Recognition: unknown
Atropos: Improving Cost-Benefit Trade-off of LLM-based Agents under Self-Consistency with Early Termination and Model Hotswap
Pith reviewed 2026-05-10 10:54 UTC · model grok-4.3
The pith
Atropos predicts failing self-consistent LLM agent runs at their midpoint using a graph neural network and hotswaps context to a larger model, converting many failures into successes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
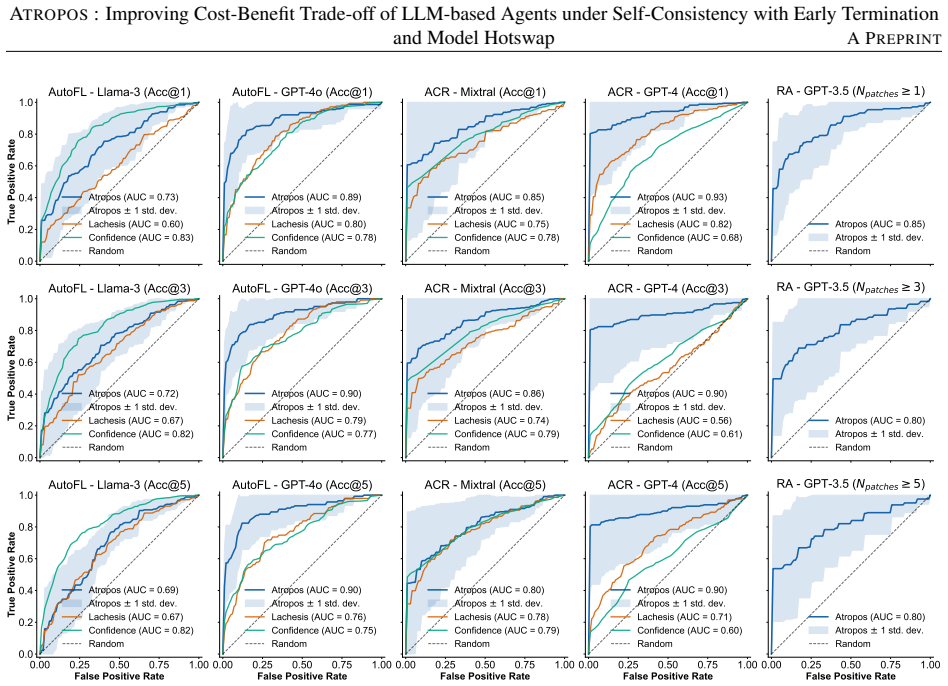
Merging multiple self-consistent inference paths into a graph and training a graph convolutional network on structural properties allows accurate prediction of eventual failure at the midpoint of inference; hotswapping the context to a more capable model for predicted failures converts up to 27.57 percent of them into successes and delivers 74.35 percent of closed-LLM performance at 23.9 percent of the cost.
What carries the argument
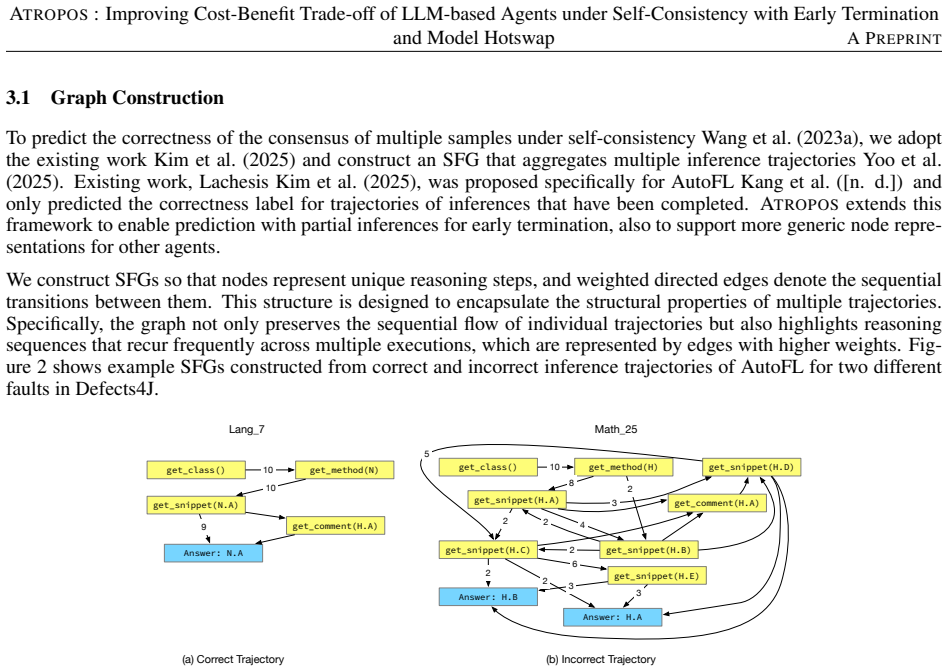
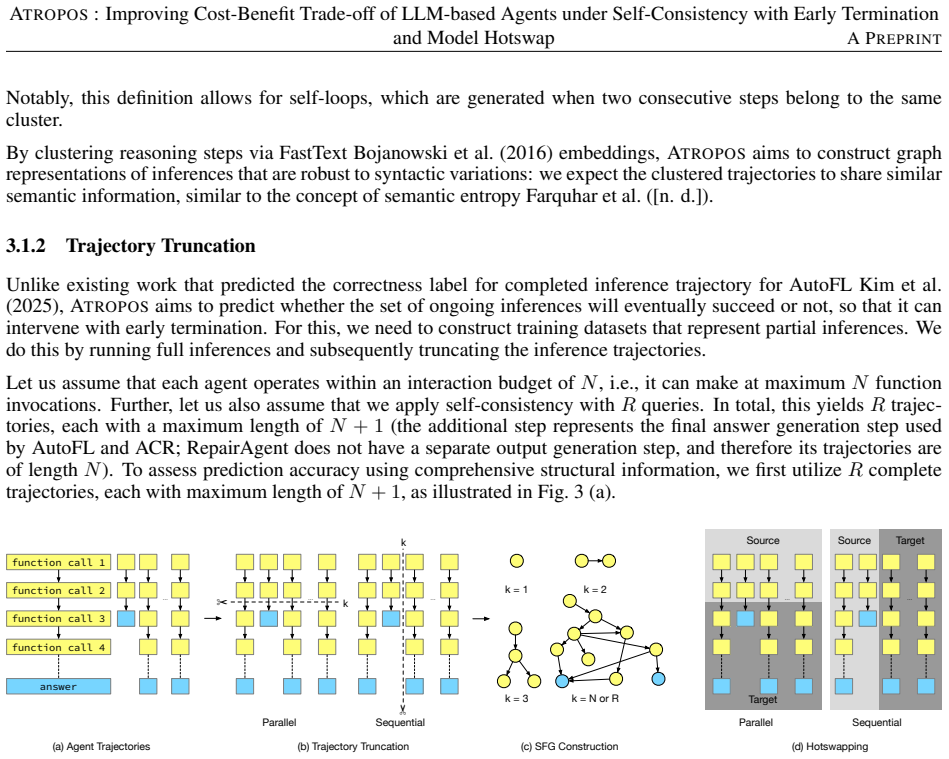
A graph convolutional network that takes a merged graph of parallel self-consistent inference paths as input and outputs a prediction of eventual success or failure, used to decide whether to continue on the source small model or hotswap the stateless context to a target large model.
If this is right
- Most agent runs can complete on inexpensive small models while only the predicted failures escalate to expensive large models.
- Up to 27.57 percent of inferences that would have failed are recovered through mid-inference model switching.
- Total inference cost for self-consistency agents drops to roughly one-quarter of the all-large-model baseline.
- Early termination avoids completing doomed paths that would otherwise consume full compute budget.
Where Pith is reading between the lines
- The same graph-of-paths representation could be used to detect other kinds of agent inefficiency beyond outright failure.
- Hybrid local-cloud deployments become more practical if context migration works reliably across model families.
- Patterns learned by the GCN might later guide better initial prompting or path-selection heuristics.
- The technique may extend to other multi-sample methods such as tree-of-thoughts or debate-style agents.
Load-bearing premise
The graph convolutional network can forecast final failure with 0.85 accuracy at the midpoint of an inference, and migrating the ongoing context to a different model does not reduce the agent's effectiveness.
What would settle it
An evaluation in which the midpoint GCN accuracy falls below 0.7 or in which hotswapped inferences achieve no higher success rate than simply continuing on the small model.
Figures





read the original abstract
Open-weight Small Language Models(SLMs) can provide faster local inference at lower financial cost, but may not achieve the same performance level as commercial Large Language Models (LLMs) that are orders of magnitudes larger. Consequently, many of the latest applications of LLMs, such as software engineering agents, tend to be evaluated on larger models only, leaving the issue of improving the cost-benefit trade-off of such applications neglected. This paper proposes Atropos, a predictive early-termination analysis and hotswap technique that aims to improve the cost-benefit trade-off for LLM-based agents that use self-consistency. The core component of ATROPOS is a predictive model based on structural properties of LLM inferences: after merging multiple agentic inference paths into a graph representation, ATROPOS uses Graph Convolutional Network (GCN) to predict whether an ongoing inference will eventually succeed or not. If an agentic task instance running on the source LLM is predicted to fail, ATROPOS subsequently performs hotswapping, i.e., migrating the on-going inference context onto the more capable target LLM: this is feasible because LLM contexts are stateless. An empirical evaluation of ATROPOS using three recent LLM-based agents shows that ATROPOS can predict early termination of eventually failing inferences with the accuracy of 0.85 at the midpoint of the inference. Hotswapping LLMs for such inferences can convert up to 27.57% of them to be successful. Consequently, ATROPOS achieves 74.35% of the performance of closed LLMs with as low as only 23.9% of the cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Atropos, a technique to improve the cost-benefit trade-off for LLM-based agents that rely on self-consistency. It constructs a graph from multiple inference paths, applies a Graph Convolutional Network (GCN) to predict at the midpoint whether an ongoing run on a small language model will eventually fail, and hotswaps the stateless context to a larger target LLM if failure is predicted. Evaluation across three recent LLM-based agents reports 0.85 prediction accuracy, conversion of up to 27.57% of predicted failures into successes, and overall achievement of 74.35% of closed-LLM performance at 23.9% of the cost.
Significance. If the empirical claims hold, Atropos offers a concrete mechanism for selectively invoking expensive large models only on trajectories predicted to fail, which could meaningfully reduce the operational cost of agentic LLM applications in software engineering and similar domains while preserving most of their capability. The graph-based structural prediction on merged self-consistency paths is a distinctive technical contribution relative to simpler early-exit heuristics.
major comments (2)
- [Abstract and §3] Abstract and §3 (hotswap mechanism): The central performance claim (74.35% of closed-LLM success at 23.9% cost) rests on the assumption that migrating the partial inference context from the source LLM to the target LLM converts failures without loss of effectiveness. Because different LLMs can produce divergent continuations from the same prefix (especially when prior tool calls or observations are included), the manuscript must include an ablation that compares success rates of hotswapped runs against runs initiated natively on the target LLM from the start; without this, the 27.57% conversion figure cannot be attributed solely to model capability.
- [§4] §4 (evaluation): The reported 0.85 GCN accuracy at the midpoint and the aggregate 74.35%/23.9% cost-benefit numbers are presented without visible details on the three specific agents, the self-consistency sampling parameters (k, temperature), the task benchmarks, number of trials per condition, variance across runs, or statistical significance tests. These omissions make it impossible to assess whether the GCN predictor generalizes or whether the headline trade-off is robust.
minor comments (1)
- Define all acronyms (GCN, SLM, etc.) on first use and ensure figure captions for the inference-graph construction are self-contained.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (hotswap mechanism): The central performance claim (74.35% of closed-LLM success at 23.9% cost) rests on the assumption that migrating the partial inference context from the source LLM to the target LLM converts failures without loss of effectiveness. Because different LLMs can produce divergent continuations from the same prefix (especially when prior tool calls or observations are included), the manuscript must include an ablation that compares success rates of hotswapped runs against runs initiated natively on the target LLM from the start; without this, the 27.57% conversion figure cannot be attributed solely to model capability.
Authors: We agree that an explicit ablation is required to isolate the contribution of the target model's capability from any potential effects of context migration. Although the mechanism is justified by the stateless property of LLM contexts, we acknowledge that model-specific differences in continuation could exist. In the revised manuscript we have added the requested ablation study to §3, comparing success rates of hotswapped runs against equivalent runs started natively on the target LLM. The abstract has been updated to reference this new analysis, allowing the 27.57% conversion figure to be attributed to the model switch. revision: yes
-
Referee: [§4] §4 (evaluation): The reported 0.85 GCN accuracy at the midpoint and the aggregate 74.35%/23.9% cost-benefit numbers are presented without visible details on the three specific agents, the self-consistency sampling parameters (k, temperature), the task benchmarks, number of trials per condition, variance across runs, or statistical significance tests. These omissions make it impossible to assess whether the GCN predictor generalizes or whether the headline trade-off is robust.
Authors: We accept that the original presentation of results omitted necessary experimental details. The revised §4 now supplies the identities of the three agents, the exact self-consistency parameters (k and temperature), the task benchmarks, the number of trials per condition, variance statistics across runs, and the outcomes of statistical significance tests. These additions permit evaluation of the GCN predictor's generalizability and the robustness of the reported cost-benefit trade-off. revision: yes
Circularity Check
Empirical proposal with no derivation chain or fitted predictions by construction
full rationale
The paper describes an empirical system (Atropos) that trains a GCN on merged inference-path graphs to predict eventual success/failure at the midpoint, then reports measured accuracy (0.85) and cost-performance gains from running the full pipeline on three agents. No equations, uniqueness theorems, or ansatzes are presented whose outputs are forced by their own inputs; the 74.35% performance / 23.9% cost figures are direct experimental outcomes, not renamings or self-referential fits. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Better Patching Using LLM Prompting, via Self-Consistency. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1742–1746. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tom´as Mikolov
2023
-
[2]
Enriching word vectors with subword information.arXiv preprint arXiv:1607.04606, 2016
Enriching Word Vectors with Subword Information.CoRRabs/1607.04606 (2016). arXiv:1607.04606http://arxiv.org/abs/1607.04606 Islem Bouzenia, Premkumar Devanbu, and Michael Pradel
-
[3]
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair . In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, Los Alamitos, CA, USA, 2188–2200.https://doi.org/10.1109/ICSE55347.2025.00157 Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, et al. 2024a. INSIDE: LLMs’ internal states retain the power of hallu...
-
[4]
InProceedings of the Second International Workshop on Large Language Models for Code (LLM4Code 2025)
COSMosFL: Ensemble of Small Language Models for Fault Localisation. InProceedings of the Second International Workshop on Large Language Models for Code (LLM4Code 2025). Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, et al
2025
-
[5]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024). Jinwen He, Yujia Gong, Zijin Lin, Cheng’an Wei, Yue Zhao, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
LLM Factoscope: Uncovering LLMs’ Factual Discernment through Measuring Inner States. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 10218–10230.https://doi.org/10.18653/v1/2024.findings-acl.608 Albert Q. Jiang, Alexan...
-
[7]
Mixtral of Experts. arXiv:cs.LG/2401.04088https://arxiv.org/abs/2401.04088 Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
A Quantitative and Qualitative Evalu- ation of LLM-Based Explainable Fault Localization,
SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66 16 ATROPOS: Improving Cost-Benefit Trade-off of LLM-based Agents under Self-Consistency with Early Termination and Model HotswapA PREPRINT Sungmin Kang, Gabin An, and Shin Yoo. [n....
-
[9]
InProceedings of the 6th International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2025)
Lachesis: Predicting LLM Inference Accuracy using Structural Properties of Reasoning Paths. InProceedings of the 6th International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2025). Thomas N. Kipf and Max Welling
2025
-
[10]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-Supervised Classification with Graph Convolutional Networks.CoRR abs/1609.02907 (2016). Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, et al
work page internal anchor Pith review arXiv 2016
-
[11]
GPT-4 Technical Report. arXiv:cs.CL/2303.08774https://arxiv.org/abs/2303.08774 Guillem Ram ´ırez, Alexandra Birch, and Ivan Titov
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Evaluating Agent-based Program Repair at Google.https://doi.org/10.48550/arXiv.2501.07531arXiv:cs/2501.07531 Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, et al
-
[13]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927 (2024). Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, et al
work page internal anchor Pith review arXiv 2024
-
[14]
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 14379–14391.https://doi.org/10.18653/v1/2024.findings-acl.854 Xingya...
-
[15]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
OpenHands: An Open Platform for AI Software Developers as Generalist Agents. InThe Thirteenth International Conference on Learning Represen- tations.https://openreview.net/forum?id=OJd3ayDDoF Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, et al. 2023a. Self-Consistency Improves Chain of Thought Reasoning in Language Models.CoRRabs/2203.11171 (2...
work page Pith review arXiv 2023
-
[16]
IEEE Transactions on Software Engineering42, 8 (August 2016),
A Survey on Software Fault Localization. IEEE Transactions on Software Engineering42, 8 (August 2016),
2016
-
[17]
InProceedings of the International Conference on Learning Representation (ICLR 2023)
ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the International Conference on Learning Representation (ICLR 2023). Shin Yoo, Robert Feldt, Somin Kim, and Naryeong Kim
2023
-
[18]
Capturing Semantic Flow of ML-based Systems. In Proceedings of the ACM International Conference on the Foundations of Software Engineering - Ideas, Visions and Reflections Track (FSE 2025). Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024a. CodeAgent: Enhancing Code Generation with Tool- Integrated Agent Systems for Real-World Repo-level Coding ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.