Recognition: unknown
Does RL Expand the Capability Boundary of LLM Agents? A PASS@(k,T) Analysis
Pith reviewed 2026-05-10 11:47 UTC · model grok-4.3
The pith
Reinforcement learning expands the capability boundary of LLM agents on compositional tool-use tasks, unlike on static reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tool-use RL genuinely enlarges the capability boundary: the RL agent's pass-curve pulls above the base model's and the gap widens at large k rather than converging. This expansion is specific to compositional, sequential information gathering. Under matched training data, supervised fine-tuning regresses the boundary on the same tasks, isolating self-directed exploration as the causal factor. Mechanism analysis shows RL reweights the base strategy distribution toward the subset whose downstream reasoning more often yields a correct answer, with the improvement concentrated on how the agent integrates retrieved information.
What carries the argument
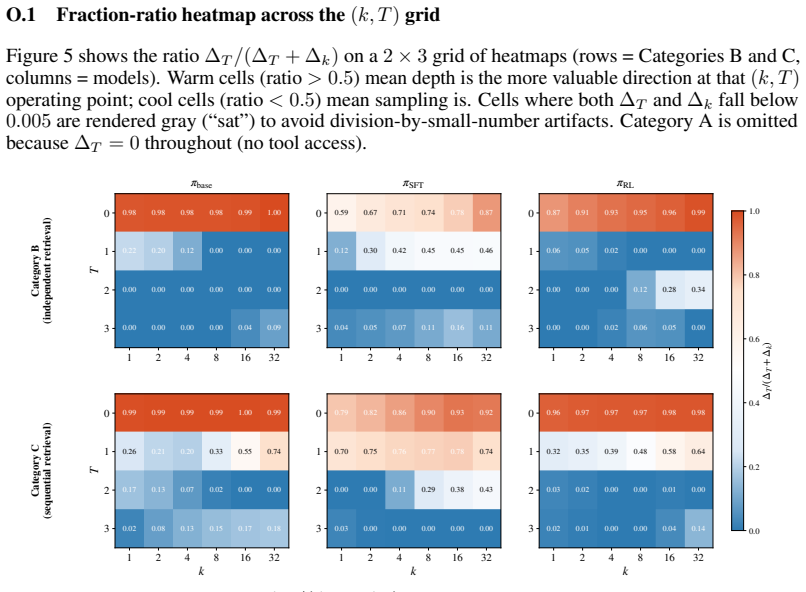
The PASS@(k,T) metric that jointly varies sampling budget k and interaction depth T, separating capability expansion from efficiency improvement.
If this is right
- On compositional tool-use tasks the RL pass curve stays strictly above the base curve and the separation grows rather than shrinks with more samples.
- Supervised fine-tuning on identical data lowers the boundary on those same tasks.
- The RL gain is concentrated in better integration of information retrieved across rounds rather than broader exploration.
- On simpler non-compositional tasks the RL and base curves behave as in prior static-reasoning studies.
Where Pith is reading between the lines
- The metric suggests future agent benchmarks should report families of curves rather than single points to distinguish capability from reliability.
- If the pattern generalizes, scaling laws for agent performance may require separate terms for RL-induced strategy reweighting.
- The finding opens the possibility that self-directed exploration during training discovers integration patterns that imitation alone cannot.
Load-bearing premise
The chosen tasks accurately represent compositional sequential information gathering and matched training data comparisons isolate self-directed exploration without other confounding differences in behavior or task distribution.
What would settle it
Observing that the RL and base-model pass curves converge at sufficiently large k on the same compositional tasks, or that supervised fine-tuning produces equivalent boundary expansion under matched data.
Figures








read the original abstract
Does reinforcement learning genuinely expand what LLM agents can do, or merely make them more reliable? For static reasoning, recent work answers the second: base and RL pass@k curves converge at large k. We ask whether this holds for agentic tool use, where T rounds of interaction enable compositional strategies that re-sampling cannot recover. We introduce PASS@(k,T), a two-dimensional metric that jointly varies sampling budget k and interaction depth T, separating capability expansion from efficiency improvement. Our main finding is that, contrary to the static-reasoning result, tool-use RL genuinely enlarges the capability boundary: the RL agent's pass-curve pulls above the base model's and the gap widens at large k rather than converging. The expansion is specific to compositional, sequential information gathering; on simpler tasks RL behaves as prior work predicts. Under matched training data, supervised fine-tuning regresses the boundary on the same compositional tasks, isolating self-directed exploration as the causal factor. Mechanism analysis shows RL reweights the base strategy distribution toward the subset whose downstream reasoning more often yields a correct answer, with the improvement concentrated on how the agent integrates retrieved information. These results reconcile optimistic and pessimistic readings of RL for LLMs: both are correct, on different task types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PASS@(k,T), a metric jointly varying sampling budget k and interaction depth T, to distinguish capability expansion from efficiency gains in LLM agents. It claims that unlike static reasoning (where base and RL pass@k curves converge), tool-use RL on compositional sequential tasks enlarges the capability boundary: the RL agent's PASS@(k,T) curve lies above the base model's with a widening gap at large k. This effect is absent on simpler tasks; under matched data, SFT regresses the boundary, isolating self-directed exploration; mechanism analysis attributes gains to reweighting toward strategies with better downstream reasoning.
Significance. If the central empirical contrast holds, the work would be significant for clarifying when RL expands versus merely stabilizes LLM agent performance. The PASS@(k,T) framing offers a concrete way to test boundary expansion in interactive settings, the SFT control isolates exploration as causal, and the task-type specificity reconciles optimistic/pessimistic RL views. The paper ships a falsifiable prediction (non-convergence on compositional tasks) and an explicit mechanism claim, both of which are valuable even if the finite-k evidence requires strengthening.
major comments (2)
- [Results / PASS@(k,T) analysis] Results section on PASS@(k,T) curves for compositional tasks: the headline claim that 'the gap widens at large k rather than converging' and thereby 'genuinely enlarges the capability boundary' rests on curves observed only up to a finite maximum k. If the RL and base models share the same support of successful trajectories, the curves are required to converge as k→∞; the reported separation could be a finite-sample artifact. The manuscript should either (a) report the largest k tested and show the gap is still increasing, (b) provide an argument or extrapolation that the k→∞ limits differ, or (c) demonstrate that RL changes the support itself.
- [Experimental setup] Experimental setup and task definitions: the claim that the effect is 'specific to compositional, sequential information gathering' requires precise, reproducible definitions of the task suite, how 'compositional' is operationalized, and the exact training-data matching procedure between RL and SFT. Without these, it is impossible to rule out post-hoc task selection or confounding differences in model behavior as the source of the observed divergence.
minor comments (3)
- [Abstract and Figures] The abstract and main text should explicitly state the maximum k and T values used in the reported curves and whether error bars or multiple seeds are shown.
- [Methods] Notation: PASS@(k,T) is introduced as a two-dimensional metric, but the precise mathematical definition (especially how T-interaction paths are sampled and aggregated) should appear in a dedicated methods subsection before the results.
- [Mechanism analysis] The mechanism analysis (reweighting toward better downstream reasoning) would benefit from a quantitative breakdown, e.g., a table showing the fraction of probability mass shifted to high-performing trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of the PASS@(k,T) metric in distinguishing capability expansion from efficiency gains. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: Results section on PASS@(k,T) curves for compositional tasks: the headline claim that 'the gap widens at large k rather than converging' rests on curves observed only up to a finite maximum k. If the RL and base models share the same support of successful trajectories, the curves are required to converge as k→∞; the reported separation could be a finite-sample artifact. The manuscript should either (a) report the largest k tested and show the gap is still increasing, (b) provide an argument or extrapolation that the k→∞ limits differ, or (c) demonstrate that RL changes the support itself.
Authors: We agree this is a substantive point. Our experiments evaluate up to k=128 on the compositional tasks, where the gap between RL and base continues to widen without signs of convergence. To strengthen the claim, we will add (a) explicit reporting of the maximum k tested with the corresponding curves, and (c) a clearer argument that RL changes the support: self-directed exploration during RL enables new compositional trajectories (sequential tool-use strategies) that lie outside the base model's support even at large k, as evidenced by our mechanism analysis showing reweighting toward strategies with superior downstream reasoning integration. This is consistent with the non-convergence prediction for compositional tasks. We will include this in the revised Results section. revision: partial
-
Referee: Experimental setup and task definitions: the claim that the effect is 'specific to compositional, sequential information gathering' requires precise, reproducible definitions of the task suite, how 'compositional' is operationalized, and the exact training-data matching procedure between RL and SFT. Without these, it is impossible to rule out post-hoc task selection or confounding differences in model behavior as the source of the observed divergence.
Authors: We agree that explicit definitions are essential for reproducibility. Section 3.1 defines the task suite with concrete examples: compositional tasks require sequential, dependent tool calls (e.g., using the output of one tool as input to the next in information-gathering chains), while simpler tasks involve independent or single-step actions. 'Compositional' is operationalized via dependency graphs in the task construction. The RL-SFT data matching procedure (same trajectory pool, with SFT using supervised imitation and RL using self-exploration) is detailed in Appendix B. We will move key excerpts of these definitions into the main text and add a table summarizing task properties to eliminate any ambiguity. revision: yes
Circularity Check
No circularity: empirical curve comparison is independent of fitted inputs
full rationale
The paper defines PASS@(k,T) directly from sampling budget k and interaction depth T, then reports experimental outcomes on independently trained base, RL, and SFT models evaluated on the same tasks. No derivation step equates a claimed result to its own inputs by construction, renames a fitted quantity as a prediction, or relies on a self-citation whose content is itself unverified. The non-convergence observation and mechanism analysis are post-hoc interpretations of measured pass rates, not definitional reductions. The work is self-contained against external benchmarks and receives the default low-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-k pass rates on the evaluated tasks represent the model's true capability boundary rather than sampling artifacts.
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y ., et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Brown, B., et al. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review arXiv
-
[3]
Evaluating Large Language Models Trained on Code
Chen, M., et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2508.04652 , year=
Liu, S., et al. LLM collaboration with multi-agent reinforcement learning.arXiv preprint arXiv:2508.04652,
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Feng, J., et al. ReTool: Reinforcement learning for strategic tool use in LLMs.arXiv preprint arXiv:2504.11536,
work page internal anchor Pith review arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Jin, B., et al. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
-
[9]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., et al. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review arXiv
-
[10]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
Gorilla: Large Language Model Connected with Massive APIs
Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
work page internal anchor Pith review arXiv
-
[13]
Putta, P., et al. Agent Q: Advanced reasoning and learning for autonomous AI agents.arXiv preprint arXiv:2408.07199,
-
[14]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
-
[17]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Solving math word problems with process- and outcome-based feedback
Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review arXiv
-
[20]
Zheng, L., et al. GPT-Fathom: Benchmarking large language models to decipher the evolutionary path towards GPT-4 and beyond.arXiv preprint arXiv:2309.16583,
-
[21]
These works target higher benchmark scores under a single reward-weighted objective but do not decompose the observed improvements into capability vs
12 A Related Work RL for LLM agents and tool use.End-to-end RL over multi-turn tool-use trajectories is a rapidly growing family that includes Agent-R1 [Cheng et al., 2025], ReTool [Feng et al., 2025], Agent-Q [Putta et al., 2024], Search-R1 [Jin et al., 2025], and MAGRPO [Liu et al., 2025b]. These works target higher benchmark scores under a single rewar...
2025
-
[22]
Observation
use this lens to argue that RL on verifiable rewards (RLVR) for mathematical reasoning does not enlarge the base model’s capability set: at large k, base and RL pass@k curves converge. Holistic evaluation frameworks [Liang et al., 2023, Srivastava et al., 2023] and compositional benchmarks [Trivedi et al., 2022, Khot et al., 2023] have broadened the evalu...
2023
-
[23]
Write PASS@(k, T) using the unbiased hypergeometric estimator (Def
Proof. Write PASS@(k, T) using the unbiased hypergeometric estimator (Def. 1): 1− n−cT k / n k . Fix T . Since n−cT k / n k is monotone non-increasing in k for fixed cT (this is the standard pass@k monotonicity), PASS@(k, T) is non-decreasing in k. Now fix k. Any trajectory τ that terminates with the correct answer after at most T1 interaction rounds is a...
2021
-
[24]
The data-generation, checkpointing, and evaluation infrastructure is already in place; the extensions require only additional compute, and we will include them in a revised version
These robustness checks, particularly the temperature sweep, which controls for the possibility that RL training mechanically lowers the output entropy and thereby inflates PASS@(1,T) while deflating PASS@(64,T), are the most important next runs. The data-generation, checkpointing, and evaluation infrastructure is already in place; the extensions require ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.