Recognition: unknown
Feedback-Driven Execution for LLM-Based Binary Analysis
Pith reviewed 2026-05-10 10:37 UTC · model grok-4.3
The pith
Structuring LLM binary analysis as a feedback-driven execution process with a dynamic forest of agents enables scalable vulnerability detection in firmware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by replacing one-pass execution with a feedback-driven loop of reasoning, action, and observation, and by decomposing the work into a Dynamic Forest of Agents that coordinates parallel paths while limiting context size, LLM-based binary analysis becomes both scalable and more effective at finding vulnerabilities across diverse types.
What carries the argument
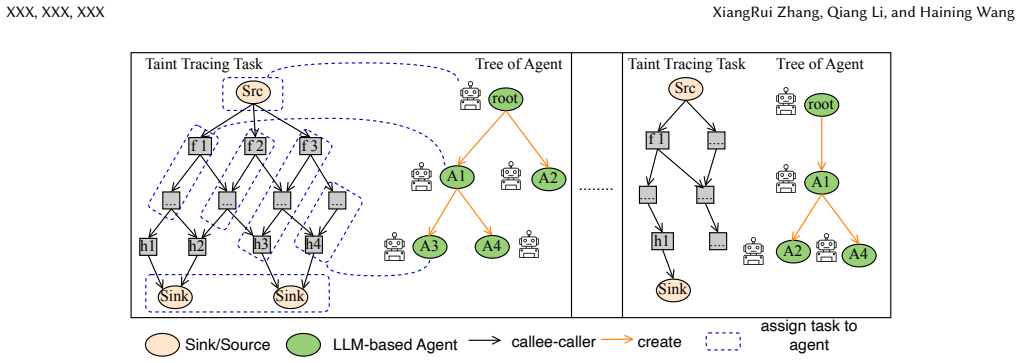
The Dynamic Forest of Agents (FoA), a decomposed execution model that dynamically coordinates parallel exploration while bounding per-agent context inside the reasoning-action-observation loop.
If this is right
- Analysis can adapt its path based on intermediate tool observations instead of a single static representation.
- Long-horizon multi-path exploration remains feasible without context overflow.
- Broader coverage of vulnerability types is achieved compared with prior one-pass LLM methods.
- Scalable application to thousands of real firmware binaries is possible while preserving usable precision.
Where Pith is reading between the lines
- The same interleaved loop could be applied to other code-analysis domains such as malware classification or protocol reverse engineering.
- Combining the agent forest with existing static-analysis tools might further improve the quality of observations fed back to the model.
- Adoption could lower the volume of manual expert review needed for initial screening of embedded-device firmware.
Load-bearing premise
The 3,457 firmware binaries and the vulnerability labels used to compute the 72.3 percent precision represent unbiased samples of real-world firmware without hidden selection effects or measurement biases.
What would settle it
An independent re-audit of the reported vulnerabilities that finds the true precision substantially below 72 percent, or a fresh run on a comparable but independently chosen set of firmware binaries that recovers far fewer unique affected binaries.
Figures







read the original abstract
Binary analysis increasingly relies on large language models (LLMs) to perform semantic reasoning over complex program behaviors. However, existing approaches largely adopt a one-pass execution paradigm, where reasoning operates over a fixed program representation constructed by static analysis tools. This formulation limits the ability to adapt exploration based on intermediate results and makes it difficult to sustain long-horizon, multi-path analysis under constrained context. We present FORGE, a system that rethinks LLM-based analysis as a feedback-driven execution process. FORGE interleaves reasoning and tool interaction through a reasoning-action-observation loop, enabling incremental exploration and evidence construction. To address the instability of long-horizon reasoning, we introduce a Dynamic Forest of Agents (FoA), a decomposed execution model that dynamically coordinates parallel exploration while bounding per-agent context. We evaluate FORGE on 3,457 real-world firmware binaries. FORGE identifies 1,274 vulnerabilities across 591 unique binaries, achieving 72.3% precision while covering a broader range of vulnerability types than prior approaches. These results demonstrate that structuring LLM-based analysis as a decomposed, feedback-driven execution system enables both scalable reasoning and high-quality outcomes in long-horizon tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FORGE, a system that reframes LLM-based binary analysis as a feedback-driven execution process using a reasoning-action-observation loop and a Dynamic Forest of Agents (FoA) to coordinate parallel exploration while bounding context. It evaluates the approach on 3,457 real-world firmware binaries, claiming identification of 1,274 vulnerabilities across 591 unique binaries at 72.3% precision with broader vulnerability-type coverage than prior methods.
Significance. If the evaluation methodology proves sound, the work could meaningfully advance LLM applications in security by showing how decomposed, adaptive agent coordination enables scalable long-horizon analysis on real firmware, addressing context-window and instability issues that limit one-pass static approaches. The scale of the binary corpus is a positive empirical contribution.
major comments (1)
- [Evaluation] Evaluation section (and abstract): The central performance claim of 72.3% precision on 1,274 vulnerabilities lacks any description of how ground truth was established, how false positives were measured, what labeling criteria or oracles (e.g., CVE matching, dynamic confirmation, expert review) were used, or whether post-hoc filtering occurred. Firmware binaries have no obvious oracles, so this omission makes the precision metric and the broader-coverage claim unverifiable and incomparable to prior work.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our work in advancing scalable LLM-based binary analysis. We address the major comment below and will revise the manuscript to improve transparency in the evaluation.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): The central performance claim of 72.3% precision on 1,274 vulnerabilities lacks any description of how ground truth was established, how false positives were measured, what labeling criteria or oracles (e.g., CVE matching, dynamic confirmation, expert review) were used, or whether post-hoc filtering occurred. Firmware binaries have no obvious oracles, so this omission makes the precision metric and the broader-coverage claim unverifiable and incomparable to prior work.
Authors: We agree that the manuscript does not provide sufficient detail on how ground truth was established or how the 72.3% precision was computed. This is a valid and important observation, as the lack of obvious oracles in firmware binaries makes such transparency necessary for verification and comparison to prior work. In the current version, the Evaluation section reports the aggregate results and claims but omits the required methodological description. We will revise the paper by adding a dedicated subsection in the Evaluation section (and updating the abstract for consistency) that fully describes the ground truth process. This will include the labeling criteria, the specific oracles and verification steps used (covering examples such as CVE matching, dynamic confirmation, and expert review), the approach to measuring false positives, and explicit confirmation that no post-hoc filtering occurred. These additions will render the precision metric and broader-coverage claim verifiable without changing the reported numbers. revision: yes
Circularity Check
No circularity: empirical results independent of any derivation chain
full rationale
The paper describes FORGE as a feedback-driven LLM analysis system using a reasoning-action-observation loop and Dynamic Forest of Agents, then reports empirical outcomes on 3,457 firmware binaries (1,274 vulnerabilities at 72.3% precision). No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described claims. The central results are presented as direct measurements from evaluation rather than quantities derived from or equivalent to the authors' inputs by construction. This is a standard systems-evaluation paper whose claims do not reduce to the listed circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Dynamic Forest of Agents (FoA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Marcel Busch, Aravind Machiry, Chad Spensky, Giovanni Vigna, Christopher Kruegel, and Mathias Payer. 2023. Teezz: Fuzzing trusted applications on cots android devices. In2023 IEEE Symposium on Secu- rity and Privacy (SP). IEEE, 1204–1219
2023
-
[2]
Daming D Chen, Maverick Woo, David Brumley, and Manuel Egele
-
[3]
Towards automated dynamic analysis for linux-based embedded firmware.. InNDSS
-
[4]
Libo Chen, Yanhao Wang, Quanpu Cai, Yunfan Zhan, Hong Hu, Ji- aqi Linghu, Qinsheng Hou, Chao Zhang, Haixin Duan, and Zhi Xue
-
[5]
In30th USENIX Security Symposium (USENIX Security 21)
Sharing more and checking less: Leveraging common input key- words to detect bugs in embedded systems. In30th USENIX Security Symposium (USENIX Security 21). 303–319
-
[6]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou
-
[7]
Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128(2023)
work page internal anchor Pith review arXiv 2023
-
[8]
Xiang Chen, Chengfeng Ye, Anshunkang Zhou, and Charles Zhang
-
[9]
ClearAgent: Agentic Binary Analysis for Effective Vulnerabil- ity Detection. InProceedings of the 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages (LMPL 2025), co-located with ICFP/SPLASH 2025. ACM, Singapore, 130–137. doi:10.1145/3759425.3763397
-
[10]
Vitaly Chipounov, Volodymyr Kuznetsov, and George Candea. 2011. S2E: A Platform for In-Vivo Multi-Path Analysis of Software Systems. InProceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS XVI). ACM, New York, NY, USA, 265–278. doi:10.1145/1950365.1950396
-
[11]
Jake Christensen, Ionut Mugurel Anghel, Rob Taglang, Mihai Chiroiu, and Radu Sion. 2020. {DECAF}: Automatic, adaptive de-bloating and hardening of{COTS}firmware. In29th USENIX Security Symposium (USENIX Security 20). 1713–1730
2020
-
[12]
Emilio Coppa, Heng Yin, and Camil Demetrescu. 2022. Symfusion: hy- brid instrumentation for concolic execution. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12
2022
-
[13]
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceed- ings of the 32nd ACM SIGSOFT international symposium on software testing and analysis. 423–435
2023
- [14]
-
[15]
Xiaotao Feng, Ruoxi Sun, Xiaogang Zhu, Minhui Xue, Sheng Wen, Dongxi Liu, Surya Nepal, and Yang Xiang. 2021. Snipuzz: Black-box fuzzing of iot firmware via message snippet inference. InProceedings of the 2021 ACM SIGSAC conference on computer and communications security. 337–350
2021
-
[16]
accessible 2024.Detect common bug classes formally known as Common Weakness Enumerations (CWEs)
Fraunhofer FKIE. accessible 2024.Detect common bug classes formally known as Common Weakness Enumerations (CWEs)
2024
-
[17]
Wil Gibbs, Arvind S Raj, Jayakrishna Menon Vadayath, Hui Jun Tay, Justin Miller, Akshay Ajayan, Zion Leonahenahe Basque, Audrey Dutcher, Fangzhou Dong, Xavier Maso, et al. 2024. Operation mango: Scalable discovery of {Taint-Style} vulnerabilities in binary firmware services. In33rd USENIX Security Symposium (USENIX Security 24). 7123–7139
2024
-
[18]
HyungSeok Han, JeongOh Kyea, Yonghwi Jin, Jinoh Kang, Brian Pak, and Insu Yun. 2023. Queryx: Symbolic query on decompiled code for finding bugs in COTS binaries. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 3279–3295
2023
- [19]
-
[20]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review arXiv 2023
-
[21]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Sid- dhartha Sen. 2023. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 919–931
2023
- [22]
-
[23]
Wenqiang Li, Jiameng Shi, Fengjun Li, Jingqiang Lin, Wei Wang, and Le Guan. 2022. 𝜇AFL: non-intrusive feedback-driven fuzzing for micro- controller firmware. InProceedings of the 44th International Conference on Software Engineering. 1–12
2022
- [24]
-
[25]
Puzhuo Liu, Chengnian Sun, Yaowen Zheng, Xuan Feng, Chuan Qin, Yuncheng Wang, Zhenyang Xu, Zhi Li, Peng Di, Yu Jiang, et al. 2025. Llm-powered static binary taint analysis.ACM Transactions on Soft- ware Engineering and Methodology34, 3 (2025), 1–36
2025
-
[26]
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. 2025. Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25). ACM, New York, NY, USA. doi:10.114...
-
[27]
2023.Copilot: The AI developer tool
Microsoft Org. 2023.Copilot: The AI developer tool
2023
-
[28]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Mor- ris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
-
[29]
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2023. Examining zero-shot vulnerability repair with large language models. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2339–2356
2023
- [30]
-
[31]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. 2023. Can large language models reason about program invari- ants?. InInternational Conference on Machine Learning. PMLR, 27496– 27520
2023
-
[32]
Sebastian Poeplau and Aurélien Francillon. 2020. Symbolic execution with {SymCC}: Don’t interpret, compile!. In29th USENIX Security Symposium (USENIX Security 20). 181–198
2020
-
[33]
Nilo Redini, Aravind Machiry, Ruoyu Wang, Chad Spensky, Andrea Continella, Yan Shoshitaishvili, Christopher Kruegel, and Giovanni Vigna. 2020. Karonte: Detecting insecure multi-binary interactions in embedded firmware. In2020 IEEE Symposium on Security and Privacy (SP). IEEE, 1544–1561
2020
-
[34]
Tobias Scharnowski, Nils Bars, Moritz Schloegel, Eric Gustafson, Mar- ius Muench, Giovanni Vigna, Christopher Kruegel, Thorsten Holz, and Ali Abbasi. 2022. Fuzzware: Using precise {MMIO} modeling for effective firmware fuzzing. In31st USENIX Security Symposium (USENIX Security 22). 1239–1256
2022
-
[35]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551. XXX, XXX, XXX XiangRui Zhang, Qiang Li, and Haining Wang
2023
-
[36]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems
2023
-
[37]
Nick Stephens, John Grosen, Christopher Salls, Andrew Dutcher, Ruoyu Wang, Jacopo Corbetta, Yan Shoshitaishvili, Christopher Kruegel, and Giovanni Vigna. 2016. Driller: Augmenting fuzzing through selective symbolic execution.. InNDSS, Vol. 16. 1–16
2016
-
[38]
Bogdan Alexandru Stoica, Utsav Sethi, Yiming Su, Cyrus Zhou, Shan Lu, Jonathan Mace, Madanlal Musuvathi, and Suman Nath. 2024. If At First You Don’t Succeed, Try, Try, Again. . . ? Insights and LLM- Informed Tooling for Detecting Retry Bugs in Software Systems. In Proceedings of the 30th ACM Symposium on Operating Systems Principles (SOSP ’24). ACM, New Y...
-
[39]
Chengpeng Wang, Wuqi Zhang, Zian Su, Xiangzhe Xu, and Xiangyu Zhang. 2024. Sanitizing large language models in bug detection with data-flow. InFindings of the Association for Computational Linguistics: EMNLP 2024. 3790–3805
2024
-
[40]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
2024
-
[41]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sha- ran Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self- consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171(2022)
work page Pith review arXiv 2022
-
[42]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompt- ing elicits reasoning in large language models.Advances in Neural Information Processing Systems35 (2022), 24824–24837
2022
-
[43]
David A. Wheeler. accessible 2024.Flawfinder is a simple program that scans C/C++ source code and reports potential security flaws
2024
- [44]
- [45]
-
[46]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2023. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864(2023)
work page internal anchor Pith review arXiv 2023
-
[47]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caim- ing Xiong, Victor Zhong, and Tao Yu. 2024. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environ- ments. arXiv:2404.07972 [cs.AI]...
work page internal anchor Pith review arXiv 2024
-
[48]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent- computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[49]
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao
-
[50]
arXiv preprint arXiv:2306.14898 , year=
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback. arXiv:2306.14898 [cs.CL] https://arxiv.org/ abs/2306.14898
-
[51]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Delib- erate problem solving with large language models.arXiv preprint arXiv:2305.10601(2023)
work page internal anchor Pith review arXiv 2023
-
[52]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Insu Yun, Sangho Lee, Meng Xu, Yeongjin Jang, and Taesoo Kim. 2018. {QSYM}: A practical concolic execution engine tailored for hybrid fuzzing. In27th USENIX Security Symposium (USENIX Security 18). 745–761
2018
-
[54]
type": "CWE-78
Yaowen Zheng, Ali Davanian, Heng Yin, Chengyu Song, Hongsong Zhu, and Limin Sun. 2019. {FIRM-AFL}:{High-Throughput} greybox fuzzing of {IoT} firmware via augmented process emulation. In28th USENIX Security Symposium (USENIX Security 19). 1099–1114. A System Implementation Table 11.Tools Available to Agents. Tool Description Radare2Tool Provides Radare2 co...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.