Recognition: unknown
FSDETR: Frequency-Spatial Feature Enhancement for Small Object Detection
Pith reviewed 2026-05-10 11:44 UTC · model grok-4.3
The pith
FSDETR improves small-object detection by fusing frequency filtering with spatial attention in a lightweight DETR model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
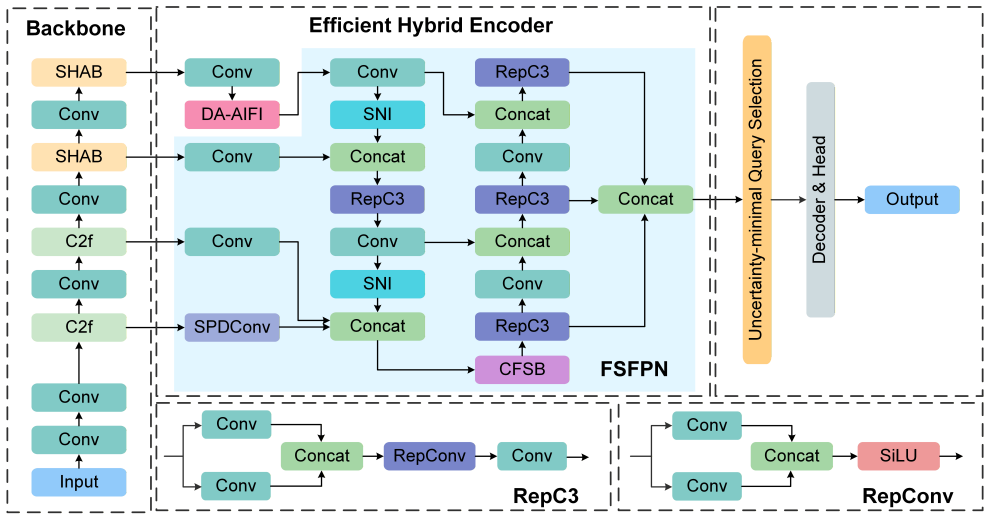
FSDETR establishes a collaborative frequency-spatial modeling mechanism on the RT-DETR backbone in which the Spatial Hierarchical Attention Block captures both local details and global dependencies, the Deformable Attention-based Intra-scale Feature Interaction module performs dynamic sampling to reduce occlusion effects, and the Frequency-Spatial Feature Pyramid Network uses Cross-domain Frequency-Spatial Blocks to combine frequency filtering with spatial edge extraction, thereby preserving fine-grained information needed for small objects.
What carries the argument
The Cross-domain Frequency-Spatial Block (CFSB) inside the Frequency-Spatial Feature Pyramid Network (FSFPN), which jointly applies frequency-domain filtering and spatial-domain edge extraction to retain small-object details that downsampling would otherwise discard.
If this is right
- Small-object accuracy rises on aerial imagery (VisDrone) and pedestrian imagery (TinyPerson) while parameter count stays low.
- Occlusion handling improves through dynamic, region-specific sampling rather than uniform attention.
- Fine details survive downsampling because frequency and spatial cues reinforce each other in the feature pyramid.
- The same lightweight backbone can be used in resource-constrained settings that previously required heavier detectors.
Where Pith is reading between the lines
- The frequency-domain path may confer extra robustness to lighting changes or sensor noise that the current benchmarks do not stress.
- The modular block design could be transferred to other transformer detectors to address similar small-object problems without redesigning the entire architecture.
- Further tests on datasets with different scales or modalities would reveal whether the reported gains are specific to the two chosen benchmarks.
Load-bearing premise
The three proposed blocks supply genuinely complementary structural information that improves small-object performance rather than simply increasing model capacity or fitting the chosen benchmarks.
What would settle it
An ablation or capacity-matched baseline experiment in which removing any one of the SHAB, DA-AIFI, or CFSB blocks produces no gain, or a loss, in APS on VisDrone 2019 compared with the unmodified RT-DETR.
Figures



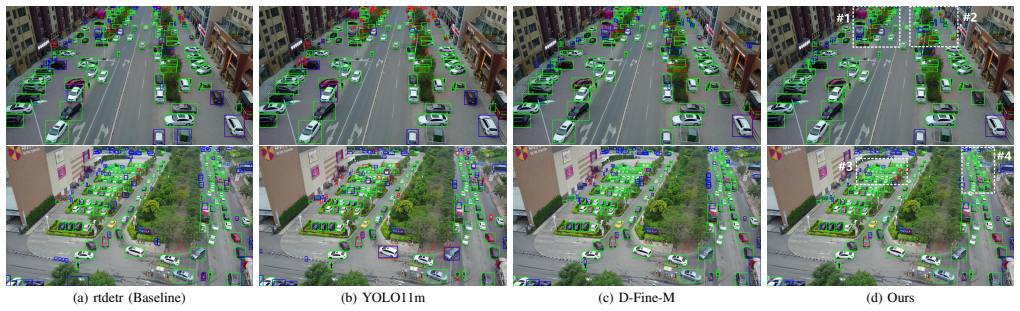

read the original abstract
Small object detection remains a significant challenge due to feature degradation from downsampling, mutual occlusion in dense clusters, and complex background interference. To address these issues, this paper proposes FSDETR, a frequency-spatial feature enhancement framework built upon the RT-DETR baseline. By establishing a collaborative modeling mechanism, the method effectively leverages complementary structural information. Specifically, a Spatial Hierarchical Attention Block (SHAB) captures both local details and global dependencies to strengthen semantic representation. Furthermore, to mitigate occlusion in dense scenes, the Deformable Attention-based Intra-scale Feature Interaction (DA-AIFI) focuses on informative regions via dynamic sampling. Finally, the Frequency-Spatial Feature Pyramid Network (FSFPN) integrates frequency filtering with spatial edge extraction via the Cross-domain Frequency-Spatial Block (CFSB) to preserve fine-grained details. Experimental results show that with only 14.7M parameters, FSDETR achieves 13.9% APS on VisDrone 2019 and 48.95% AP50 tiny on TinyPerson, showing strong performance on small-object benchmarks. The code and models are available at https://github.com/YT3DVision/FSDETR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FSDETR, a frequency-spatial feature enhancement framework built on the RT-DETR baseline for small object detection. It introduces three modules: the Spatial Hierarchical Attention Block (SHAB) to capture local details and global dependencies, the Deformable Attention-based Intra-scale Feature Interaction (DA-AIFI) to handle occlusions via dynamic sampling, and the Cross-domain Frequency-Spatial Block (CFSB) integrated into the Frequency-Spatial Feature Pyramid Network (FSFPN) to combine frequency filtering with spatial edge extraction. The central claim is that these blocks collaboratively leverage complementary frequency-spatial information to improve performance on small objects, with reported results of 13.9% APS on VisDrone 2019 and 48.95% AP50-tiny on TinyPerson using only 14.7M parameters. Code and models are released.
Significance. If the reported gains can be shown to stem from the specific mechanisms in SHAB, DA-AIFI, and CFSB rather than generic capacity increases, the work would offer a practical advance for small-object detection in dense or aerial scenes. The public release of code and models strengthens reproducibility and potential impact.
major comments (2)
- [Experimental results] Experimental evaluation: The manuscript reports benchmark improvements for FSDETR (14.7M parameters) over the unmodified RT-DETR baseline but provides no ablation that inserts generic capacity (extra layers, channels, or attention heads) into RT-DETR to match the parameter count while preserving identical training recipe, data, and optimizer. Without this control, the 13.9% APS on VisDrone and 48.95% AP50-tiny on TinyPerson cannot be confidently attributed to the frequency-spatial blocks rather than added model capacity.
- [Method overview] Module descriptions and interactions: The abstract and method overview assert that SHAB, DA-AIFI, and CFSB supply 'complementary structural information' via a 'collaborative modeling mechanism,' yet no quantitative analysis (e.g., feature visualization, attention maps, or incremental ablation removing one block at a time) is supplied to demonstrate complementarity or to rule out redundancy among the three components.
minor comments (1)
- [Abstract] The abstract states benchmark numbers and parameter count but supplies no table or figure reference for the full set of comparisons, error bars, or per-category breakdowns that would normally appear in the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of experimental rigor and methodological validation that we agree deserve further attention. Below we respond point-by-point to the major comments and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: The manuscript reports benchmark improvements for FSDETR (14.7M parameters) over the unmodified RT-DETR baseline but provides no ablation that inserts generic capacity (extra layers, channels, or attention heads) into RT-DETR to match the parameter count while preserving identical training recipe, data, and optimizer. Without this control, the 13.9% APS on VisDrone and 48.95% AP50-tiny on TinyPerson cannot be confidently attributed to the frequency-spatial blocks rather than added model capacity.
Authors: We fully agree that a capacity-matched control experiment is necessary to rigorously attribute the observed gains to the proposed modules rather than to increased model size. In the revised manuscript we will add a new ablation table that augments the baseline RT-DETR with generic extra layers, channels, or attention heads to reach approximately 14.7M parameters while keeping the identical training recipe, data splits, optimizer, and schedule. We will report the resulting APS and AP50-tiny scores and compare them directly with FSDETR. This control will allow readers to assess whether the frequency-spatial designs provide benefits beyond raw capacity. revision: yes
-
Referee: The abstract and method overview assert that SHAB, DA-AIFI, and CFSB supply 'complementary structural information' via a 'collaborative modeling mechanism,' yet no quantitative analysis (e.g., feature visualization, attention maps, or incremental ablation removing one block at a time) is supplied to demonstrate complementarity or to rule out redundancy among the three components.
Authors: We acknowledge that the original submission lacked explicit quantitative evidence for complementarity. In the revision we will include: (1) an incremental ablation study that successively removes SHAB, DA-AIFI, and CFSB (and reports the performance drop on both VisDrone and TinyPerson), and (2) qualitative visualizations including feature maps and attention heatmaps that illustrate how the modules capture distinct frequency-domain versus spatial-domain cues. These additions will directly demonstrate the collaborative benefit and help rule out redundancy. revision: yes
Circularity Check
No circularity: empirical architecture proposal with external benchmarks
full rationale
The paper presents FSDETR as an engineering extension of the RT-DETR baseline by adding three new blocks (SHAB, DA-AIFI, CFSB) whose design is motivated by domain knowledge about small-object challenges rather than any closed-form derivation or first-principles prediction. No equations, fitted parameters, or self-referential theorems are invoked to derive performance; results are measured on public external datasets (VisDrone 2019, TinyPerson) using standard detection metrics. The central claim therefore rests on comparative experiments, not on any step that reduces by construction to its own inputs. Self-citations, if present in the full text, are not load-bearing for any mathematical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DETRs beat YOLOs on real-time object detection,
H. Zhao, J. Zhang, Y . Zhao, P. Li, C.-C. Loy, D. Lin, and J. Jia, “DETRs beat YOLOs on real-time object detection,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 17063–17073, 2023
2023
-
[2]
Visdrone- det2019: The vision meets drone object detection in image challenge results,
D. Du, P. Zhu, L. Wen, X. Bian, H. Lin, Q. Hu, T. Peng, J. Zheng, X. Wang, Y . Zhang, L. Bo, H. Shi, R. Zhu, A. Kumar, A. Li, A. Zinol- layev, A. Askergaliyev, A. Schumann, B. Mao, B. Lee, C. Liu, C. Chen, C. Pan, C. Huo, D. Yu, D. Cong, D. Zeng, D. Reddy Pailla, D. Li, D. Wang, D. Cho, D. Zhang, F. Bai, G. Jose, G. Gao, G. Liu, H. Xiong, H. Qi, H. Wang, ...
2019
-
[3]
Scale match for tiny person detection,
X. Yu, Y . Gong, N. Jiang, Q. Ye, and Z. Han, “Scale match for tiny person detection,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 1257–1265, 2020
2020
-
[4]
Path aggregation network for instance segmentation,
S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 8759–8768, 2018
2018
-
[5]
No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects,
R. Sunkara and T. Luo, “No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects,” in European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), pp. 443–459, Sept. 2022
2022
-
[6]
Gcgp-yolo: Global-local and channel grouping perception network for small object detection based on yolov8,
J. Liu, T. Yan, X. Chen, Z. Zhang, C. Wang, and W. Huang, “Gcgp-yolo: Global-local and channel grouping perception network for small object detection based on yolov8,” in2025 International Joint Conference on Neural Networks (IJCNN), pp. 1–10, 2025
2025
-
[7]
Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone- captured scenarios,
X. Zhu, S. Lyu, X. Wang, and Q. Zhao, “Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone- captured scenarios,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pp. 2778–2788, October 2021
2021
-
[8]
Rfla: Gaussian receptive field based label assignment for tiny object detection,
C. Xu, J. Wang, W. Yang, H. Yu, L. Yu, and G.-S. Xia, “Rfla: Gaussian receptive field based label assignment for tiny object detection,” in European Conference on Computer Vision, pp. 526–543, Springer, 2022
2022
-
[9]
Rt- detrv2: Improved baseline with bag-of-freebies for real-time detection transformer,
W. Lv, Y . Zhao, Q. Chang, K. Huang, G. Wang, and Y . Liu, “Rt- detrv2: Improved baseline with bag-of-freebies for real-time detection transformer,” 2024
2024
-
[10]
The improved algorithm of rt-detr based on multi-head attention mechanism,
D. Wang, Y . Jiang, and S. Wang, “The improved algorithm of rt-detr based on multi-head attention mechanism,” in2025 International Joint Conference on Neural Networks (IJCNN), pp. 1–8, 2025
2025
-
[11]
Fdsi-rtdetr : A lightweight unmanned aerial vehicle (uav) aerial image small object detection network,
T. Guo, Q. Song, Y . Xue, and F. Qiao, “Fdsi-rtdetr : A lightweight unmanned aerial vehicle (uav) aerial image small object detection network,” in2025 International Joint Conference on Neural Networks (IJCNN), pp. 1–8, 2025
2025
-
[12]
Fast fourier convolution,
L. Chi, B. Jiang, and Y . Mu, “Fast fourier convolution,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, pp. 4479–4490, 2020
2020
-
[13]
Global filter networks for image classification,
Y . Rao, W. Zhao, Z. Zhu, J. Lu, and J. Zhou, “Global filter networks for image classification,”Advances in neural information processing systems, vol. 34, pp. 980–993, 2021
2021
-
[14]
Cspnet: A new backbone that can enhance learning capability of cnn,
C.-Y . Wang, H.-Y . M. Liao, Y .-H. Wu, P.-Y . Chen, J.-W. Hsieh, and I.-H. Yeh, “Cspnet: A new backbone that can enhance learning capability of cnn,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp. 390–391, 2020
2020
-
[15]
Yolov10: Real-time end-to-end object detection,
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han,et al., “Yolov10: Real-time end-to-end object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 107984–108011, 2024
2024
-
[16]
Deformable DETR: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021
2021
-
[17]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to- end object detection,”arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
Ultralytics YOLO,
G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO,” Jan. 2023
2023
-
[19]
Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks,
J. Chen, S.-h. Kao, H. He, W. Zhuo, S. Wen, C.-H. Lee, and S.- H. G. Chan, “Run, don’t walk: Chasing higher flops for faster neural networks,”arXiv preprint arXiv:2303.03667, 2023
-
[20]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 568–578, 2021
2021
-
[21]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. B. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, pp. 318–327, 2017
2017
-
[22]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 2117–2125, 2017
2017
-
[23]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 6154–6162, 2018
2018
-
[24]
Ultralytics yolo11,
G. Jocher and J. Qiu, “Ultralytics yolo11,” 2024
2024
-
[25]
YOLOv12: Attention-Centric Real-Time Object Detectors
Y . Tian, Q. Ye, and D. Doermann, “Yolo12: Attention-centric real-time object detectors,”arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
D-fine: Redefine regression task in detrs as fine-grained distribution refinement,
Y . Peng, H. Li, P. Wu, Y . Zhang, X. Sun, and F. Wu, “D-fine: Redefine regression task in detrs as fine-grained distribution refinement,” 2024
2024
-
[27]
Freeanchor: Learning to match anchors for visual object detection,
X. Zhang, F. Wan, C. Liu, R. Ji, and Q. Ye, “Freeanchor: Learning to match anchors for visual object detection,”arXiv, 2019
2019
-
[28]
Rethinking features-fused-pyramid-neck for object detection,
H. Li, “Rethinking features-fused-pyramid-neck for object detection,” in European Conference on Computer Vision, pp. 74–90, Springer, 2024
2024
-
[29]
Varifocalnet: An iou-aware dense object detector,
H. Zhang, Y . Wang, F. Dayoub, and N. Sunderhauf, “Varifocalnet: An iou-aware dense object detector,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8514–8523, 2021
2021
-
[30]
Focal and efficient iou loss for accurate bounding box regression,
Y .-F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, and T. Tan, “Focal and efficient iou loss for accurate bounding box regression,”Neurocomput- ing, vol. 506, pp. 146–157, 2022
2022
-
[31]
Available: https://gemini
Google, “Gemini.” [Large language model]. Available: https://gemini. google.com, 2026. Accessed: Feb. 1, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.