Recognition: unknown
COEVO: Co-Evolutionary Framework for Joint Functional Correctness and PPA Optimization in LLM-Based RTL Generation
Pith reviewed 2026-05-10 10:29 UTC · model grok-4.3
The pith
COEVO unifies functional correctness and PPA optimization in one co-evolutionary loop for LLM-generated RTL designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COEVO formulates correctness as a continuous co-optimization dimension alongside area, delay, and power within a single evolutionary loop. It supplies fine-grained scoring and diagnostic feedback through an enhanced testbench, applies an adaptive correctness gate with annealing to retain PPA-promising partial solutions, and uses four-dimensional Pareto-based non-dominated sorting with configurable intra-level ordering to preserve trade-offs without manual scalar weights.
What carries the argument
The co-evolutionary loop that keeps correctness as a continuous dimension with area, delay, and power, guided by fine-grained testbench feedback and maintained through four-dimensional Pareto non-dominated sorting.
If this is right
- Higher Pass@1 rates are achieved on VerilogEval 2.0 and RTLLM 2.0 than prior agentic methods across multiple LLM backbones.
- Best PPA results are reached on 43 of 49 synthesizable RTLLM designs.
- Architecturally promising but only partially correct candidates are retained and can improve the population.
- Full multi-objective PPA trade-offs are preserved without reduction to a single fitness value.
Where Pith is reading between the lines
- The same joint-optimization pattern could be tested on other code-generation domains where partial solutions carry useful efficiency signals.
- Evolutionary search with continuous multi-dimensional feedback may reduce reliance on perfect intermediate checkpoints in automated hardware design.
- If the testbench scoring generalizes, the framework could support larger RTL modules by keeping a diverse Pareto front across more objectives.
- Integrating similar co-evolution into broader LLM agent pipelines might improve end-to-end hardware outcomes beyond isolated RTL tasks.
Load-bearing premise
The enhanced testbench supplies fine-grained, unbiased diagnostic scores for partially correct designs that can reliably steer the evolutionary search toward jointly optimal solutions without introducing systematic bias.
What would settle it
Apply the same method to a fresh benchmark set and observe that it no longer exceeds sequential baselines on combined Pass@1 and PPA metrics, or that replacing continuous scoring with binary correctness gates produces equivalent or better results.
Figures


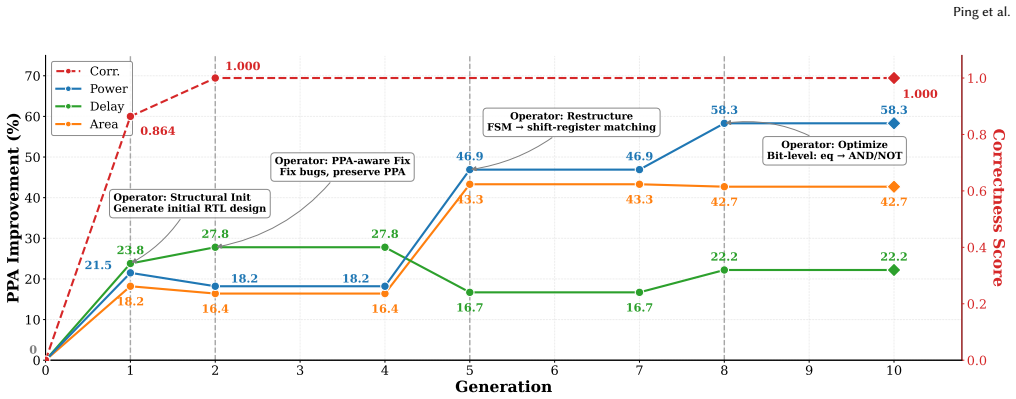
read the original abstract
LLM-based RTL code generation methods increasingly target both functional correctness and PPA quality, yet existing approaches universally decouple the two objectives, optimizing PPA only after correctness is fully achieved. Whether through sequential multi-agent pipelines, evolutionary search with binary correctness gates, or hierarchical reward dependencies, partially correct but architecturally promising candidates are systematically discarded. Moreover, existing methods reduce the multi-objective PPA space to a single scalar fitness, obscuring the trade-offs among area, delay, and power. To address these limitations, we propose COEVO, a co-evolutionary framework that unifies correctness and PPA optimization within a single evolutionary loop. COEVO formulates correctness as a continuous co-optimization dimension alongside area, delay, and power, enabled by an enhanced testbench that provides fine-grained scoring and detailed diagnostic feedback. An adaptive correctness gate with annealing allows PPA-promising but partially correct candidates to guide the search toward jointly optimal solutions. To preserve the full PPA trade-off structure, COEVO employs four-dimensional Pareto-based non-dominated sorting with configurable intra-level sorting, replacing scalar fitness without manual weight tuning. Evaluated on VerilogEval 2.0 and RTLLM 2.0, COEVO achieves 97.5\% and 94.5\% Pass@1 with GPT-5.4-mini, surpassing all agentic baselines across four LLM backbones, while attaining the best PPA on 43 out of 49 synthesizable RTLLM designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes COEVO, a co-evolutionary framework for LLM-based RTL generation that jointly optimizes functional correctness and PPA metrics within a single evolutionary loop. It uses an enhanced testbench for continuous fine-grained correctness scoring and diagnostics, an adaptive correctness gate with annealing to retain partially correct but PPA-promising candidates, and four-dimensional Pareto non-dominated sorting (with configurable intra-level sorting) to avoid scalar fitness reduction. On VerilogEval 2.0 and RTLLM 2.0, it reports 97.5% and 94.5% Pass@1 with GPT-5.4-mini, outperforming agentic baselines across four LLM backbones, plus best PPA on 43 of 49 synthesizable RTLLM designs.
Significance. If the empirical claims hold, the work would meaningfully advance automated hardware design by addressing the common decoupling of correctness and PPA objectives; the explicit preservation of the full 4D Pareto front without manual weighting is a clear methodological strength over prior scalar or sequential approaches.
major comments (2)
- [methodology / abstract] The central claim that the co-evolutionary loop produces jointly optimal correctness-PPA solutions depends on the enhanced testbench delivering unbiased fine-grained scores (abstract and methodology description). No validation, ablation, or independence check is supplied to demonstrate that scoring is uncorrelated with area/delay/power (e.g., via test-case selection, timeout behavior, or coverage heuristics that could implicitly reward simpler netlists). This is load-bearing for the headline 97.5%/94.5% Pass@1 and 43/49 PPA results.
- [experiments / results tables] Table reporting the 43/49 best-PPA designs and the Pass@1 numbers across backbones lacks statistical analysis, variance estimates, or ablation on the adaptive gate and 4D sorting components; without these, it is impossible to assess whether the reported gains are robust or sensitive to post-hoc choices in the evolutionary loop.
minor comments (2)
- [methodology] Notation for the four-dimensional Pareto sort and the annealing schedule of the adaptive gate should be formalized with explicit equations or pseudocode for reproducibility.
- [abstract / experiments] The abstract and results sections should clarify the exact definition of 'synthesizable' designs and the synthesis tool/flow used for PPA measurement.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and rigor of our work. We address the two major comments point-by-point below, agreeing with the need for additional validation and analysis, and outlining the revisions we will implement.
read point-by-point responses
-
Referee: [methodology / abstract] The central claim that the co-evolutionary loop produces jointly optimal correctness-PPA solutions depends on the enhanced testbench delivering unbiased fine-grained scores (abstract and methodology description). No validation, ablation, or independence check is supplied to demonstrate that scoring is uncorrelated with area/delay/power (e.g., via test-case selection, timeout behavior, or coverage heuristics that could implicitly reward simpler netlists). This is load-bearing for the headline 97.5%/94.5% Pass@1 and 43/49 PPA results.
Authors: We acknowledge that demonstrating the independence of the fine-grained correctness scores from PPA metrics is essential to support our central claims. The enhanced testbench was constructed with diverse test cases, timeout handling, and coverage metrics intended to avoid bias toward simpler designs, but we did not provide an explicit independence check in the initial submission. In the revised manuscript, we will include a dedicated analysis section that computes and reports correlation coefficients between correctness scores and each PPA metric (area, delay, power) across all evaluated designs. We will also add an ablation study on the testbench features to confirm they do not implicitly favor low-PPA solutions. This addresses the load-bearing nature of the claim. revision: yes
-
Referee: [experiments / results tables] Table reporting the 43/49 best-PPA designs and the Pass@1 numbers across backbones lacks statistical analysis, variance estimates, or ablation on the adaptive gate and 4D sorting components; without these, it is impossible to assess whether the reported gains are robust or sensitive to post-hoc choices in the evolutionary loop.
Authors: We agree that the experimental presentation would be strengthened by statistical analysis and component ablations. In the revised version, we will augment the results tables with variance estimates (standard deviations from multiple independent runs) for the Pass@1 metrics on both benchmarks and across the four LLM backbones. We will also add ablation experiments isolating the effects of the adaptive correctness gate and the 4D Pareto non-dominated sorting, reporting performance deltas when each is disabled. For the 43/49 PPA comparison, we will include statistical significance testing (e.g., paired t-tests or Wilcoxon tests) against baselines where possible. revision: yes
Circularity Check
No circularity: empirical framework on public benchmarks
full rationale
The paper proposes COEVO as a co-evolutionary framework that integrates correctness and PPA optimization via an enhanced testbench, adaptive gates, and 4D Pareto sorting. All reported results (97.5%/94.5% Pass@1, best PPA on 43/49 designs) are direct empirical measurements on fixed public benchmarks (VerilogEval 2.0, RTLLM 2.0) across multiple LLM backbones. No equations, derivations, or self-citations appear in the provided text that reduce any claimed outcome to a fitted parameter, self-defined quantity, or prior author result by construction. The testbench scoring is presented as an enabling component but is not shown to be internally fitted or self-referential; performance claims remain externally falsifiable on the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Armin Abdollahi, Saeid Shokoufa, Negin Ashrafi, Mehdi Kamal, and Massoud Pedram. 2026.HDLFORGE: A Two-Stage Multi-Agent Framework for Efficient Verilog Code Generation with Adaptive Model Escalation. arXiv:2603.04646
-
[2]
Jason Blocklove, Siddharth Garg, Ramesh Karri, and Hammond Pearce. 2023. Chip-Chat: Challenges and Opportunities in Conversational Hardware Design. In2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD). IEEE, 1–6
2023
-
[3]
Christiaan Baaij, Matthijs Kooijman, Jan Kuper, Arjan Boeijink, and Marco Gerards
Kaiyan Chang, Ying Wang, Haimeng Ren, Mengdi Wang, Shengwen Liang, Yinhe Han, Huawei Li, and Xiaowei Li. 2023.ChipGPT: How Far Are We from Natural Language Hardware Design. arXiv:2305.14019
-
[4]
ChipSeek: Optimizing Verilog Generation via EDA-Integrated Reinforcement Learning
Zhirong Chen, Kaiyan Chang, Zhuolin Li, Xinyang He, Chujie Chen, Cangyuan Li, Mengdi Wang, Haobo Xu, Yinhe Han, and Ying Wang. 2025.ChipSeek-R1: Generating Human-Surpassing RTL with LLM via Hierarchical Reward-Driven Reinforcement Learning. arXiv:2507.04736
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Fan Cui, Chenyang Yin, Kexing Zhou, Youwei Xiao, Guangyu Sun, Qiang Xu, Qipeng Guo, Yun Liang, Xingcheng Zhang, Dawn Song, and Dahua Lin. 2024. OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
-
[6]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and T. A. M. T. Meyarivan. 2002. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation6, 2 (2002), 182–197
2002
-
[7]
Chenhui Deng, Yun-Da Tsai, Guan-Ting Liu, Zhongzhi Yu, and Haoxing Ren
-
[8]
In2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD)
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation. In2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 1–9
-
[9]
ACE-RTL: When agentic context evolution meets RTL-specialized LLMs,
Chenhui Deng, Zhongzhi Yu, Guan-Ting Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2026.ACE-RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs. arXiv:2602.10218
-
[10]
Kevin Immanuel Gubbi, Marcus Halm, Sarbani Kumar, Arvind Sudarshan, Pa- van Dheeraj Kota, Mohammadnavid Tarighat, Avesta Sasan, and Houman Homay- oun. 2025. Prompting for Power: Benchmarking Large Language Models for Low-Power RTL Design Generation. In2025 ACM/IEEE 7th Symposium on Ma- chine Learning for CAD (MLCAD). IEEE, 1–7
2025
-
[11]
Chia-Tung Ho, Haoxing Ren, and Brucek Khailany. 2025. VerilogCoder: Au- tonomous Verilog Coding Agents with Graph-Based Planning and Abstract Syntax Tree (AST)-Based Waveform Tracing Tool. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 300–307
2025
-
[12]
2026.EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization
Wei-Po Hsin, Ren-Hao Deng, Yao-Ting Hsieh, En-Ming Huang, and Shih-Hao Hung. 2026.EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization. arXiv:2601.18067
-
[13]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. 2024.Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model. arXiv:2401.02051
-
[14]
Jiale Liu, Taiyu Zhou, and Tianqi Jiang. 2026.Veri-Sure: A Contract-A ware Multi- Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation. arXiv:2601.19747
-
[15]
Chipnemo: Domain- adapted llms for chip design,
Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinck- ney, Rongjian Liang, Jonah Alben, Himyanshu Anand, Sanmitra Banerjee, Ismet Bayraktaroglu, and Bonita Bhaskaran. 2023.ChipNemo: Domain-Adapted LLMs for Chip Design. arXiv:2311.00176
-
[16]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. Ver- ilogEval: Evaluating Large Language Models for Verilog Code Generation. In 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 1–8
2023
-
[17]
Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Xie
-
[18]
In2024 IEEE LLM Aided Design Workshop (LAD)
RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 1–5
-
[19]
Shang Liu, Yao Lu, Wenji Fang, Mengming Li, and Zhiyao Xie. 2024. OpenLLM- RTL: Open Dataset and Benchmark for LLM-Aided Design RTL Generation. In Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
-
[20]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model. In2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 722–727
2024
-
[21]
Kyungjun Min, Kyumin Cho, Junhwan Jang, and Seokhyeong Kang. 2026. REvolu- tion: An Evolutionary Framework for RTL Generation Driven by Large Language Models. In2026 31st Asia and South Pacific Design Automation Conference (ASP- DAC). IEEE, 282–288
2026
-
[22]
Betterv: Controlled verilog generation with discriminative guidance,
Zehua Pei, Hui-Ling Zhen, Mingxuan Yuan, Yu Huang, and Bei Yu. 2024.BetterV: Controlled Verilog Generation with Discriminative Guidance. arXiv:2402.03375
-
[23]
Nathaniel Pinckney, Christopher Batten, Mingjie Liu, Haoxing Ren, and Brucek Khailany. 2025. Revisiting VerilogEval: A Year of Improvements in Large- Language Models for Hardware Code Generation.ACM Transactions on Design Automation of Electronic Systems30, 6 (2025), 1–20
2025
-
[24]
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Heng Ping, Arijit Bhattacharjee, Peiyu Zhang, Shixuan Li, Wei Yang, Anzhe Cheng, Xiaole Zhang, Jesse Thomason, Ali Jannesari, Nesreen Ahmed, and Paul Bogdan. 2025.VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation. arXiv:2510.27617
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Heng Ping, Shixuan Li, Peiyu Zhang, Anzhe Cheng, Shukai Duan, Nikos Kanakaris, Xiongye Xiao, Wei Yang, Shahin Nazarian, Andrei Irimia, and Paul Bogdan. 2025. HDLCoRe: A Training-Free Framework for Mitigating Hallucina- tions in LLM-Generated HDL. In2025 IEEE International Conference on LLM-Aided Design (ICLAD). IEEE, 108–116
2025
-
[26]
2026.POET: Power-Oriented Evolutionary Tuning for LLM-Based RTL PPA Optimization
Heng Ping, Peiyu Zhang, Zhenkun Wang, Shixuan Li, Anzhe Cheng, Wei Yang, Paul Bogdan, and Shahin Nazarian. 2026.POET: Power-Oriented Evolutionary Tuning for LLM-Based RTL PPA Optimization. arXiv:2603.19333
-
[27]
2024.Evolution of Thought: Diverse and High-Quality Reasoning via Multi-Objective Optimization
Biqing Qi, Zhouyi Qian, Yiang Luo, Junqi Gao, Dong Li, Kaiyan Zhang, and Bowen Zhou. 2024.Evolution of Thought: Diverse and High-Quality Reasoning via Multi-Objective Optimization. arXiv:2412.07779
-
[28]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi
-
[29]
Mathematical Discoveries from Program Search with Large Language Models.Nature625, 7995 (2024), 468–475
2024
-
[30]
Kimia Tasnia, Alexander Garcia, Tasnuva Farheen, and Sazadur Rahman. 2025. VeriOpt: PPA-Aware High-Quality Verilog Generation via Multi-Role LLMs. In 2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 1–9
2025
-
[31]
Fu Teng, Miao Pan, Xuhong Zhang, Zhezhi He, Yiyao Yang, Xinyi Chai, Mengnan Qi, Liqiang Lu, and Jianwei Yin. 2025. VERIRL: Boosting the LLM-based Verilog Code Generation via Reinforcement Learning. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 1–9
2025
-
[32]
Kiran Thorat, Jiahui Zhao, Yaotian Liu, Amit Hasan, Hongwu Peng, Xi Xie, Bin Lei, and Caiwen Ding. 2025. LLM-VeriPPA: Power, Performance, and Area Optimization Aware Verilog Code Generation with Large Language Models. In 2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 1–7
2025
-
[33]
Yaoxiang Wang, Qi Shi, ShangZhan Li, Qingguo Hu, Xinyu Yin, Bo Guo, Xu Han, Maosong Sun, and Jinsong Su. 2026.VeriAgent: A Tool-Integrated Multi-Agent Sys- tem with Evolving Memory for PPA-A ware RTL Code Generation. arXiv:2603.17613
-
[34]
Yiting Wang, Guoheng Sun, Wanghao Ye, Gang Qu, and Ang Li. 2025.VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Ping et al. Generation. arXiv:2505.11849
-
[35]
2025.SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron- Inspired Symbolic Reasoning
Yiting Wang, Wanghao Ye, Ping Guo, Yexiao He, Ziyao Wang, Bowei Tian, Shwai He, Guoheng Sun, Ziqian Shen, Shaohan Chen, Anurag Srivastava, and Ang Li. 2025.SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron- Inspired Symbolic Reasoning. arXiv:2504.10369
-
[36]
Yangbo Wei, Zhen Huang, Lei He, Li Huang, Ting-Jung Lin, and Wei W. Xing
-
[37]
In 2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC)
VFlow: Discovering Optimal Agentic Workflows for Verilog Generation. In 2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 355–361
2026
-
[38]
Large language models (llms) for electronic design automation (eda),
Kangwei Xu, Denis Schwachhofer, Jason Blocklove, Ilia Polian, Peter Domanski, Dirk Pflüger, Siddharth Garg, Ramesh Karri, Ozgur Sinanoglu, Johann Knechtel, and Zhizi Zhao. 2025.Large Language Models (LLMs) for Electronic Design Automation (EDA). arXiv:2508.20030
-
[39]
Large language model for verilog code generation: Literature review and the road ahead,
Guang Yang, Wei Zheng, Xiang Chen, Dong Liang, Peng Hu, Yukui Yang, Shao- hang Peng, Zhi Li, Jian Feng, Xin Wei, and Kunyuan Sun. 2025.Large Lan- guage Model for Verilog Code Generation: Literature Review and the Road Ahead. arXiv:2512.00020
-
[40]
Wei Yang, Muyan Weng, Jiacheng Pang, Defu Cao, Heng Ping, Peiyu Zhang, Shixuan Li, Yue Zhao, Qiang Yang, Mengdi Wang, et al. 2025. Toward Evolution- ary Intelligence: LLM-based Agentic Systems with Multi-Agent Reinforcement Learning.A vailable at SSRN 5819182(2025)
2025
-
[41]
Yiyao Yang, Fu Teng, Pengju Liu, Mengnan Qi, Chenyang Lv, Ji Li, Xuhong Zhang, and Zhezhi He. 2025. HAVEN: Hallucination-Mitigated LLM for Verilog Code Generation Aligned with HDL Engineers. In2025 Design, Automation & Test in Europe Conference (DATE). IEEE, 1–7
2025
-
[42]
Xufeng Yao, Yiwen Wang, Xing Li, Yingzhao Lian, Ran Chen, Lei Chen, Mingxuan Yuan, Hong Xu, and Bei Yu. 2024. RTLRewriter: Methodologies for Large Models Aided RTL Code Optimization. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–7
2024
-
[43]
2025.QiMeng-SALV: Signal-A ware Learning for Verilog Code Generation
Yang Zhang, Rui Zhang, Jiaming Guo, Lei Huang, Di Huang, Yunpu Zhao, Shuyao Cheng, Pengwei Jin, Chongxiao Li, Zidong Du, Xing Hu, and Yunji Chen. 2025.QiMeng-SALV: Signal-A ware Learning for Verilog Code Generation. arXiv:2510.19296
-
[44]
Yang Zhao, Di Huang, Chongxiao Li, Pengwei Jin, Muxin Song, Yinan Xu, Ziyuan Nan, Mingzhe Gao, Tuo Ma, Lei Qi, and Yansong Pan. 2025. CodeV: Empow- ering LLMs with HDL Generation Through Multi-Level Summarization.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems(2025)
2025
-
[45]
Yujie Zhao, Hejia Zhang, Hanxian Huang, Zhongming Yu, and Jishen Zhao. 2025. MAGE: A Multi-Agent Engine for Automated RTL Code Generation. In2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 1–7
2025
-
[46]
Qimeng-codev-r1: Reasoning-enhanced verilog generation.arXiv preprint arXiv:2505.24183,
Yaoyu Zhu, Di Huang, Hanqi Lyu, Xiaoyun Zhang, Chongxiao Li, Wenxuan Shi, Yutong Wu, Jie Mu, Jiahao Wang, Yang Zhao, and Pengwei Jin. 2025.QiMeng- CodeV-R1: Reasoning-Enhanced Verilog Generation. arXiv:2505.24183
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.