NVIDIA. 2019. FasterTransformer: A Fast Transformer Library for Inference.https://github.com/NVIDIA/FasterTransformer
2019
-
[26]
NVIDIA. 2021. CUTLASS: CUDA Templates for Linear Algebra Sub- routines.https://github.com/NVIDIA/cutlass
2021
-
[27]
NVIDIA. 2023. TensorRT-LLM: TensorRT Library for Optimized Large Language Model Inference.https://github.com/NVIDIA/TensorRT- LLM
2023
-
[28]
OpenAI. 2024. Fused Attention – Triton Documentation.https://triton- lang.org/main/getting-started/tutorials/06-fused-attention.html
2024
-
[29]
OpenAI. 2025. GPT-5 System Card.https://cdn.openai.com/gpt-5- system-card.pdf
2025
-
[30]
OpenXLA. [n. d.]. XLA.https://openxla.org/xla.https://openxla.org/ xla
-
[31]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural informa- tion processing systems32 (2019), 8026–8037
2019
-
[32]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: A Lan- guage and Compiler for Optimizing Parallelism, Locality, and Recom- putation in Image Processing Pipelines. InACM SIGPLAN Conference on Programming Language Design and Implementation(Seattle, Wash- ington, USA)(PLDI ’13). Associat...
-
[33]
Nadav Rotem, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein, Jack Montgomery, Bert Maher, Satish Nadathur, Jakob Olesen, Jongsoo Park, Artem Rakhov, Misha Smelyanskiy, and Man Wang. 2018. Glow: Graph Lowering Compiler Techniques for Neural Networks.arXiv preprint arXiv...
work page Pith review arXiv 2018
-
[34]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2022. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv:2205.11487 [cs.CV]https://arxi...
work page internal anchor Pith review arXiv 2022
- [35]
-
[36]
Junru Shao, Xiyou Zhou, Siyuan Feng, Bohan Hou, Ruihang Lai, Hongyi Jin, Wuwei Lin, Masahiro Masuda, Cody Hao Yu, and Tianqi Chen. 2022. Tensor Program Optimization with Probabilistic Programs. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., ...
2022
-
[37]
Thunderkittens: Simple, fast, and adorable ai kernels.arXiv preprint arXiv:2410.20399, 2024
Benjamin F. Spector, Simran Arora, Aaryan Singhal, Daniel Y. Fu, and Christopher Ré. 2024. ThunderKittens: Simple, Fast, and Adorable AI Kernels. arXiv:2410.20399 [cs.LG]https://arxiv.org/abs/2410.20399
-
[38]
Michel Steuwer, Toomas Remmelg, and Christophe Dubach. 2017. Lift: A Functional Data-Parallel IR for High-Performance GPU Code Gen- eration. InCGO 2017: Proceedings of the 2017 International Symposium on Code Generation and Optimization. IEEE, 74–85. doi:10.1109/CGO. 2017.7863730
work page doi:10.1109/cgo 2017
-
[39]
Philippe Tillet, H. T. Kung, and David Cox. 2019. Triton: an interme- diate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. ACM, Phoenix AZ USA, 10–19. doi:10.1145/3315508.3329973
-
[40]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [41]
-
[42]
Max Willsey, Chandrakana Nandi, Yisu Remy Wang, Oliver Flatt, Zachary Tatlock, and Pavel Panchekha. 2021. egg: Fast and Exten- sible Equality Saturation.Proceedings of the ACM on Programming Languages5, POPL, Article 23 (2021), 29 pages. doi:10.1145/3434304
-
[43]
Mengdi Wu, Xinhao Cheng, Shengyu Liu, Chunan Shi, Jianan Ji, Man Kit Ao, Praveen Velliengiri, Xupeng Miao, Oded Padon, and Zhihao Jia. 2025. Mirage: A {Multi-Level} Superoptimizer for Tensor Programs. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). 21–38
2025
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guant- ing Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Kem- ing Lu, Keqin Chen, Kexin Yang,...
work page internal anchor Pith review arXiv 2024
- [46]
-
[47]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Cus- tomizable Attention Engine for LLM Inference Serving.arXiv preprint arXiv:2501.01005(2025).https://arxiv.org/abs/2501.01005
-
[48]
Bozhi You, Irene Wang, Zelal Su Mustafaoglu, Abhinav Jangda, Angélica Moreira, Roshan Dathathri, Divya Mahajan, and Keshav Pingali. 2026. Flashlight: PyTorch Compiler Extensions to Acceler- ate Attention Variants.Proceedings of Machine Learning and Systems (2026)
2026
- [49]
-
[50]
Yifan Zhao, Egan Johnson, Prasanth Chatarasi, Vikram Adve, and Sasa Misailovic. 2026. Neptune: Advanced ML Operator Fusion for Locality and Parallelism on GPUs. InACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI’26)
2026
-
[51]
Gonzalez, and Ion Stoica
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, Joseph E. Gonzalez, and Ion Stoica. 2020. Ansor: Generating High-Performance Tensor Programs for Deep Learning. InUSENIX Conference on Operating Systems Design and Implementation (OSDI’20). USENIX Association, USA, Article 49, 17 pages
2020
-
[52]
Size Zheng, Yun Liang, Shuo Wang, Renze Chen, and Kaiwen Sheng
-
[53]
FlexTensor: An Automatic Schedule Exploration and Optimiza- tion Framework for Tensor Computation on Heterogeneous System. InProceedings of the Twenty-Fifth International Conference on Archi- tectural Support for Programming Languages and Operating Systems (Lausanne, Switzerland)(ASPLOS ’20). Association for Computing Ma- chinery, New York, NY, USA, 859–8...
-
[54]
Zhen Zheng, Zaifeng Pan, Dalin Wang, Kai Zhu, Wenyi Zhao, Tianyou Guo, Xiafei Qiu, Minmin Sun, Junjie Bai, Feng Zhang, Xiaoyong Du, Jidong Zhai, and Wei Lin. 2023. BladeDISC: Optimizing Dynamic Shape Machine Learning Workloads via Compiler Approach.Proc. ACM Manag. Data1, 3, Article 206 (Nov. 2023), 29 pages. doi:10.1145/ 3617327 Nautilus: An Auto-Schedul...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.