Recognition: unknown
On a Probability Inequality for Order Statistics with Applications to Bootstrap, Conformal Prediction, and more
Pith reviewed 2026-05-10 09:16 UTC · model grok-4.3
The pith
An approximate probability inequality for order statistics holds under mild violations of independence and identical distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Suppose X and X' are independent and identically distributed. Then P(X ≤ X') ≥ 1/2 irrespective of the common distribution. The paper explores an extension of this probability inequality involving order statistics and develops approximate versions under violations of independence and identical distribution. It further shows that this inequality can be used as a basis to prove asymptotic validity of bootstrap/subsampling, finite-sample validity of conformal prediction, permutation tests, and asymptotic validity of rank tests without group invariance, including a cheap bootstrap for high-dimensional data as a finite-sample version of some results by Peter Hall.
What carries the argument
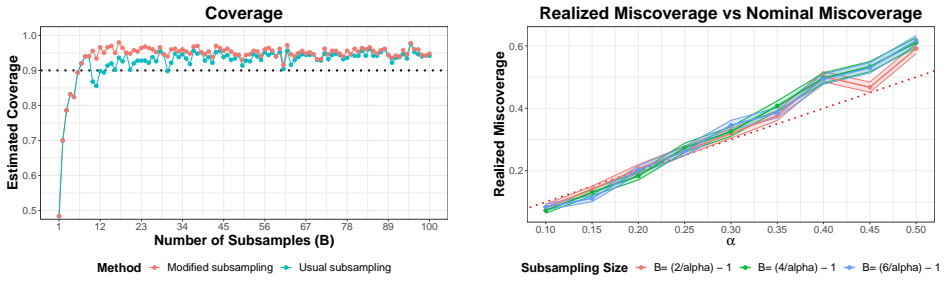
The approximate probability inequality for order statistics from nearly i.i.d. random variables, which bounds the deviation from the exact i.i.d. probability in terms of the degree of violation.
If this is right
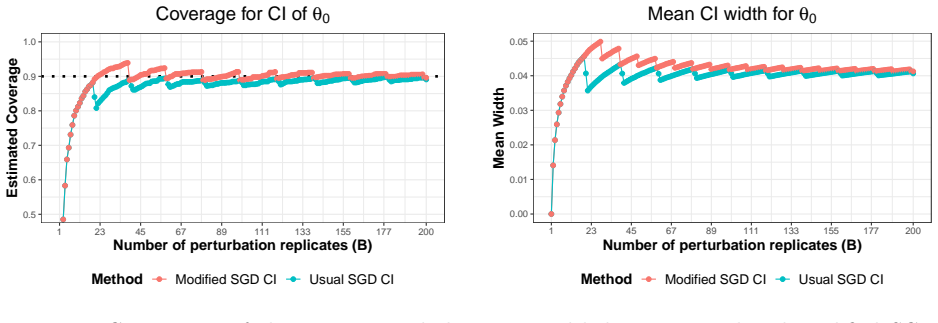
- The inequality implies asymptotic validity of bootstrap and subsampling procedures for inference.
- It establishes finite-sample validity of conformal prediction methods.
- It supports permutation tests without requiring group invariance.
- It yields asymptotic validity for rank tests without group invariance.
- It provides a computationally cheap bootstrap that applies directly to high-dimensional data.
Where Pith is reading between the lines
- The same approximate inequality could be checked numerically on data with gradually increasing dependence to measure how quickly the bound degrades.
- If the regularity conditions can be verified for time-series dependence, the inequality might justify resampling methods for dependent observations.
- This perspective could connect to robustness results in nonparametric statistics where mild departures from i.i.d. are common.
- Practitioners might treat the cheap bootstrap as a default tool in high-dimensional settings where full resampling is prohibitive.
Load-bearing premise
There exist approximate regularity conditions under which the probability inequality for order statistics holds approximately when independence or identical distribution is only mildly violated.
What would settle it
A specific collection of mildly dependent or non-identically distributed random variables where the probability attached to a chosen order statistic falls outside the bound predicted by the approximate inequality by more than the allowed deviation.
Figures



read the original abstract
``Behind every limit theorem, there is an inequality'' said Kolmogorov. We say ``for every inequality, there is an approximate inequality under approximate regularity conditions.'' Suppose $X, X'$ are independent and identically distributed random variables. Then $X \le X'$ with a probability of at least $1/2$, irrespective of the underlying (common) distribution. One can ask what happens to the probability if $X, X'$ are independent but not identically distributed. It should be approximately $1/2$ if the distributions are approximately equal. Similarly, what if the random variables are dependent? It should, again, be approximately $1/2$ if the random variables are approximately independent. We explore an extension of this probability inequality involving order statistics and develop approximate versions of such an inequality under violations of independence and identical distribution assumptions. We further show that this inequality can be used as a basis to prove asymptotic validity of bootstrap/subsampling, finite-sample validity of conformal prediction, permutation tests, and asymptotic validity of rank tests without group invariance. Specifically, in the context of resampling inference, our results can be seen as a finite-sample instantiation of some results by Peter Hall and yield an alternative ``cheap bootstrap'' that applies to high-dimensional data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the classical fact that P(X ≤ X') ≥ 1/2 for i.i.d. continuous random variables X, X' to an inequality involving order statistics. It derives approximate versions of the inequality that continue to hold when the variables are only approximately independent and identically distributed. These bounds are then used to prove asymptotic validity of bootstrap and subsampling, finite-sample validity of conformal prediction and permutation tests, and asymptotic validity of rank tests without requiring group invariance. The work frames the results as a finite-sample perspective on certain results of Peter Hall and proposes a 'cheap bootstrap' applicable to high-dimensional data.
Significance. If the derivations are correct, the manuscript supplies a simple, unifying probabilistic device that recovers known validity statements for several resampling and prediction procedures while relaxing invariance requirements. The finite-sample guarantees for conformal prediction and permutation tests, together with the high-dimensional applicability, would be useful if the approximation errors are controlled explicitly. The approach offers an alternative route to some of Hall's bootstrap results without heavy machinery.
minor comments (4)
- The precise metric and rate at which 'approximately equal' or 'approximately independent' must hold (mentioned in the abstract and §3) should be stated explicitly in the statement of the approximate inequality, even if only for the leading term; this would make the error bounds in the bootstrap and conformal applications easier to verify.
- In the applications section, the translation from the order-statistic inequality to the coverage or type-I error bound should include a short display of the triangle-inequality step that absorbs the approximation error; currently the argument is sketched but not fully written out.
- Notation for the order statistics (e.g., X_{(k:n)}) and the dependence measure used in the approximate-independence case should be introduced once in §2 and used consistently thereafter.
- A brief remark on whether the inequality extends to discrete distributions (or requires a continuity correction) would be helpful, given that some of the target applications (rank tests) routinely involve ties.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and for the positive assessment, including the recommendation for minor revision. The referee's summary accurately captures the paper's focus on extending the classical probability inequality for order statistics to approximate i.i.d. settings and applying it to resampling procedures, conformal prediction, and rank tests. No specific major comments are listed in the report, so we have no points requiring detailed rebuttal. We will address any minor editorial suggestions in the revised version.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper begins with the classical elementary inequality P(X ≤ X') ≥ 1/2 for iid continuous random variables, extends it rigorously to order statistics, and then derives approximate versions under controlled departures from identical distribution or independence. These bounds are applied outward to recover known validity statements for bootstrap, conformal prediction, permutation tests, and rank tests. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the central inequality is derived from first principles and supplies independent content for the applications. The argument structure is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A three-step method for choosing the number of bootstrap repetitions
Donald WK Andrews and Moshe Buchinsky. A three-step method for choosing the number of bootstrap repetitions. Econometrica, 68 0 (1): 0 23--51, 2000
2000
-
[2]
Conformal prediction: A gentle introduction
Anastasios N Angelopoulos and Stephen Bates. Conformal prediction: A gentle introduction. Foundations and Trends in Machine Learning, 16 0 (4): 0 494--591, 2023
2023
-
[3]
arXiv preprint arXiv:2208.02814 , year=
Anastasios N Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Conformal risk control. arXiv preprint arXiv:2208.02814, 2022
-
[4]
arXiv preprint arXiv:2411.11824 , year=
Anastasios N Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoretical foundations of conformal prediction. arXiv preprint arXiv:2411.11824, 2024
-
[5]
Conformal prediction beyond exchangeability
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani. Conformal prediction beyond exchangeability. The Annals of Statistics, 51 0 (2): 0 816--845, 2023
2023
-
[6]
Prepivoting test statistics: a bootstrap view of asymptotic refinements
Rudolf Beran. Prepivoting test statistics: a bootstrap view of asymptotic refinements. Journal of the American Statistical Association, 83 0 (403): 0 687--697, 1988
1988
-
[7]
Bootstrap asymptotics
Rudolf Beran. Bootstrap asymptotics. In International Encyclopedia of Statistical Science, pages 324--327. Springer, 2025
2025
-
[8]
On subsampling estimators with unknown rate of convergence
Patrice Bertail, Dimitris N Politis, and Joseph P Romano. On subsampling estimators with unknown rate of convergence. Journal of the American Statistical Association, 94 0 (446): 0 569--579, 1999
1999
-
[9]
Generalized bootstrap for estimating equations
Snigdhansu Chatterjee and Arup Bose. Generalized bootstrap for estimating equations. 2005
2005
-
[10]
Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors
Victor Chernozhukov, Denis Chetverikov, and Kengo Kato. Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors. The Annals of Statistics, pages 2786--2819, 2013
2013
-
[11]
Binomial approximation to the poisson binomial distribution
Werner Ehm. Binomial approximation to the poisson binomial distribution. Statistics & Probability Letters, 11 0 (1): 0 7--16, 1991
1991
-
[12]
Online bootstrap confidence intervals for the stochastic gradient descent estimator
Yixin Fang, Jinfeng Xu, and Lei Yang. Online bootstrap confidence intervals for the stochastic gradient descent estimator. Journal of Machine Learning Research, 19 0 (78): 0 1--21, 2018
2018
-
[13]
Ronald A. Fisher. The Design of Experiments. Oliver and Boyd, Edinburgh, 1935
1935
-
[14]
On the number of bootstrap simulations required to construct a confidence interval
Peter Hall. On the number of bootstrap simulations required to construct a confidence interval. The Annals of Statistics, pages 1453--1462, 1986
1986
-
[15]
Theoretical comparison of bootstrap confidence intervals
Peter Hall. Theoretical comparison of bootstrap confidence intervals. The Annals of Statistics, pages 927--953, 1988
1988
-
[16]
The bootstrap and Edgeworth expansion
Peter Hall. The bootstrap and Edgeworth expansion. Springer Science & Business Media, 2013
2013
-
[17]
Jesse Hemerik and Jelle J. Goeman. Exact testing with random permutations. TEST, 27 0 (4): 0 811--825, 2018. doi:10.1007/s11749-017-0571-1
-
[18]
On the distribution of the number of successes in independent trials
Wassily Hoeffding. On the distribution of the number of successes in independent trials. The Annals of Mathematical Statistics, pages 713--721, 1956
1956
-
[19]
Koning and Jesse Hemerik
Nick W. Koning and Jesse Hemerik. Faster exact permutation testing: Using a representative subgroup, 2022
2022
-
[20]
A cheap bootstrap method for fast inference
Henry Lam. A cheap bootstrap method for fast inference. arXiv preprint arXiv:2202.00090, 2022
-
[21]
Lehmann and Joseph P
Erich L. Lehmann and Joseph P. Romano. Testing Statistical Hypotheses. Springer, New York, 3 edition, 2005
2005
-
[22]
Distribution-free prediction bands for non-parametric regression
Jing Lei and Larry Wasserman. Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 76 0 (1): 0 71--96, 2014
2014
-
[23]
Distribution-free predictive inference for regression
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression. Journal of the American Statistical Association, 113 0 (523): 0 1094--1111, 2018
2018
-
[24]
Estimating an endpoint of a distribution with resampling methods
Wei-Yin Loh. Estimating an endpoint of a distribution with resampling methods. The Annals of Statistics, pages 1543--1550, 1984
1984
-
[25]
Inductive confidence machines for regression
Harris Papadopoulos, Kostas Proedrou, Volodya Vovk, and Alex Gammerman. Inductive confidence machines for regression. In European conference on machine learning, pages 345--356. Springer, 2002
2002
-
[26]
On the bernstein-hoeffding method
Christos Pelekis, Jan Ramon, and Yuyi Wang. On the bernstein-hoeffding method. arXiv preprint arXiv:1503.02284, 2015
-
[27]
Large sample confidence regions based on subsamples under minimal assumptions
Dimitris N Politis and Joseph P Romano. Large sample confidence regions based on subsamples under minimal assumptions. The Annals of Statistics, pages 2031--2050, 1994
2031
-
[28]
Subsampling in the iid case
Dimitris N Politis, Joseph P Romano, and Michael Wolf. Subsampling in the iid case. In Subsampling, pages 39--64. Springer, 1999
1999
-
[29]
On the asymptotic theory of subsampling
Dimitris N Politis, Joseph P Romano, and Michael Wolf. On the asymptotic theory of subsampling. Statistica Sinica, pages 1105--1124, 2001
2001
-
[30]
Acceleration of stochastic approximation by averaging
Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30 0 (4): 0 838--855, 1992
1992
-
[31]
Aaditya Ramdas, Rina Foygel Barber, Emmanuel J. Cand \`e s, and Ryan J. Tibshirani. Permutation tests using arbitrary permutation distributions. Sankhy\= a A , 85: 0 1156--1177, 2023. doi:10.1007/s13171-023-00308-8
-
[32]
Approximate Distributions of Order Statistics: With Applications to Nonparametric Statistics
Rolf-Dieter Reiss. Approximate Distributions of Order Statistics: With Applications to Nonparametric Statistics. Springer Series in Statistics. Springer-Verlag, New York, NY, 1989. ISBN 978-1-4613-9622-2. doi:10.1007/978-1-4613-9620-8. Softcover reprint published in 2011
-
[33]
Bootstrap and randomization tests of some nonparametric hypotheses
Joseph P Romano. Bootstrap and randomization tests of some nonparametric hypotheses. The Annals of Statistics, 17 0 (1): 0 141--159, 1989
1989
-
[34]
On the behavior of randomization tests without a group invariance assumption
Joseph P Romano. On the behavior of randomization tests without a group invariance assumption. Journal of the American Statistical Association, 85 0 (411): 0 686--692, 1990
1990
-
[35]
Subsampling inference for the mean in the heavy-tailed case
Joseph P Romano and Michael Wolf. Subsampling inference for the mean in the heavy-tailed case. Metrika, 50 0 (1): 0 55--69, 1999
1999
-
[36]
The bayesian bootstrap
Donald B Rubin. The bayesian bootstrap. The annals of statistics, pages 130--134, 1981
1981
-
[37]
Efficient estimations from a slowly convergent robbins-monro process
David Ruppert. Efficient estimations from a slowly convergent robbins-monro process. Technical report, Cornell University Operations Research and Industrial Engineering, 1988
1988
-
[38]
The poisson binomial distribution—old & new
Wenpin Tang and Fengmin Tang. The poisson binomial distribution—old & new. Statistical Science, 38 0 (1): 0 108--119, 2023
2023
-
[39]
Algorithmic learning in a random world
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer. Algorithmic learning in a random world. Springer, 2005
2005
-
[40]
Statistical methods and computing for big data
Chun Wang, Ming-Hui Chen, Elizabeth Schifano, Jing Wu, and Jun Yan. Statistical methods and computing for big data. Statistics and its interface, 9 0 (4): 0 399, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.