Recognition: unknown
DiscoTrace: Representing and Comparing Answering Strategies of Humans and LLMs in Information-Seeking Question Answering
Pith reviewed 2026-05-10 11:33 UTC · model grok-4.3
The pith
Different human communities employ varied rhetorical strategies in answering questions, but LLMs produce uniform and broader responses despite specific prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
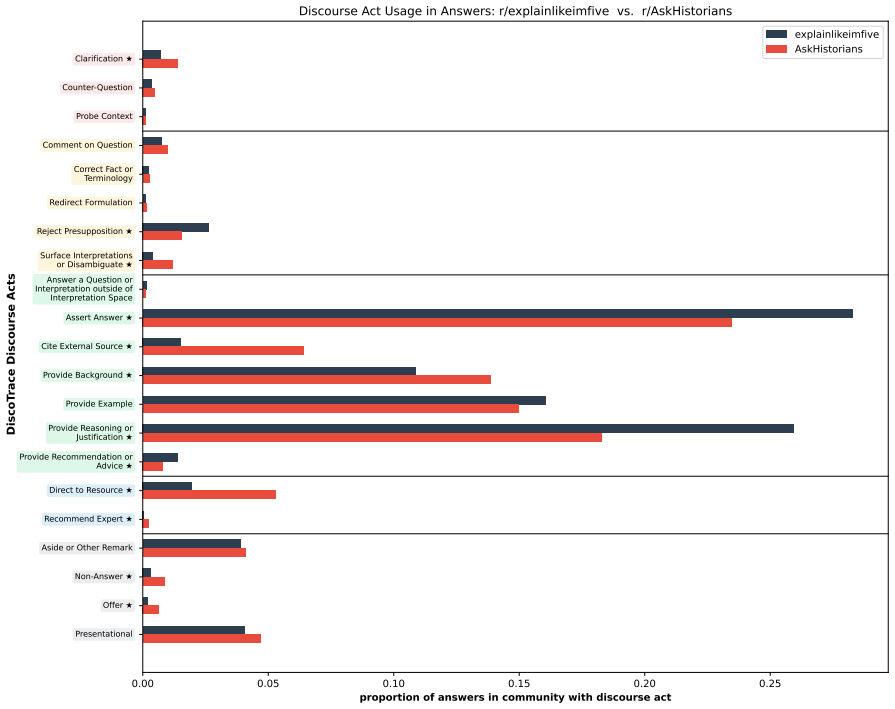
The central discovery is that applying the DiscoTrace method to answers from diverse human communities demonstrates varied rhetorical preferences, whereas LLMs consistently lack this diversity and favor addressing a wider set of question interpretations, even under prompts designed to replicate human community guidelines.
What carries the argument
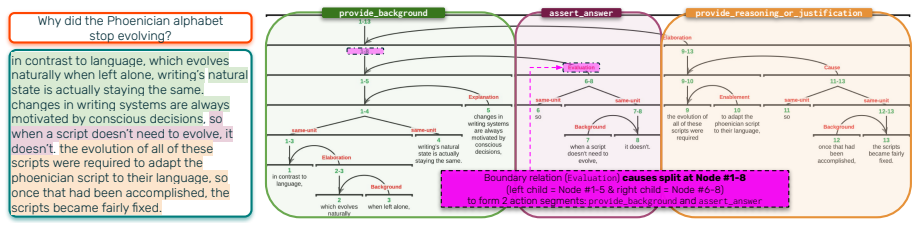
DiscoTrace, which represents answers as a sequence of question-related discourse acts paired with interpretations of the original question, annotated on rhetorical structure theory parses.
If this is right
- Human communities display diverse preferences in constructing answers to information-seeking questions.
- LLMs do not show rhetorical diversity in their answers despite prompts to mimic specific human guidelines.
- LLMs systematically choose breadth by addressing interpretations that human answerers avoid.
- The findings can inform the creation of LLM answerers that use context-informed strategies.
Where Pith is reading between the lines
- LLMs could be fine-tuned using examples from specific communities to better match their rhetorical styles.
- Broader adoption of such analysis might reveal why LLMs tend toward comprehensive but less focused responses.
- Developers might experiment with DiscoTrace to evaluate and adjust prompt strategies for more human-like variation.
Load-bearing premise
The assumption that discourse act annotations on RST parses consistently and accurately reflect the rhetorical strategies across human communities and LLMs without bias or parsing errors.
What would settle it
Finding that repeated annotations by different people on the same answers yield substantially different discourse act sequences, or that LLMs can be prompted to match human diversity levels as measured by DiscoTrace.
Figures








read the original abstract
We introduce DiscoTrace, a method to identify the rhetorical strategies that answerers use when responding to information-seeking questions. DiscoTrace represents answers as a sequence of question-related discourse acts paired with interpretations of the original question, annotated on top of rhetorical structure theory parses. Applying DiscoTrace to answers from nine different human communities reveals that communities have diverse preferences for answer construction. In contrast, LLMs do not exhibit rhetorical diversity in their answers, even when prompted to mimic specific human community answering guidelines. LLMs also systematically opt for breadth, addressing interpretations of questions that human answerers choose not to address. Our findings can guide the development of pragmatic LLM answerers that consider a range of strategies informed by context in QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiscoTrace, a method that represents answers to information-seeking questions as sequences of question-related discourse acts (annotated on RST parses) paired with specific interpretations of the original question. Applying this framework to answers from nine human communities shows diverse preferences for answer construction strategies. In contrast, LLMs exhibit limited rhetorical diversity even when prompted to follow community-specific guidelines, and systematically favor breadth by addressing additional question interpretations that humans omit. The work aims to inform development of more pragmatically aware LLM answerers.
Significance. If the annotation reliability holds, the findings would be significant for documenting systematic pragmatic differences between human communities and LLMs in QA, offering a structured way to diagnose and mitigate overly broad or uniform LLM responses. The RST-based discourse act representation is a methodological contribution that enables systematic, comparable analysis across sources and could support future work on context-sensitive generation.
major comments (1)
- [DiscoTrace method description and annotation procedure] The central claims (human diversity vs. LLM uniformity and breadth preference) depend on DiscoTrace's discourse act sequences faithfully reflecting answerer intent. The manuscript provides no reported inter-annotator agreement, validation of annotation guidelines across informal community text and LLM outputs, or error analysis for RST parser performance differences between these sources. Systematic parse degradation or annotator bias on LLM text versus human posts would render the diversity gap and breadth findings uninterpretable artifacts rather than substantive results.
minor comments (1)
- [Abstract and §1] The abstract and introduction would benefit from explicitly naming the nine human communities and the specific LLMs/prompting setups used, to allow readers to assess the scope of the diversity claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reliability of the DiscoTrace annotations. We address the methodological concern point by point below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [DiscoTrace method description and annotation procedure] The central claims (human diversity vs. LLM uniformity and breadth preference) depend on DiscoTrace's discourse act sequences faithfully reflecting answerer intent. The manuscript provides no reported inter-annotator agreement, validation of annotation guidelines across informal community text and LLM outputs, or error analysis for RST parser performance differences between these sources. Systematic parse degradation or annotator bias on LLM text versus human posts would render the diversity gap and breadth findings uninterpretable artifacts rather than substantive results.
Authors: We agree that the central claims rest on the faithfulness of the discourse act sequences and that explicit validation is required to rule out artifacts from annotation or parsing differences. The current manuscript does not report inter-annotator agreement, cross-source guideline validation, or a comparative error analysis of the RST parser. In the revised version we will add the following: (1) inter-annotator agreement scores (Cohen's kappa and percentage agreement) computed on a double-annotated subset of 200 answers drawn equally from human community posts and LLM outputs; (2) a brief validation study confirming that the annotation guidelines produce consistent discourse act labels when applied to both informal human text and LLM-generated text; and (3) an error analysis that quantifies RST parser performance (attachment and labeling accuracy) separately on the two sources, together with any observed systematic differences. These additions will be placed in a new subsection of the method and will directly support the interpretability of the reported diversity and breadth contrasts. revision: yes
Circularity Check
No circularity: empirical method application is self-contained
full rationale
The paper defines DiscoTrace as a representation of answers via RST parses annotated with discourse acts and question interpretations, then applies this representation empirically to compare human community answers and LLM outputs. No equations, fitted parameters, predictions derived from fits, or self-citations form the load-bearing steps of the central claims about diversity and breadth preferences. The derivation chain consists of direct annotation and comparison on external data sources rather than any reduction of outputs to inputs by construction or renaming. This is the expected non-finding for an annotation-driven empirical study without mathematical self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rhetorical Structure Theory parses provide a reliable base layer for annotating discourse acts in answers.
- domain assumption Human communities exhibit stable, measurable preferences for answer construction that can be captured by the annotation scheme.
Reference graph
Works this paper leans on
-
[1]
WebGPT: Browser-assisted question-answering with human feedback
Selectively answering ambiguous questions. InProceedings of the 2023 Conference on Empiri- cal Methods in Natural Language Processing, pages 530–543, Singapore. Association for Computational Linguistics. Laura Dietz, Manisha Verma, Filip Radlinski, and Nick Craswell. 2017. Trec complex answer retrieval overview. InTREC. Kawin Ethayarajh, Yejin Choi, and S...
work page internal anchor Pith review arXiv 2023
-
[2]
InSecond Conference on Lan- guage Modeling
Qudsim: Quantifying discourse similarities in llm-generated text. InSecond Conference on Lan- guage Modeling. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
-
[3]
Soham Poddar, Paramita Koley, Janardan Misra, Niloy Ganguly, and Saptarshi Ghosh
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Soham Poddar, Paramita Koley, Janardan Misra, Niloy Ganguly, and Saptarshi Ghosh. 2025. Brevity is the soul of sustainability: Characterizing llm response lengths. InFindings of the Association for Computa- tional Ling...
2025
-
[4]
Taxonomy of user needs and actions
Qa dataset explosion: A taxonomy of nlp resources for question answering and reading com- prehension.ACM Computing Surveys, 55(10):1–45. John Searle. 2014. What is a speech act? InPhilosophy in America, pages 221–239. Routledge. John R Searle. 1969.Speech acts: An essay in the philosophy of language. Cambridge university press. Renee Shelby, Fernando Diaz...
-
[5]
Inproceedings of the interna- tional AAAI conference on web and social media, volume 11, pages 357–366
Characterizing online discussion using coarse discourse sequences. Inproceedings of the interna- tional AAAI conference on web and social media, volume 11, pages 357–366. Michael Zhang, W. Bradley Knox, and Eunsol Choi
-
[6]
is this normal
Modeling future conversation turns to teach llms to ask clarifying questions. InInternational Conference on Learning Representations, volume 2025, pages 60722–60742. Relations Elaboration, Attribution, Joint, Same-Unit, Explanation, Enablement, Background, Evaluation, Cause, Contrast, Temporal, Comparison, Topic-Change, Manner-Means, Textual-Organization,...
2025
-
[7]
If the current segment continues the previous action, reuse the previous action_id
-
[8]
If a new rhetorical move begins, select the appropriate new action_id
-
[9]
So basically,
If no action fits, use “NONE”. Subsegment Labeling Each segment you receive was produced by a discourse parser. You will also be shown the subsegments (sentences) that make up the segment. If all subsegments serve the same discourse function, return a single-element array with one action_id. If different subsegments serve different discourse functions, re...
-
[10]
Where can I find X
Consider the expected answer type of the question when labeling actions. Responding to “Where can I find X” with a website recommendation is an “Answer the Question” action, not a “Direct to Resource” action. If the resource is the answer itself, label it as “Assert Answer”. If the resource is suggested as additional reading, use Direct to Resource
-
[11]
Provide Reasoning or Justification
When a segment contains both an answer and supporting reasoning: if subsegments are provided and the answer and reasoning fall in different subsegments, split them. If they are in thesame subsegment(tightly integrated), label it as “Provide Reasoning or Justification” if the justification is non-trivial, otherwise “Assert Answer”
-
[12]
Provide Reasoning or Justification
When a segment explains WHY something is the case, determine what it is explaining: - If it explains why an answer is correct→ “Provide Reasoning or Justification” - If it explains why a premise of the question is wrong→“Reject Presupposition” Example: For “Why is the sky blue?”, the segment “Because of Rayleigh scattering” is justification. For “What’s t...
-
[13]
Provide Example
Sharing a personal anecdote or experience is “Provide Example”, NOT “Provide Background.” Background sets up context, frameworks, or history before answering. Examples use concrete cases (including personal ones) to support or illustrate an answer. - “I have a doctorate, and sometimes introduce myself as Dr.”→Provide Example - “The use of honorifics has a...
-
[14]
Provide Reasoning or Justification
When a segment follows a recommendation and provides supporting information, ask: does it explain why the recommendation is good in terms of the original question, or does it answer a different question? - If it explains why the recommendation addresses the original question→“Provide Reasoning or Justification” - If it introduces new information that answ...
-
[15]
Cite External Source
When a segment invokes an external source (study, statistic, law, quote, expert consensus) to support a claim, use “Cite External Source”—NOT “Provide Example” or “Provide Reasoning.” The key test: does the credibility derive from an independently verifiable external source, or from the answerer’s own experience/logic? - “A 2019 Lancet study found no sign...
2019
-
[16]
Read the segment in the context of the full answer and the original question Q
-
[17]
If a segment appears to serve multiple functions, choose the primary or dominant one
Assign exactly one discourse act label from the ontology. If a segment appears to serve multiple functions, choose the primary or dominant one
-
[18]
Can language be described by math?
If the assigned act is marked as interpretation- eligible (starred), select the interpretation from the provided interpretation space that the segment most closely addresses. If no listed interpretation fits, mark it as “other.” D.3 Discourse Act Ontology We provided annotators with the same content as in Figure 3 as well as a handful of examples. D.4 Int...
-
[19]
You are given a question, its possible interpretations, and a segment from an answer that has been labeled with a discourse action
-
[20]
This may be explicit or implicit
Determine which question interpretation the segment most directly addresses, adopts, or targets. This may be explicit or implicit
-
[21]
If the segment clearly and directly addresses one of the interpretations, return that interpretation’s ID
-
[22]
NONE”. Output Format Respond with exactly ONE JSON object: [{
If the segment does not clearly target any specific interpretation, return “NONE”. Output Format Respond with exactly ONE JSON object: [{"interpretation_id": "id_1"}] When no specific interpretation is targeted: [{"interpretation_id": "NONE"}] User: Question {question} Question Interpretations {interpretations} Full Answer {answer} Segment(labeled as “{ac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.