Recognition: unknown
Improving Sparse Autoencoder with Dynamic Attention
Pith reviewed 2026-05-10 11:03 UTC · model grok-4.3
The pith
Sparse autoencoders using sparsemax attention in cross-attention achieve lower reconstruction loss and high-quality concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a new class of sparse autoencoders based on cross-attention where latent features query the dictionary, and employ sparsemax attention to dynamically infer sparse activation patterns according to the complexity of each neuron, leading to lower reconstruction loss and high-quality concepts in top-n classification tasks.
What carries the argument
Cross-attention architecture with sparsemax, using latent features as queries and learnable dictionary as key-value pairs, to enable data-dependent sparsity in neuron activations.
If this is right
- Lower reconstruction loss is achieved compared to conventional SAEs.
- High-quality concepts are produced that perform well in top-n classification tasks.
- Sparsity levels are determined automatically without extra regularization terms.
- The activation function becomes more flexible and general across different settings.
Where Pith is reading between the lines
- This dynamic mechanism could be tested on additional foundation models to confirm broad applicability without per-model tuning.
- The cross-attention view opens possibilities for combining SAEs with other attention-based methods for enhanced interpretability.
- Improvements in reconstruction might allow for finer-grained feature analysis in model debugging scenarios.
Load-bearing premise
Sparsemax attention will reliably infer appropriate per-neuron sparsity levels across different models and datasets without requiring additional regularization or dataset-specific hyperparameter search.
What would settle it
If the proposed SAE requires hyperparameter search for sparsity to outperform standard methods on new datasets, or if concept quality does not improve in top-n tasks, the benefit of the dynamic attention would be undermined.
Figures









read the original abstract
Recently, sparse autoencoders (SAEs) have emerged as a promising technique for interpreting activations in foundation models by disentangling features into a sparse set of concepts. However, identifying the optimal level of sparsity for each neuron remains challenging in practice: excessive sparsity can lead to poor reconstruction, whereas insufficient sparsity may harm interpretability. While existing activation functions such as ReLU and TopK provide certain sparsity guarantees, they typically require additional sparsity regularization or cherry-picked hyperparameters. We show in this paper that dynamically sparse attention mechanisms using sparsemax can bridge this trade-off, due to their ability to determine the activation numbers in a data-dependent manner. Specifically, we first explore a new class of SAEs based on the cross-attention architecture with the latent features as queries and the learnable dictionary as the key and value matrices. To encourage sparse pattern learning, we employ a sparsemax-based attention strategy that automatically infers a sparse set of elements according to the complexity of each neuron, resulting in a more flexible and general activation function. Through comprehensive evaluation and visualization, we show that our approach successfully achieves lower reconstruction loss while producing high-quality concepts, particularly in top-n classification tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cross-attention sparse autoencoder architecture in which latent features serve as queries and a learnable dictionary as keys/values, replacing standard activations (ReLU, TopK) with sparsemax attention to dynamically determine per-neuron sparsity levels in a data-dependent manner. It claims this yields lower reconstruction loss and higher-quality concepts than prior SAEs, without requiring additional sparsity regularization or dataset-specific hyperparameter search.
Significance. If the central empirical claims are substantiated, the work could simplify SAE training pipelines by removing manual sparsity tuning, which is a practical bottleneck in mechanistic interpretability. The attention-based formulation for dynamic sparsity is a distinct technical choice from existing TopK or ReLU variants and merits evaluation against standard baselines.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The abstract asserts 'lower reconstruction loss' and 'high-quality concepts' from comprehensive evaluation, yet supplies no quantitative metrics, baseline comparisons (e.g., against standard TopK SAE or ReLU SAE), dataset details, or statistical significance tests. Without these, the central claim that sparsemax removes the need for regularization or hyperparameter search cannot be assessed.
- [§3] §3 (Method): The claim that sparsemax 'automatically infers a sparse set of elements according to the complexity of each neuron' without extra regularization rests on the assumption that learned attention logits will reliably produce appropriate support sizes. However, sparsemax projects onto the simplex and its effective sparsity is controlled by logit separation; nothing in the formulation prevents the optimizer from converging to dense or over-sparse solutions unless other training choices (learning rate, initialization, loss weighting) implicitly enforce it. No ablation or stability analysis across held-out models/datasets is referenced to support the 'no cherry-picked hyperparameters' assertion.
- [§4] §4 (top-n classification tasks): The reported gains in 'top-n classification tasks' are not accompanied by controls for dictionary size, training steps, or reconstruction-vs-sparsity trade-off curves. If these tasks are the primary evidence for 'high-quality concepts,' the absence of such controls leaves open whether the improvement stems from dynamic sparsity or from other unstated differences in architecture or optimization.
minor comments (2)
- [§3] Notation for the cross-attention SAE (queries, keys, values) should be defined explicitly with equations in §3 to avoid ambiguity with standard transformer attention.
- [Figures] Figure captions and axis labels in visualization sections should include the exact sparsity level (or average support size) achieved by sparsemax for each reported run.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The comments highlight important areas for clarifying our empirical claims and methodological assumptions. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The abstract asserts 'lower reconstruction loss' and 'high-quality concepts' from comprehensive evaluation, yet supplies no quantitative metrics, baseline comparisons (e.g., against standard TopK SAE or ReLU SAE), dataset details, or statistical significance tests. Without these, the central claim that sparsemax removes the need for regularization or hyperparameter search cannot be assessed.
Authors: We agree that the abstract would be strengthened by including specific quantitative highlights. The full §4 already reports reconstruction losses, concept quality metrics, and comparisons against TopK and ReLU baselines on standard datasets (e.g., those from prior SAE literature), with matched training steps and dictionary sizes. In the revision we will (i) update the abstract to cite key numbers and dataset names, (ii) add a compact results table summarizing the main metrics, and (iii) include error bars or significance tests for the reported improvements. These changes will make the central claim directly assessable from the abstract. revision: yes
-
Referee: [§3] §3 (Method): The claim that sparsemax 'automatically infers a sparse set of elements according to the complexity of each neuron' without extra regularization rests on the assumption that learned attention logits will reliably produce appropriate support sizes. However, sparsemax projects onto the simplex and its effective sparsity is controlled by logit separation; nothing in the formulation prevents the optimizer from converging to dense or over-sparse solutions unless other training choices (learning rate, initialization, loss weighting) implicitly enforce it. No ablation or stability analysis across held-out models/datasets is referenced to support the 'no cherry-picked hyperparameters' assertion.
Authors: The referee correctly notes that sparsemax alone does not guarantee a particular sparsity level; the data-dependent support arises from the interaction between the cross-attention formulation, the reconstruction objective, and our chosen initialization and loss weighting. We will add an explicit paragraph in §3 explaining these implicit controls and will include a new ablation subsection in the revision that reports sparsity statistics (mean and variance of active features) across multiple random seeds, held-out datasets, and learning-rate schedules. This will directly address the stability concern while preserving the claim that no dataset-specific sparsity hyperparameter search is required. revision: partial
-
Referee: [§4] §4 (top-n classification tasks): The reported gains in 'top-n classification tasks' are not accompanied by controls for dictionary size, training steps, or reconstruction-vs-sparsity trade-off curves. If these tasks are the primary evidence for 'high-quality concepts,' the absence of such controls leaves open whether the improvement stems from dynamic sparsity or from other unstated differences in architecture or optimization.
Authors: Dictionary size and training steps are already matched across all methods in §4. To eliminate any ambiguity about the source of the gains, we will add reconstruction-versus-sparsity Pareto curves (varying the effective sparsity via temperature or threshold) and will explicitly state the fixed dictionary sizes and step counts used. These additions will demonstrate that the observed improvements in top-n classification arise from the dynamic, data-dependent sparsity rather than from mismatched experimental conditions. revision: yes
Circularity Check
No circularity; standard sparsemax in cross-attention SAE is externally defined and results are empirical.
full rationale
The paper introduces a cross-attention architecture for SAEs where latents serve as queries and the dictionary as keys/values, then applies sparsemax to produce data-dependent sparsity. This relies on the established properties of sparsemax (an external activation function) rather than any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation. The claimed improvements in reconstruction loss and concept quality are presented as outcomes of comprehensive evaluation, not as mathematical necessities derived from the inputs by construction. No derivation chain reduces to its own fitted values or prior author work invoked as uniqueness theorem.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Sparsemax produces a sparse probability distribution with exact zeros
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020. 3
work page internal anchor Pith review arXiv 2004
-
[3]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Pro- ceedings, Part VI 13, pages 446–461. Springer, 2014. 6
2014
-
[4]
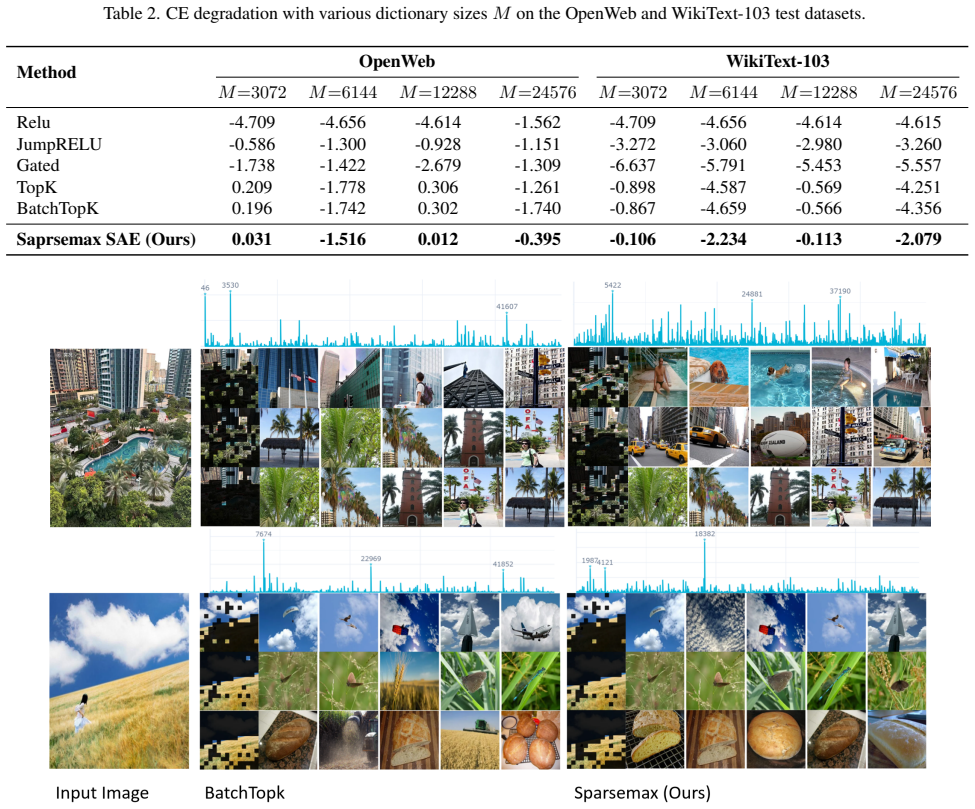
Towards monoseman- ticity: Decomposing language models with dictionary learn- ing.Transformer Circuits Thread, 2023
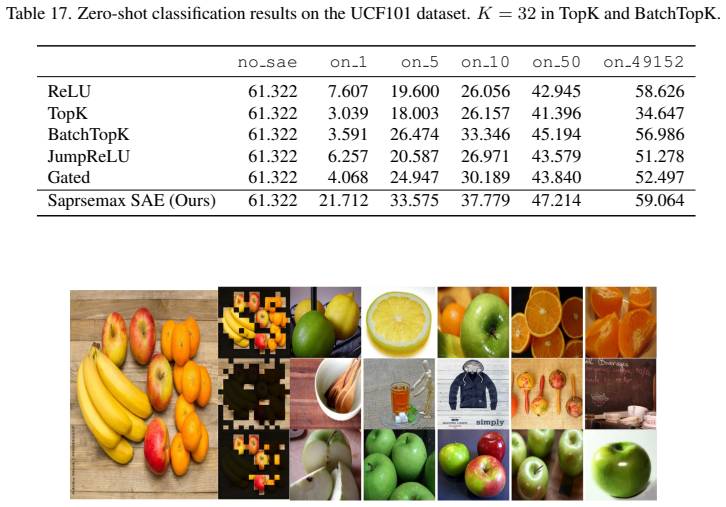
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Ch...
2023
-
[5]
Batchtopk sparse autoencoders
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning. 2, 7
2024
-
[6]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 1
2023
-
[7]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019. 3
work page internal anchor Pith review arXiv 1904
-
[8]
Colwell, and Adrian Weller
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tam´as Sarl´os, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J. Colwell, and Adrian Weller. Rethinking attention with performers. In9th International Conference on Learning Representations, ICLR 2021, Virtual Ev...
2021
-
[9]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014. 6
2014
-
[10]
Adaptively sparse transformers
Gonc ¸alo M Correia, Vlad Niculae, and Andr ´e FT Martins. Adaptively sparse transformers. In2019 Conference on Em- pirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Process- ing, EMNLP-IJCNLP 2019, pages 2174–2184. Association for Computational Linguistics, 2019. 3
2019
-
[11]
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
Bartosz Cywi´nski and Kamil Deja. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoen- coders.arXiv preprint arXiv:2501.18052, 2025. 2
-
[12]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 3
2022
-
[13]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 6
2009
-
[14]
Sawtooth factorial topic embeddings guided gamma belief network
Zhibin Duan, Dongsheng Wang, Bo Chen, Chaojie Wang, Wenchao Chen, Yewen Li, Jie Ren, and Mingyuan Zhou. Sawtooth factorial topic embeddings guided gamma belief network. InInternational Conference on Machine Learning, pages 2903–2913. PMLR, 2021. 2
2021
-
[15]
Topicnet: Semantic graph-guided topic discovery
Zhibin Duan, Yishi Xu, Bo Chen, Dongsheng Wang, Chaojie Wang, and Mingyuan Zhou. Topicnet: Semantic graph-guided topic discovery. InAdvances in Neural Information Process- ing Systems, 2021. 8
2021
-
[16]
Efficient projections onto the l 1-ball for learning in high dimensions
John Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra. Efficient projections onto the l 1-ball for learning in high dimensions. InProceedings of the 25th international conference on Machine learning, pages 272–279, 2008. 4
2008
-
[17]
Toy models of superposition
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wat- tenberg, and Christopher Olah. Toy models of superposition. Transformer Circuits Thread, 2022. 1
2022
-
[18]
Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories. In 2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004. 6
2004
-
[19]
Archety- pal sae: Adaptive and stable dictionary learning for concept extraction in large vision models
Thomas Fel, Ekdeep Singh Lubana, Jacob S Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E Ba, and Talia Konkle. Archety- pal sae: Adaptive and stable dictionary learning for concept extraction in large vision models. InInternational Conference on Machine Learning, pages 16543–16572. PMLR, 2025. 1
2025
-
[20]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr´e la Tour, Henk Tillman, Gabriel Goh, Ra- jan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InThe Thir- teenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net,
2025
-
[21]
arXiv preprint arXiv:2410.13276 , year=
Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Peiyuan Zhou, Jiaxing Qi, Junjie Lai, Hayden Kwok-Hay So, Ting Cao, Fan Yang, et al. Seerattention: Learning intrinsic sparse attention in your llms.arXiv preprint arXiv:2410.13276,
-
[22]
Openwebtext corpus, 2019
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus, 2019. 6
2019
-
[23]
Adasplash: Adaptive sparse flash attention
Nuno Gon c ¸alves, Marcos V Treviso, and Andre Martins. Adasplash: Adaptive sparse flash attention. InForty-second International Conference on Machine Learning. 3
-
[24]
Adasplash: Adaptive sparse flash attention
Nuno Gon c ¸alves, Marcos V Treviso, and Andre Martins. Adasplash: Adaptive sparse flash attention. InForty-second International Conference on Machine Learning, 2025. 2
2025
-
[25]
Memory-efficient transformers via top-k attention
Ankit Gupta, Guy Dar, Shaya Goodman, David Ciprut, and Jonathan Berant. Memory-efficient transformers via top-k attention. InProceedings of the Second Workshop on Simple and Efficient Natural Language Processing, pages 39–52,
-
[26]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019. 6
2019
-
[27]
Hindupur, Ekdeep Singh Lubana, Thomas Fel, and Demba E
Sai Sumedh R. Hindupur, Ekdeep Singh Lubana, Thomas Fel, and Demba E. Ba. Projecting assumptions: The dual- ity between sparse autoencoders and concept geometry. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 1, 2
2025
-
[28]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenRe- view.net, 2024. 1, 2, 7
2024
-
[29]
A text classification method by integrating mobile inverted residual bottleneck convolution networks and capsule networks with adaptive feature channels
Tao Jin and Jiaming Liu. A text classification method by integrating mobile inverted residual bottleneck convolution networks and capsule networks with adaptive feature channels. Scientific Reports, 15(1):855, 2025. 3
2025
-
[30]
Measuring progress in dictio- nary learning for language model interpretability with board game models, 2024
Adam Karvonen, Benjamin Wright, Can Rager, Rico Angell, Jannik Brinkmann, Logan Smith, Claudio Mayrink Verdun, David Bau, and Samuel Marks. Measuring progress in dictio- nary learning for language model interpretability with board game models, 2024. page 16. 2
2024
-
[31]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InPro- ceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013. 6
2013
-
[32]
Efficient sparse coding algorithms.Advances in neural infor- mation processing systems, 19, 2006
Honglak Lee, Alexis Battle, Rajat Raina, and Andrew Ng. Efficient sparse coding algorithms.Advances in neural infor- mation processing systems, 19, 2006. 1
2006
-
[33]
Patchct: Aligning patch set and label set with conditional transport for multi- label image classification
Miaoge Li, Dongsheng Wang, Xinyang Liu, Zequn Zeng, Ruiying Lu, Bo Chen, and Mingyuan Zhou. Patchct: Aligning patch set and label set with conditional transport for multi- label image classification. InProceedings of the IEEE/CVF international conference on computer vision, pages 15348– 15358, 2023. 2
2023
-
[34]
Sparse autoencoders reveal selective remapping of visual concepts during adaptation
Hyesu Lim, Jinho Choi, Jaegul Choo, and Steffen Schnei- der. Sparse autoencoders reveal selective remapping of visual concepts during adaptation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singa- pore, April 24-28, 2025. 1, 2, 5, 7
2025
-
[35]
Patch- prompt aligned bayesian prompt tuning for vision-language models
Xinyang Liu, Dongsheng Wang, Miaoge Li, Bowei Fang, Yishi Xu, Zhibin Duan, Bo Chen, and Mingyuan Zhou. Patch- prompt aligned bayesian prompt tuning for vision-language models. InUncertainty in Artificial Intelligence, 2024. 8
2024
-
[36]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual clas- sification of aircraft.arXiv preprint arXiv:1306.5151, 2013. 6
work page internal anchor Pith review arXiv 2013
-
[37]
Alireza Makhzani and Brendan Frey. K-sparse autoencoders. arXiv preprint arXiv:1312.5663, 2013. 2
work page Pith review arXiv 2013
-
[38]
Luke Marks, Alasdair Paren, David Krueger, and Fazl Barez. Enhancing neural network interpretability with feature-aligned sparse autoencoders.arXiv preprint arXiv:2411.01220, 2024. 2
-
[39]
From softmax to sparse- max: A sparse model of attention and multi-label classifica- tion
Andre Martins and Ramon Astudillo. From softmax to sparse- max: A sparse model of attention and multi-label classifica- tion. InInternational conference on machine learning, pages 1614–1623. PMLR, 2016. 2
2016
-
[40]
Andr´e F. T. Martins and Ram´on Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classi- fication. InProceedings of the 33rd International Conference on Machine Learning (ICML), pages 1614–1623. PMLR,
-
[41]
A finite algorithm for finding the projec- tion of a point onto the canonical simplex of ∝ n.Journal of Optimization Theory and Applications, 50(1):195–200, 1986
Christian Michelot. A finite algorithm for finding the projec- tion of a point onto the canonical simplex of ∝ n.Journal of Optimization Theory and Applications, 50(1):195–200, 1986. 4
1986
-
[42]
Limitations of normalization in attention
Timur Mudarisov, Mikhail Burtsev, Tatiana Petrova, et al. Limitations of normalization in attention. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems. 3
-
[43]
Efficient dictionary learning with switch sparse autoencoders, 2024
Anish Mudide, Joshua Engels, Eric J Michaud, Max Tegmark, and Christian Schroeder de Witt. Efficient dictionary learning with switch sparse autoencoders, 2024. 273233368. 2
2024
-
[44]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, pages 722–729. IEEE, 2008. 6
2008
-
[45]
Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997. 1
1997
-
[46]
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´e J´egou, Julien Mairal, Pat...
2024
-
[47]
arXiv preprint arXiv:2504.02821 , year=
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models.arXiv preprint arXiv:2504.02821, 2025. 2
-
[48]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012. 6
2012
-
[49]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[50]
Ben Peters, Vlad Niculae, and Andr ´e F. T. Martins. Sparse sequence-to-sequence models. InProceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 1504–1519. Association for Computa- tional Linguistics, 2019. 2
2019
-
[51]
Ben Peters, Vlad Niculae, and Andr ´e F. T. Martins. Sparse sequence-to-sequence models. InProceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics (ACL), pages 1504–1519. ACL, 2019. 3
2019
-
[52]
Interpretability-aware vision transformer.arXiv preprint arXiv:2309.08035, 2023
Yao Qiang, Chengyin Li, Prashant Khanduri, and Dongxiao Zhu. Interpretability-aware vision transformer.arXiv preprint arXiv:2309.08035, 2023. 2
-
[53]
Improving language understanding by gener- ative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gener- ative pre-training. 2018. 2, 3
2018
-
[54]
Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019. 1, 6
2019
-
[55]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
2021
-
[56]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretabil- ity for transformer-based language models.arXiv preprint arXiv:2407.02646, 2024. 2
-
[57]
Improving dictionary learning with gated sparse autoen- coders.arXiv preprint arXiv:2404.16014,
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, J´anos Kram´ar, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024. 1, 2, 7
-
[58]
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Son- nerat, Arthur Conmy, Vikrant Varma, J ´anos Kram ´ar, and Neel Nanda. Jumping ahead: Improving reconstruction fi- delity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435, 2024. 1, 2, 7
-
[59]
Taking features out of superposition with sparse autoencoders
Lee Sharkey, Dan Braun, and Beren Millidge. Taking features out of superposition with sparse autoencoders. 2022. 2023. 2
2022
-
[60]
Route sparse autoen- coder to interpret large language models.arXiv preprint arXiv:2503.08200, 2025
Wei Shi, Sihang Li, Tao Liang, Mingyang Wan, Guojun Ma, Xiang Wang, and Xiangnan He. Route sparse autoen- coder to interpret large language models.arXiv preprint arXiv:2503.08200, 2025. 1
-
[61]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 6
work page internal anchor Pith review arXiv 2012
-
[62]
Samuel Stevens, Wei-Lun Chao, Tanya Berger-Wolf, and Yu Su. Sparse autoencoders for scientifically rigorous interpre- tation of vision models.arXiv preprint arXiv:2502.06755,
-
[63]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lind- sey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunning- ham, Nicholas L Turner, Callum McDougall, Monte Mac- Diarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling mo...
2024
-
[64]
Predicting attention sparsity in transformers
Marcos Treviso, Ant´onio G´ois, Patrick Fernandes, Erick Fon- seca, and Andr ´e FT Martins. Predicting attention sparsity in transformers. InProceedings of the Sixth Workshop on Structured Prediction for NLP, pages 67–81, 2022. 3
2022
-
[65]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 3, 4
2017
-
[66]
Repre- senting mixtures of word embeddings with mixtures of topic embeddings
Dongsheng Wang, Dandan Guo, He Zhao, Huangjie Zheng, Korawat Tanwisuth, Bo Chen, and Mingyuan Zhou. Repre- senting mixtures of word embeddings with mixtures of topic embeddings. InInternational Conference on Learning Repre- sentations, 2022. 1
2022
-
[67]
Tuning multi-mode token- level prompt alignment across modalities.Advances in Neural Information Processing Systems, 36:52792–52810, 2023
Dongsheng Wang, Miaoge Li, Xinyang Liu, MingSheng Xu, Bo Chen, and Hanwang Zhang. Tuning multi-mode token- level prompt alignment across modalities.Advances in Neural Information Processing Systems, 36:52792–52810, 2023. 3
2023
-
[68]
Instruction tuning-free visual token complement for multimodal llms
Dongsheng Wang, Jiequan Cui, Miaoge Li, Wang Lin, Bo Chen, and Hanwang Zhang. Instruction tuning-free visual token complement for multimodal llms. InEuropean Con- ference on Computer Vision, pages 446–462. Springer, 2024. 2
2024
-
[69]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[70]
Sun database: Large-scale scene recog- nition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recog- nition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010. 6
2010
-
[71]
Large multi-modal models can interpret features in large multi- modal models
Kaichen Zhang, Yifei Shen, Bo Li, and Ziwei Liu. Large multi-modal models can interpret features in large multi- modal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3650–3661, 2025. 2 Improving Sparse Autoencoder with Dynamic Attention Supplementary Material
2025
-
[72]
sparsemax(z) = arg min p∈∆M−1 1 2 ∥p−z∥ 2 2.(9) Equivalently, we solve the constrained quadratic program min p∈RM 1 2 MX i=1 (pi−zi)2 subject to MX i=1 pi = 1, p i ≥0∀i
Problem formulation.Recall that sparsemax is the Eu- clidean projection ofz∈R M onto the probability simplex ∆M−1 ={p∈R M |1 ⊤p= 1,p≥0},(8) i.e. sparsemax(z) = arg min p∈∆M−1 1 2 ∥p−z∥ 2 2.(9) Equivalently, we solve the constrained quadratic program min p∈RM 1 2 MX i=1 (pi−zi)2 subject to MX i=1 pi = 1, p i ≥0∀i. (10)
-
[73]
The (augmented) Lagrangian is L(p, τ,µ) = 1 2 MX i=1 (pi −z i)2 +τ MX i=1 pi −1 − MX i=1 µipi
Lagrangian and KKT conditions.Introduce the La- grange multiplier τ∈R for the equality constraintP i pi = 1 and multipliers µi ≥0 for the inequality constraintspi ≥0 . The (augmented) Lagrangian is L(p, τ,µ) = 1 2 MX i=1 (pi −z i)2 +τ MX i=1 pi −1 − MX i=1 µipi. (11) Karush–Kuhn–Tucker (KKT) conditions for optimality are: (i)Primal feasibility: PM i=1 pi ...
-
[74]
, M} z(r) + 1− Pr i=1 z(i) r >0 o , (21) and then takeτ=τ k, which completes the proof
Determining τ and the active set.Let the active set (support) be S={i|p i >0}={i|z i > τ}, k:=|S|.(15) Summing pi =z i −τ over i∈S and usingPM i=1 pi = 1 gives X i∈S (zi −τ) = 1 =⇒ X i∈S zi −kτ= 1.(16) Thus τ= P i∈S zi −1 k .(17) To find S efficiently, sort the coordinates in descending order: z(1) ≥z (2) ≥ · · · ≥z (M) .(18) If the optimal support corres...
-
[75]
6- 8 show the visualiza- tions of the top three concepts of the test image
More Visualization Results Analysis of Top 3 Concepts.Fig. 6- 8 show the visualiza- tions of the top three concepts of the test image. Overall, we find that our Sparsemax SAE successfully captures the key visual patterns. For example, the mixture of fruit, wooden background, and apples in Fig. 6. Moreover, our approach is able to understand visual feature...
-
[76]
Results of Zero-shot Image Classification We report the detailed zero-shot image classification results in Table. 7- 17. Table 7. Zero-shot classification results on the Caltech101 dataset.K= 32in TopK and BatchTopK. no sae on 1 on 5 on 10 on 50 on 49152 ReLU 32.403 7.816 17.591 21.033 28.671 31.672 JumpReLU 32.403 3.578 12.840 18.594 27.845 28.974 Gated ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.