MemoSight: Unifying Context Compression and Multi Token Prediction for Reasoning Acceleration
Pith reviewed 2026-05-10 11:24 UTC · model grok-4.3
The pith
MemoSight unifies context compression and multi-token prediction with one minimalist special-token design for faster chain-of-thought reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
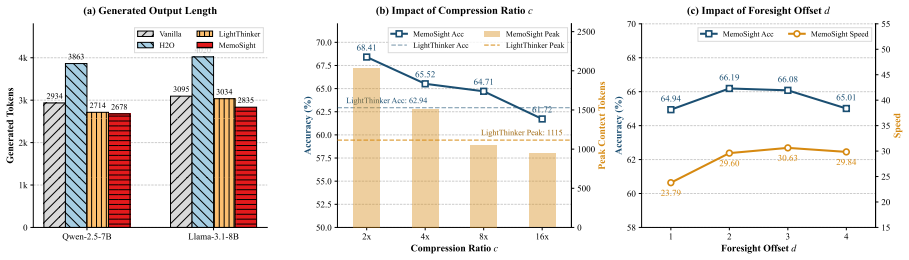
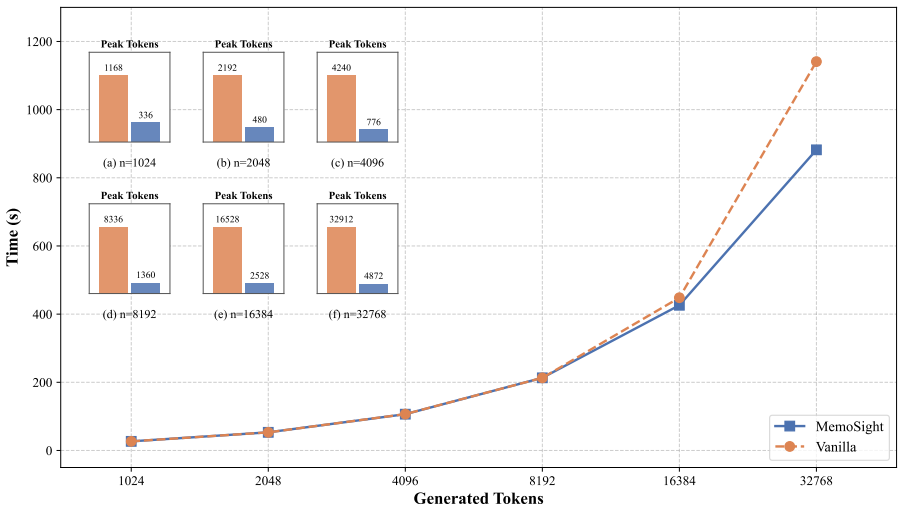
MemoSight integrates context compression and multi-token prediction into one framework for chain-of-thought reasoning by using the same minimalist special tokens and their corresponding tailored position layouts for each token type. This design reduces the KV cache footprint by up to 66 percent and accelerates inference by 1.56 times on four reasoning benchmarks while outperforming existing CoT compression methods and preserving reasoning performance.
What carries the argument
The minimalist special-token design with tailored position layouts that simultaneously manages context compression and multi-token prediction.
If this is right
- KV cache memory use drops by as much as 66 percent during long reasoning traces.
- Inference speed increases by a factor of 1.56 times while accuracy holds steady.
- The same token-plus-layout mechanism works for both compression and multi-token prediction without extra modules.
- Performance exceeds that of prior separate CoT compression techniques on the tested benchmarks.
- Reasoning quality stays comparable to full chain-of-thought across the evaluated tasks.
Where Pith is reading between the lines
- The design could support much longer reasoning chains before memory limits are reached.
- Similar position-layout tricks might apply to other efficiency goals such as speculative decoding or retrieval augmentation.
- If the assumption holds, the method offers a low-overhead way to combine several acceleration ideas that are usually implemented separately.
- Testing the same tokens on non-reasoning tasks like code generation or long-document summarization would reveal how general the layout pattern really is.
Load-bearing premise
The special-token and position-layout approach can handle both compression and multi-token prediction at once without lowering chain-of-thought reasoning quality or creating new failure modes.
What would settle it
A direct comparison on any of the four reasoning benchmarks where MemoSight produces lower accuracy or more reasoning errors than standard chain-of-thought on the identical base model and prompt.
Figures









read the original abstract
While Chain-of-thought (CoT) reasoning enables LLMs to solve challenging reasoning problems, as KV cache grows linearly with the number of generated tokens, CoT reasoning faces scaling issues in terms of speed and memory usage. In this work, we propose MemoSight (Memory-Foresight-based reasoning), a unified framework that integrates both context compression and multi-token prediction to mitigate the efficiency issues while maintaining CoT reasoning performance. Our framework adopts the same minimalist design for both context compression and multi-token prediction via special tokens and their corresponding position layout tailored to each token type. Comprehensive experiments on four reasoning benchmarks demonstrate that MemoSight reduces the KV cache footprint by up to 66% and accelerates inference by 1.56x, while outperforming existing CoT compression methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemoSight, a unified framework integrating context compression and multi-token prediction for accelerating chain-of-thought (CoT) reasoning in LLMs. It employs a minimalist design using special tokens with type-specific position layouts for both tasks. Experiments on four reasoning benchmarks claim up to 66% KV cache reduction, 1.56x inference speedup, and superior performance over existing CoT compression methods while preserving reasoning quality.
Significance. If the empirical claims hold under rigorous validation, this work could meaningfully advance efficient long-form reasoning by addressing linear KV cache growth without separate modules for compression and prediction. The unified special-token approach offers a practical engineering contribution with potential for broader adoption in resource-limited inference settings.
major comments (2)
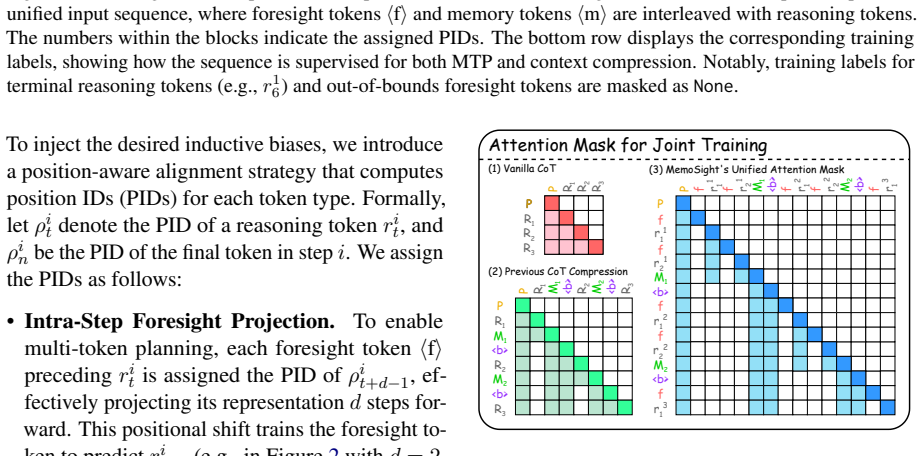
- [§3] §3 (Method): The central claim that the same minimalist special-token design with tailored position layouts simultaneously handles context compression and multi-token prediction without degrading CoT fidelity lacks a precise specification of the layout rules, token embedding sharing, or attention masking differences between the two token types. This detail is load-bearing for the unification argument and the reported efficiency gains.
- [§4] §4 (Experiments): The abstract and results assert 66% KV cache reduction and 1.56x acceleration with maintained or improved benchmark performance, but no ablation studies isolate the contribution of the unified design versus separate compression or prediction modules, nor report variance across runs or statistical significance tests on accuracy preservation across the four benchmarks.
minor comments (2)
- The related work section should include explicit comparisons to recent multi-token prediction methods (e.g., those using speculative decoding or parallel decoding) to better contextualize the novelty of the position-layout unification.
- Figure captions and method diagrams would benefit from clearer labeling of how compression tokens versus prediction tokens interact within the same KV cache during inference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address the two major comments point by point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that the same minimalist special-token design with tailored position layouts simultaneously handles context compression and multi-token prediction without degrading CoT fidelity lacks a precise specification of the layout rules, token embedding sharing, or attention masking differences between the two token types. This detail is load-bearing for the unification argument and the reported efficiency gains.
Authors: We appreciate this observation. While Section 3 describes the special tokens and position layouts at a high level, we agree that more precise specifications are needed to fully substantiate the unification. In the revised manuscript, we will add a dedicated subsection or appendix with explicit rules: a table detailing position ID assignments for compression tokens versus prediction tokens, clarification on whether token embeddings are shared across types, and the exact attention mask patterns (e.g., causal masking adjustments) used for each. This will strengthen the methodological contribution without altering the core design. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results assert 66% KV cache reduction and 1.56x acceleration with maintained or improved benchmark performance, but no ablation studies isolate the contribution of the unified design versus separate compression or prediction modules, nor report variance across runs or statistical significance tests on accuracy preservation across the four benchmarks.
Authors: We acknowledge the value of these additional analyses. In the revision, we will include ablation studies comparing the unified MemoSight approach to variants with separate compression and prediction modules. Furthermore, we will report mean and standard deviation of performance metrics over multiple random seeds (e.g., 3-5 runs) and conduct statistical significance tests, such as Wilcoxon signed-rank tests or paired t-tests, to rigorously demonstrate that reasoning quality is preserved or improved. These additions will provide stronger evidence for the claims. revision: yes
Circularity Check
No significant circularity; empirical proposal with no derivation chain
full rationale
The paper describes an engineering framework (MemoSight) that applies special tokens and position layouts for simultaneous context compression and multi-token prediction in CoT reasoning. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation load-bearing uniqueness theorems appear in the manuscript. Central performance claims (KV cache reduction, inference speedup, benchmark outperformance) are asserted via experiments on four reasoning benchmarks rather than any closed-form reduction to inputs. The work is self-contained as an empirical contribution without the self-definitional or fitted-input patterns that would trigger circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chain-of-thought reasoning performance can be preserved while applying context compression and multi-token prediction through special tokens.
invented entities (1)
-
Special tokens with type-specific position layouts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, and 1 others. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kis...
work page internal anchor Pith review arXiv 2009
-
[2]
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression.arXiv preprint arXiv:2403.12968. Weizhen Qi, Yu Yan, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, and Ming Zhou
-
[3]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Prophetnet: Predicting future n-gram for sequence-to-sequencepre-training. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2401–2410. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R Bowman. 2024. Gpqa: A graduate-level google-proof q&a bench...
work page internal anchor Pith review arXiv 2020
-
[4]
Softcot: Soft chain-of-thought for efficient reasoning with llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 23336– 23351. Jiangnan Ye, Hanqi Yan, Zhenyi Shen, Heng Chang, Ye Mao, and Yulan He. 2026. Context compression via explicit information transmission.arXiv preprint arXiv...
-
[5]
are excluded from this discussion. Context compression for the generation phase generally falls into three paradigms: latent reason- ing, explicit token selection, and implicit latent con- densation.1) Latent reasoning.To bypass the ver- bosity of explicit CoT, methods like Coconut (Hao et al., 2025) and SoftCoT (Xu et al., 2025) perform reasoning in a co...
2025
-
[6]
However, Zhang et al
distills natural language CoT via hidden state alignment, while SIM-CoT (Wei et al., 2025) uses an auxiliary decoder to provide step-level supervi- sion. However, Zhang et al. (2025b) argue that cur- rent latent models tend to learn pseudo-reasoning mechanisms rather than true reasoning.2) Explicit token selection.Early methods prune discrete to- kens bas...
2025
-
[7]
parses text into discourse trees to maintain global structure, SWEzze (Jia et al., 2026) extracts minimal sufficient subsequences for code reposito- ries, and TokenSkip (Xia et al., 2025) learns to omit 13 redundant tokens dynamically during reasoning.3) Implicit latent condensationcompress contexts into continuous latent embeddings, or memory to- kens. F...
2026
-
[8]
<THOUGHT>...</THOUGHT>
introduced MTP for sequence-to-sequence tasks, their multi-stream attention scales poorly to large models. Recent research addresses this architectural bottleneck using auxiliary decoding heads: Gloeckle et al. (2024) employ parallel heads to improve generative performance, and Liu et al. (2024a) adopt sequential heads to enhance implicit planning within ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.