Recognition: unknown
Frequency-Enhanced Dual-Subspace Networks for Few-Shot Fine-Grained Image Classification
Pith reviewed 2026-05-10 11:11 UTC · model grok-4.3
The pith
Frequency components paired with spatial features reduce overfitting in few-shot fine-grained image classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
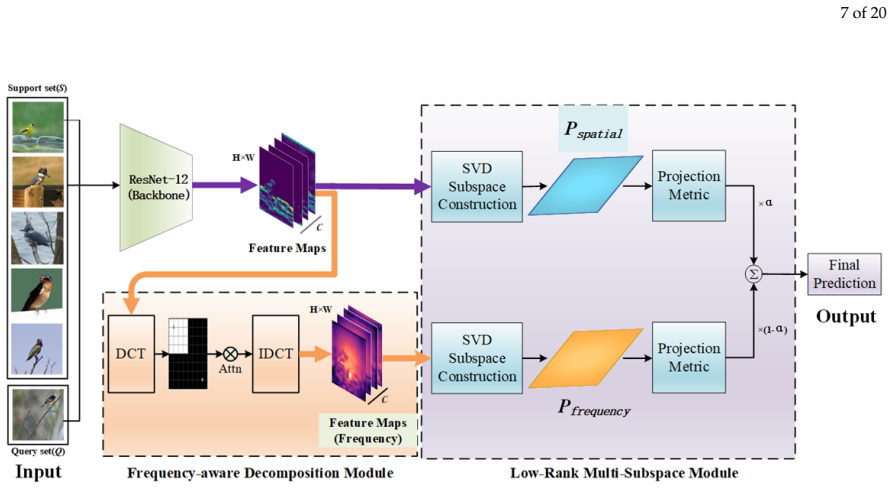
FEDSNet utilizes the Discrete Cosine Transform and a low-pass filtering mechanism to explicitly isolate low-frequency global structural components from spatial features, thereby suppressing background interference. Truncated Singular Value Decomposition is employed to construct independent, low-rank linear subspaces for both spatial texture and frequency structural features. An adaptive gating mechanism is designed to dynamically fuse the projection distances from these dual views, leveraging the structural stability of the frequency subspace to prevent the spatial subspace from overfitting to background features.
What carries the argument
Dual low-rank subspaces built by truncated SVD on spatial features and on DCT-isolated low-frequency components, fused by an adaptive gating mechanism on projection distances.
If this is right
- The model produces highly competitive accuracy on CUB-200-2011, Stanford Cars, Stanford Dogs, and FGVC-Aircraft under few-shot protocols.
- Background interference is suppressed by isolating low-frequency global structures before subspace projection.
- Single-view metric learning is replaced by cross-view fusion that supplies geometric constraints missing from spatial-only methods.
- Computational cost remains balanced with accuracy, as shown by the complexity analysis in the experiments.
Where Pith is reading between the lines
- The same frequency-plus-spatial split could be tested on other few-shot vision problems where texture biases dominate limited training sets.
- Replacing DCT with wavelets or Fourier transforms would test whether the stability benefit is specific to cosine-based low-pass isolation.
- If the frequency subspace proves robust across domains, it suggests that metric learning in general may benefit from explicit multi-domain constraints rather than deeper spatial networks alone.
Load-bearing premise
Low-frequency components isolated by DCT and low-pass filtering reliably capture stable structural information separate from high-frequency background noise.
What would settle it
An ablation study on the same four benchmarks showing no accuracy gain or a drop when the frequency subspace and low-pass filter are removed would falsify the claim that the dual-subspace fusion prevents overfitting.
Figures


read the original abstract
Few-shot fine-grained image classification aims to recognize subcategories with high visual similarity using only a limited number of annotated samples. Existing metric learning-based methods typically rely solely on spatial domain features. Confined to this single perspective, models inevitably suffer from inherent texture biases, entangling essential structural details with high-frequency background noise. Furthermore, lacking cross-view geometric constraints, single-view metrics tend to overfit this noise, resulting in structural instability under few-shot conditions. To address these issues, this paper proposes the Frequency-Enhanced Dual-Subspace Network (FEDSNet). Specifically, FEDSNet utilizes the Discrete Cosine Transform (DCT) and a low-pass filtering mechanism to explicitly isolate low-frequency global structural components from spatial features, thereby suppressing background interference. Truncated Singular Value Decomposition (SVD) is employed to construct independent, low-rank linear subspaces for both spatial texture and frequency structural features. An adaptive gating mechanism is designed to dynamically fuse the projection distances from these dual views. This strategy leverages the structural stability of the frequency subspace to prevent the spatial subspace from overfitting to background features. Extensive experiments on four benchmark datasets - CUB-200-2011, Stanford Cars, Stanford Dogs, and FGVC-Aircraft - demonstrate that FEDSNet exhibits excellent classification performance and robustness, achieving highly competitive results compared to existing metric learning algorithms. Complexity analysis further confirms that the proposed network achieves a favorable balance between high accuracy and computational efficiency, providing an effective new paradigm for few-shot fine-grained visual recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Frequency-Enhanced Dual-Subspace Network (FEDSNet) for few-shot fine-grained image classification. It applies DCT with low-pass filtering to isolate low-frequency global structural components from spatial features, suppressing background noise. Truncated SVD constructs independent low-rank subspaces for spatial texture and frequency structural features, which are then fused via an adaptive gating mechanism on projection distances. This dual-view approach is claimed to leverage frequency-subspace stability to prevent spatial-subspace overfitting under few-shot constraints. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and FGVC-Aircraft are said to yield highly competitive results versus existing metric-learning methods, with favorable accuracy-efficiency trade-offs.
Significance. If the empirical claims hold with proper validation, the work introduces a concrete dual-subspace fusion strategy that explicitly incorporates frequency-domain stability to mitigate texture bias and noise overfitting in few-shot fine-grained recognition. This could provide a useful architectural paradigm for metric-learning methods in domains where background interference is common, particularly if the frequency view demonstrably supplies complementary structural cues without discarding discriminative high-frequency content.
major comments (3)
- [Abstract] Abstract: The central claim of 'excellent classification performance and robustness' and 'highly competitive results' is unsupported by any numerical accuracies, standard deviations, ablation tables, or baseline comparisons in the abstract; without these in the experiments section, the performance assertions cannot be evaluated.
- [Method] Method (frequency isolation via DCT/low-pass): The design assumes low-frequency components reliably encode stable structural information that prevents spatial overfitting, yet fine-grained distinctions (e.g., feather patterns on CUB-200-2011 or car details on Stanford Cars) often reside in high-frequency textures; explicit low-pass filtering risks discarding these cues, and no analysis or counter-example is provided showing the retained low-rank SVD subspace remains sufficiently discriminative.
- [Experiments] Experiments: The robustness claim rests on the adaptive gating fusion stabilizing performance, but without reported ablations (e.g., spatial-only vs. dual-subspace, low-pass vs. high-pass variants, or gating ablations) or error bars across the four datasets, it is impossible to confirm that the frequency subspace supplies the claimed stabilizing effect rather than shared global shape.
minor comments (2)
- [Abstract] Abstract: Vague phrasing such as 'excellent classification performance' and 'favorable balance' should be replaced with concrete metrics (e.g., accuracy percentages and FLOPs) once the full results are presented.
- [Method] Notation: The description of 'projection distances from these dual views' is underspecified; clarify whether these are Euclidean distances in the respective subspaces or another metric, and how the gating weights are computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the presentation of our results and methodological justifications. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'excellent classification performance and robustness' and 'highly competitive results' is unsupported by any numerical accuracies, standard deviations, ablation tables, or baseline comparisons in the abstract; without these in the experiments section, the performance assertions cannot be evaluated.
Authors: We agree that the abstract would be more informative with explicit quantitative support for the performance claims. In the revised manuscript, we will update the abstract to include key accuracy results on the four benchmark datasets (CUB-200-2011, Stanford Cars, Stanford Dogs, FGVC-Aircraft) and brief comparisons to state-of-the-art metric-learning baselines. The full tables with standard deviations and ablations remain detailed in the experiments section. revision: yes
-
Referee: [Method] Method (frequency isolation via DCT/low-pass): The design assumes low-frequency components reliably encode stable structural information that prevents spatial overfitting, yet fine-grained distinctions (e.g., feather patterns on CUB-200-2011 or car details on Stanford Cars) often reside in high-frequency textures; explicit low-pass filtering risks discarding these cues, and no analysis or counter-example is provided showing the retained low-rank SVD subspace remains sufficiently discriminative.
Authors: We appreciate the referee's point on potential loss of discriminative high-frequency cues. The spatial subspace is explicitly intended to retain texture details (including fine-grained patterns), while the frequency subspace supplies complementary low-frequency structural stability via low-rank SVD. The adaptive gating mechanism then balances the two views. To directly address the request for analysis, we will add a new subsection with visualizations of retained frequency components and their classification contributions in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments: The robustness claim rests on the adaptive gating fusion stabilizing performance, but without reported ablations (e.g., spatial-only vs. dual-subspace, low-pass vs. high-pass variants, or gating ablations) or error bars across the four datasets, it is impossible to confirm that the frequency subspace supplies the claimed stabilizing effect rather than shared global shape.
Authors: We agree that additional ablations and error bars are necessary to isolate the contribution of the frequency subspace and gating. In the revised manuscript, we will include comprehensive ablation studies (spatial-only, frequency-only, dual-subspace, low-pass vs. high-pass, and gating variants) and report mean accuracies with standard deviations over multiple runs across all four datasets to substantiate the stabilizing effect. revision: yes
Circularity Check
No circularity in empirical architectural proposal
full rationale
The paper presents FEDSNet as a novel network architecture that applies DCT low-pass filtering to isolate low-frequency structural components, constructs dual low-rank subspaces via truncated SVD, and fuses projection distances with an adaptive gating mechanism. These elements are introduced as design choices to mitigate spatial overfitting in few-shot fine-grained classification, with claims supported by experimental results on standard benchmarks rather than any mathematical derivation. No equations, predictions, or uniqueness arguments reduce by construction to fitted inputs or prior self-citations; the derivation chain consists of independent architectural decisions validated externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DCT combined with low-pass filtering isolates low-frequency global structural components from spatial features while suppressing background interference
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition
He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV , USA, 27–30 June 2016; pp. 770–778
2016
-
[2]
Few-Shot Fine-Grained Image Classification: A Comprehensive Review.Acta Autom
Ren, J.; Li, C.; An, Y.; Zhang, W.; Sun, C. Few-Shot Fine-Grained Image Classification: A Comprehensive Review.Acta Autom. Sin.2024,50, 26–44
2024
-
[3]
Matching Networks for One Shot Learning
Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; Volume 29
2016
-
[4]
Prototypical Networks for Few-shot Learning
Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30
2017
-
[5]
Learning to compare: Relation network for few-shot learning
Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P .H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208
2018
-
[6]
Revisiting local descriptor based image-to-class measure for few-shot learning
Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7260–7268
2019
-
[7]
Low-Rank Pairwise Alignment Bilinear Network For Few-Shot Fine-Grained Image Classification.IEEE Trans
Huang, H.; Zhang, J.; Zhang, J.; Xu, J.; Wu, Q. Low-Rank Pairwise Alignment Bilinear Network For Few-Shot Fine-Grained Image Classification.IEEE Trans. Multimed.2021,23, 1666–1680
2021
-
[8]
Mixture-based feature space learning for few-shot image classification
Afrasiyabi, A.; Lalonde, J.F.; Gagné, C. Mixture-based feature space learning for few-shot image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9041–9051
2021
-
[9]
DeepEMD: Differentiable earth mover’s distance for few-shot learning
Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Differentiable earth mover’s distance for few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell.2022,44, 6358–6375
2022
-
[10]
Adaptive Subspaces for Few-Shot Learning
Simon, C.; Koniusz, P .; Nock, R.; Harandi, M. Adaptive Subspaces for Few-Shot Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4136–4145. 18 of 20
2020
-
[11]
Learning in the frequency domain
Xu, K.; Qin, M.; Sun, F.; Wang, Y.; Chen, Y.K.; Ren, F. Learning in the frequency domain. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1740–1749
2020
-
[12]
Global filter networks for image classification
Rao, Y.; Zhao, W.; Zhu, Z.; Lu, J.; Zhou, J. Global filter networks for image classification. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021; Volume 34, pp. 980–993
2021
-
[13]
Thinking in frequency: Face forgery detection by mining frequency-aware clues
Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8603–8612
2020
-
[14]
Robust recovery of subspace structures by low-rank representa- tion.IEEE Trans
Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representa- tion.IEEE Trans. Pattern Anal. Mach. Intell.2013,35, 171–184
2013
-
[15]
Multi-attention Meta Learning for Few-shot Fine-grained Image Recognition
Zhu, Y.; Liu, C.; Jiang, S. Multi-attention Meta Learning for Few-shot Fine-grained Image Recognition. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Yokohama, Japan, 11–17 July 2020; pp. 1090–1096
2020
-
[16]
Dual Attention Networks for Few-Shot Fine-Grained Recognition
Xu, S.; Zhang, F.; Wei, X.; Wang, J. Dual Attention Networks for Few-Shot Fine-Grained Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2970–2978
2022
-
[17]
Object-aware Long-short-range Spatial Alignment for Few-Shot Fine-Grained Image Classification
Wu, Y.; Zhang, B.; Yu, G.; Zhang, W.; Wang, B.; Chen, T.; Fan, J. Object-aware Long-short-range Spatial Alignment for Few-Shot Fine-Grained Image Classification. InProceedings of the ACM International Conference on Multimedia (ACM MM), Chengdu, China, 20–24 October 2021; pp. 3172–3180
2021
-
[18]
Generalizing from a few examples: A survey on few-shot learning
Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv.2020,53, 1–34
2020
-
[19]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Finn, C.; Abbeel, P .; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 1126–1135
2017
-
[20]
Meta-sgd: Learning to learn quickly for few-shot learning.arXiv preprint arXiv:1707.09835,
Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning.arXiv2017, arXiv:1707.09835
-
[21]
Task agnostic meta-learning for few-shot learning
Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11719–11727
2019
-
[22]
Siamese neural networks for one-shot image recognition
Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. InProceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2
2015
-
[23]
Deep metric learning using triplet network
Hoffer, E.; Ailon, N. Deep metric learning using triplet network. InProceedings of the International Workshop on Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; pp. 84–92
2015
-
[24]
Few-Shot Classification With Feature Map Reconstruction Networks
Wertheimer, D.; Tang, L.; Hariharan, B. Few-Shot Classification With Feature Map Reconstruction Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8012–8021
2021
-
[25]
Bi-directional feature reconstruction network for fine-grained few-shot image classification
Wu, J.; Chang, D.; Sain, A.; Li, X.; Ma, Z.; Cao, J.; Jun, G.; Song, Y.Z. Bi-directional feature reconstruction network for fine-grained few-shot image classification. InProceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 2821–2829
2023
-
[26]
Wah, C.; Branson, S.; Welinder, P .; Perona, P .; Belongie, S.The Caltech-UCSD Birds-200-2011 Dataset; Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011
2011
-
[27]
3D Object Representations for Fine-Grained Categorization
Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Sydney, Australia, 2–8 December 2013; pp. 554–561
2013
-
[28]
Fine-Grained Visual Classification of Aircraft
Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-Grained Visual Classification of Aircraft.arXiv 2013, arXiv:1306.5151
work page internal anchor Pith review arXiv 2013
-
[29]
BSNet: Bi-similarity network for few-shot fine-grained image classification.IEEE Trans
Li, X.; Wu, J.; Sun, Z.; Ma, Z.; Cao, J.; Xue, J.H. BSNet: Bi-similarity network for few-shot fine-grained image classification.IEEE Trans. Image Process.2020,30, 1318–1331
2020
-
[30]
Cross-Layer and Cross-Sample Feature Optimization Network for Few-Shot Fine-Grained Image Classification
Ma, Z.X.; Chen, Z.D.; Zhao, L.J. Cross-Layer and Cross-Sample Feature Optimization Network for Few-Shot Fine-Grained Image Classification. InProceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 4136–4144
2024
-
[31]
Boosting few-shot fine-grained recognition with background suppression and foreground alignment.IEEE Trans
Zha, Z.; Tang, H.; Sun, Y. Boosting few-shot fine-grained recognition with background suppression and foreground alignment.IEEE Trans. Circuits Syst. Video Technol.2023,33, 3947–3961. 19 of 20
2023
-
[32]
Crosstransformers: spatially-aware few-shot transfer
Doersch, C.; Gupta, A.; Zisserman, A. Crosstransformers: spatially-aware few-shot transfer. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Volume 33, pp. 21981–21993
2020
-
[33]
Global and local feature interaction with vision transformer for few-shot image classification
Sun, M.; Ma, W.; Liu, Y. Global and local feature interaction with vision transformer for few-shot image classification. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM), Atlanta, GA, USA, 17–21 October 2022; pp. 4530–4534
2022
-
[34]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626
2017
-
[35]
A Tutorial on Principal Component Analysis
Shlens, J. A tutorial on principal component analysis.arXiv2014, arXiv:1404.1100
-
[36]
Imagenet classification with deep convolutional neural networks
Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV , USA, 3–6 December 2012; Volume 25
2012
-
[37]
Meta-Learning with Latent Embedding Optimization
Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-Learning with Latent Embedding Optimization. InProceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019
2019
-
[38]
Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
Raghu, A.; Raghu, M.; Bengio, S.; Vinyals, O. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. InProceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020
2020
-
[39]
Low-shot visual recognition by shrinking and hallucinating features
Hariharan, B.; Girshick, R. Low-shot visual recognition by shrinking and hallucinating features. InProceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3015–3024
2017
-
[40]
Delta-encoder: an effective sample synthesis method for few-shot object recognition
Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Bronstein, A. Delta-encoder: an effective sample synthesis method for few-shot object recognition. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018; Volume 31
2018
-
[41]
Asymmetric Distribution Measure for Few-shot Learning
Li, W.; Wang, L.; Huo, J.; Shi, Y.; Gao, Y.; Luo, J. Asymmetric Distribution Measure for Few-shot Learning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Virtual, 7–15 January 2020; pp. 3081–3087
2020
-
[42]
Squeeze-and-excitation networks
Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141
2018
-
[43]
Cbam: Convolutional block attention module
Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. InProceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19
2018
-
[44]
Context-Aware Task-Specific Metric Learning for Few-Shot Classification.IEEE Trans
Li, Q.; Cai, W.; Wang, Y.; Zhou, H.; Predovic, G.; Feng, D.D. Context-Aware Task-Specific Metric Learning for Few-Shot Classification.IEEE Trans. Circuits Syst. Video Technol.2021,31, 736–750
2021
-
[45]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InProceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021
2021
-
[46]
Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning
Hu, S.; Xie, Z.; Liu, H.; Nie, J.; He, Z.; Liu, Y. Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9068–9077
2022
-
[47]
SVDNet for Pedestrian Retrieval
Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for Pedestrian Retrieval. InProceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3800–3808
2017
-
[48]
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
Geirhos, R.; Rubisch, P .; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. InProceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019
2019
-
[49]
FcaNet: Frequency Channel Attention Networks
Qin, Z.; Zhang, P .; Wu, F.; Li, X. FcaNet: Frequency Channel Attention Networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 783–792
2021
-
[50]
Meta-Learning with Differentiable Convex Optimization
Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-Learning with Differentiable Convex Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665
2019
-
[51]
Distribution Consistency based Covariance Metric Networks for Few-Shot Learning
Li, W.; Xu, J.; Huo, J.; Wang, L.; Gao, Y.; Luo, J. Distribution Consistency based Covariance Metric Networks for Few-Shot Learning. InProceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8642–8649. 20 of 20
2019
-
[52]
Zhang, B.; Yuan, J.; Li, B.; Chen, T.; Fan, J.; Shi, B. Learning cross-image object semantic relation in transformer for few-shot fine-grained image classification.arXiv Preprint2022, arXiv:2207.00784
-
[53]
TOAN: Target-oriented alignment network for fine-grained image categorization with few labeled samples.IEEE Trans
Huang, H.; Zhang, J.; Yu, L.; Zhang, J.; Wu, Q.; Xu, C. TOAN: Target-oriented alignment network for fine-grained image categorization with few labeled samples.IEEE Trans. Circuits Syst. Video Technol.2022,32, 853–866
2022
-
[54]
Local descriptor-based multi-prototype network for few-shot learning.Pattern Recognition2021,116, 107935
Huang, H.; Wu, Z.; Li, W.; Huo, J.; Gao, Y. Local descriptor-based multi-prototype network for few-shot learning.Pattern Recognition2021,116, 107935
-
[55]
Recent advances on image edge detection: A comprehensive review.Neurocom- puting,2022,503, 259-271
Jing J, Liu S, Wang G, et al. Recent advances on image edge detection: A comprehensive review.Neurocom- puting,2022,503, 259-271
2022
-
[56]
Corner detection and classification using anisotropic directional derivative representations.IEEE Transactions on Image Processing,2013,501, 3204-3218
Shui, Peng-Lang, and Wei-Chuan Zhang. Corner detection and classification using anisotropic directional derivative representations.IEEE Transactions on Image Processing,2013,501, 3204-3218
2013
-
[57]
Noise robust image edge detection based upon the automatic anisotropic Gaussian kernels.Pattern Recognition,2017,63, 193-205
Zhang W C, Zhao Y L, Breckon T P , et al. Noise robust image edge detection based upon the automatic anisotropic Gaussian kernels.Pattern Recognition,2017,63, 193-205
2017
-
[58]
Contour-based corner detection via angle difference of principal directions of anisotropic Gaussian directional derivatives.Pattern Recognition,2015,48, 2785-2797
Zhang W C, Shui P L. Contour-based corner detection via angle difference of principal directions of anisotropic Gaussian directional derivatives.Pattern Recognition,2015,48, 2785-2797
2015
-
[59]
Corner detection using multi-directional structure tensor with multiple scales.International Journal of Computer Vision,2020,128, 438-459
Zhang W, Sun C. Corner detection using multi-directional structure tensor with multiple scales.International Journal of Computer Vision,2020,128, 438-459
2020
-
[60]
Discrete curvature representations for noise robust image corner detection
Zhang W, Sun C, Breckon T, et al. Discrete curvature representations for noise robust image corner detection. IEEE Transactions on Image Processing,2019,28, 4444-4459
2019
-
[61]
Image feature information extraction for interest point detection: A comprehen- sive review.IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,45, 4694-4712
Jing J, Gao T, Zhang W, et al. Image feature information extraction for interest point detection: A comprehen- sive review.IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,45, 4694-4712
2022
-
[62]
Corner detection using second-order generalized Gaussian directional derivative represen- tations.IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,43, 1213-1224
Zhang W, Sun C. Corner detection using second-order generalized Gaussian directional derivative represen- tations.IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,43, 1213-1224
2019
-
[63]
Re-abstraction and perturbing support pair network for few-shot fine-grained image classification.Pattern Recognition,2024,148, 110158
Zhang W, Zhao Y, Gao Y, et al. Re-abstraction and perturbing support pair network for few-shot fine-grained image classification.Pattern Recognition,2024,148, 110158
2024
-
[64]
Image intensity variation information for interest point detection.IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45, 9883-9894
Zhang W, Sun C, Gao Y. Image intensity variation information for interest point detection.IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45, 9883-9894
2023
-
[65]
Lei T, Song W, Zhang W, et al. Semi-supervised 3-d medical image segmentation using multiconsistency learning with fuzzy perception-guided target selection.IEEE Transactions on Radiation and Plasma Medical Sciences,2024,9, 421-432
2024
-
[66]
Adaptive feature selection-based feature reconstruction network for few-shot learning.Pattern Recognition,2025, 112289
Ren J, An Y, Lei T, et al. Adaptive feature selection-based feature reconstruction network for few-shot learning.Pattern Recognition,2025, 112289
2025
-
[67]
A principal component analysis-based feature optimization network for few-shot fine-grained image classification[J].Mathematics,2025,13(7): 1098
Wang M, Zheng B, Wang G, et al. A principal component analysis-based feature optimization network for few-shot fine-grained image classification[J].Mathematics,2025,13(7): 1098
2025
-
[68]
Wang W, Wang M, Wang H, et al. Feature complementation architecture for visual place recognition[J].arXiv preprint, arXiv:2506.12401,2025
-
[69]
An unbiased feature estimation network for few-shot fine-grained image classification[J].Sensors,2024,24(23), 7737
Wang J, Lu J, Yang J, et al. An unbiased feature estimation network for few-shot fine-grained image classification[J].Sensors,2024,24(23), 7737
2024
-
[70]
Lu J, Wu W, Gao K, et al. Meningioma Analysis and Diagnosis using Limited Labeled Samples[J].arXiv preprint, arXiv:2602.13335,2026
-
[71]
Deep learning-based neurodevelopmental assessment in preterm infants[J]
Ren L, Lu J, Zhang W, et al. Deep learning-based neurodevelopmental assessment in preterm infants[J]. arXiv preprint, arXiv:2601.11944,2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.