Recognition: unknown
Stability and Generalization in Looped Transformers
Pith reviewed 2026-05-10 12:16 UTC · model grok-4.3
The pith
Recall combined with outer normalization produces stable, reachable fixed points in looped transformers that support generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
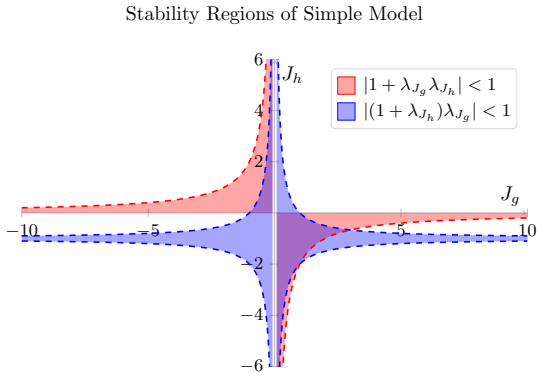
The paper establishes that looped networks without recall have countable fixed points and cannot achieve strong input-dependence at any spectral regime, while recall combined with outer normalization reliably produces a regime in which fixed points are simultaneously reachable, locally smooth in the input, and supported by stable backpropagation.
What carries the argument
The fixed-point based framework for analyzing looped architectures along reachability, input-dependence, and geometry axes, with recall and outer normalization as the key architectural choices that enable stable regimes.
Load-bearing premise
The three stability axes of reachability, input-dependence, and geometry are sufficient to characterize when fixed-point iteration yields meaningful predictions rather than memorization.
What would settle it
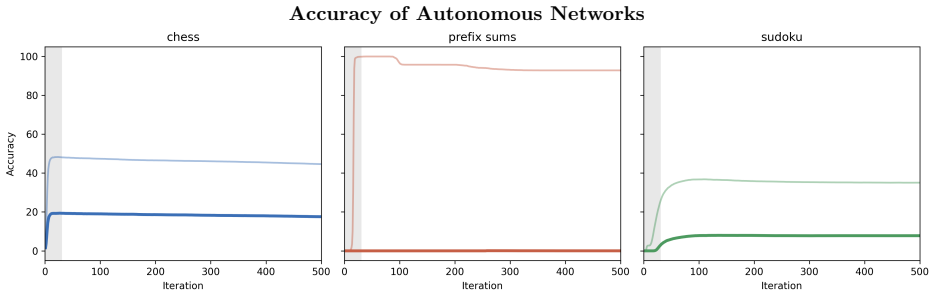
Training a looped transformer without recall or outer normalization on sudoku and checking whether it fails to extrapolate to harder instances despite high training accuracy, or conversely succeeds with both components.
Figures





read the original abstract
Looped transformers promise test-time compute scaling by spending more iterations on harder problems, but it remains unclear which architectural choices let them extrapolate to harder problems at test time rather than memorize training-specific solutions. We introduce a fixed-point based framework for analyzing looped architectures along three axes of stability -- reachability, input-dependence, and geometry -- and use it to characterize when fixed-point iteration yields meaningful predictions. Theoretically, we prove that looped networks without recall have countable fixed points and cannot achieve strong input-dependence at any spectral regime, while recall combined with outer normalization reliably produces a regime in which fixed points are simultaneously reachable, locally smooth in the input, and supported by stable backpropagation. Empirically, we train single-layer looped transformers on chess, sudoku, and prefix-sums and find that downstream performance tracks the framework's predictions across tasks and architectural configurations. We additionally introduce internal recall, a novel recall placement variant, and show that it becomes competitive with -- and on sudoku, substantially better than -- standard recall placement once outer normalization is applied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a fixed-point framework for analyzing looped transformers along three stability axes (reachability, input-dependence, and geometry) to determine when iteration produces meaningful predictions rather than memorization. It proves that networks without recall have only countable fixed points and lack strong input dependence at any spectral regime, while recall combined with outer normalization yields fixed points that are simultaneously reachable, locally smooth in the input, and compatible with stable backpropagation. Empirically, single-layer looped transformers trained on chess, sudoku, and prefix sums show downstream performance that tracks the framework predictions across configurations; a novel internal recall placement is introduced and shown to be competitive (and superior on sudoku) when outer normalization is used.
Significance. If the central claims hold, the work supplies a principled, non-fitted analysis tool for designing looped architectures that scale test-time compute via extrapolation. The derivation of the three axes directly from fixed-point properties (rather than post-hoc fitting) and the multi-task empirical alignment are clear strengths. The introduction of internal recall as a placement variant adds a concrete architectural contribution.
major comments (2)
- [§3] §3 (theoretical analysis): the central claim that the three stability properties produce 'meaningful predictions' rather than memorization rests on the fixed-point characterization, yet no theorem is supplied that derives generalization bounds or extrapolation guarantees from reachability + local smoothness + stable backpropagation. The proofs establish the properties themselves but do not close the loop to resistance against training-specific solutions.
- [§4] §4 (experiments): performance is reported to track the framework across tasks and configs, but the design does not include targeted ablations that hold two axes fixed while violating the third (e.g., reachability and geometry preserved but input-dependence removed) to test whether the full triad is necessary to shift from memorization to extrapolation on the target tasks.
minor comments (2)
- [§2] Notation for the three axes is introduced in the abstract and §2 but the precise mathematical definitions (e.g., how 'local smoothness in the input' is quantified) would benefit from an explicit summary table or boxed definition early in the paper.
- [§4] The description of training details, loss metrics, and controls for the chess/sudoku/prefix-sum experiments is referenced but could be expanded with a short table of hyperparameters to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, the recognition of the framework's strengths, and the constructive major comments. We respond point-by-point below, proposing targeted revisions to improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the central claim that the three stability properties produce 'meaningful predictions' rather than memorization rests on the fixed-point characterization, yet no theorem is supplied that derives generalization bounds or extrapolation guarantees from reachability + local smoothness + stable backpropagation. The proofs establish the properties themselves but do not close the loop to resistance against training-specific solutions.
Authors: We agree that an explicit generalization bound (e.g., via Rademacher complexity) would further strengthen the manuscript. However, the existing proofs already close part of the loop: without recall the fixed-point set is at most countable, so the iteration cannot produce distinct outputs for uncountably many inputs and must therefore rely on memorization of discrete training points. With recall plus outer normalization the fixed points become locally Lipschitz in the input, directly supplying the continuity needed for extrapolation. We will revise §3 to state this implication explicitly, add a limitations paragraph noting the absence of a full PAC-style bound, and mark derivation of such bounds as future work. revision: partial
-
Referee: [§4] §4 (experiments): performance is reported to track the framework across tasks and configs, but the design does not include targeted ablations that hold two axes fixed while violating the third (e.g., reachability and geometry preserved but input-dependence removed) to test whether the full triad is necessary to shift from memorization to extrapolation on the target tasks.
Authors: We acknowledge that the current experiments do not contain every possible combination that isolates one axis while preserving the other two. The three axes are mathematically interdependent (input-dependence is controlled by the same spectral and recall parameters that govern reachability and geometry), which makes certain ablations infeasible or degenerate. The reported configurations nevertheless vary each axis across its natural regimes and show consistent alignment with downstream performance. We will add a dedicated paragraph in §4 discussing this interdependence and the resulting limitations on causal isolation; we are also willing to include any additional feasible ablations the referee recommends. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central theoretical claims consist of proofs about the number and properties of fixed points (countable without recall; reachable, input-smooth, and backprop-stable with recall plus outer normalization) derived directly from the looped transformer iteration equations and architectural definitions. These are not obtained by fitting parameters to data, redefining the target quantity in terms of itself, or relying on self-citations for uniqueness. The three stability axes are introduced as an analytical lens and then used to characterize regimes; empirical tracking of performance on chess, sudoku, and prefix sums is presented as corroboration rather than as the source of the claims. No load-bearing step reduces by construction to its own inputs, and the framework remains self-contained against the stated model assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fixed-point iteration in looped networks can be characterized by reachability, input-dependence, and geometry to determine meaningful predictions.
invented entities (1)
-
internal recall
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Path independent equilibrium models can better exploit test-time computation, 2022
ISSN 9781713871088. URLhttps: //arxiv.org/pdf/2211.09961. Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models,
-
[2]
Zico Kolter, and Vladlen Koltun
URLhttps://arxiv. org/abs/1909.01377. Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder,
-
[3]
URLhttps: //arxiv.org/abs/2107.05407. Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation With- out Overthinking.Advances in Neural Information Processing Systems, 35, February
-
[4]
URLhttps://arxiv.org/pdf/2202.05826
ISSN 9781713871088. URLhttps://arxiv.org/pdf/2202.05826. Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal Trans- formers.7th International Conference on Learning Representations, ICLR 2019, July
-
[5]
URL https://arxiv.org/pdf/1807.03819. Tom Dillion. Tdoku: A fast sudoku solver and generator,
work page internal anchor Pith review arXiv
-
[6]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
URLhttp://arxiv.org/abs/2502.05171. Alex Graves. Adaptive computation time for recurrent neural networks,
work page internal anchor Pith review arXiv
-
[7]
URLhttps://arxiv.org/ abs/1603.08983. V. Guillemin and A. Pollack.Differential Topology. AMS Chelsea Publishing. AMS Chelsea Pub.,
work page internal anchor Pith review arXiv
-
[8]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , volume=
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URLhttp://dx.doi.org/10.1038/s41586-025-09422-z. Charles R. Harris, K. Jarrod Millman, St´ efan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Pi- cus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, A...
-
[9]
doi: 10.1038/s41586-020-2649-2. URLhttps: //doi.org/10.1038/s41586-020-2649-2. Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus),
-
[10]
Gaussian Error Linear Units (GELUs)
URLhttps://arxiv.org/ abs/1606.08415. Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers,
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
URL https: //arxiv.org/abs/2510.04871
URL http://arxiv.org/abs/2510.04871. arXiv:2510.04871. Nikita Karagodin, Shu Ge, Yury Polyanskiy, and Philippe Rigollet. Normalization in attention dynamics,
-
[13]
URLhttps://arxiv.org/abs/2510.22026. Jeonghoon Kim, Byeongchan Lee, Cheonbok Park, Yeontaek Oh, Beomjun Kim, Taehwan Yoo, Seongjin Shin, Dongyoon Han, Jinwoo Shin, and Kang Min Yoo. Peri-ln: Revisiting normalization layer in the transformer architecture,
- [14]
-
[15]
Decoupled Weight Decay Regularization
URLhttps://arxiv.org/ abs/1711.05101. 26 William Merrill and Ashish Sabharwal. Exact expressive power of transformers with padding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Exact expressive power of transformers with padding,
URL https://arxiv.org/abs/2505.18948. John Milnor.Topology from the Differentiable Viewpoint. University Press of Virginia,
-
[18]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
URLhttp://arxiv.org/abs/1912.01703. Nikunj Saunshi, Stefani Karp, Shankar Krishnan, Sobhan Miryoosefi, Sashank J. Reddi, and Sanjiv Kumar. On the Inductive Bias of Stacking Towards Improving Reasoning. September
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[19]
URLhttp://arxiv. org/abs/2409.19044. Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with Latent Thoughts: On the Power of Looped Transformers. February
-
[20]
Hierarchical reasoning model, 2025
URLhttp://arxiv.org/abs/2506.21734. arXiv:2506.21734. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models,
-
[21]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URL https://arxiv.org/abs/2201.11903. Wes McKinney. Data Structures for Statistical Computing in Python. In St´ efan van der Walt and Jarrod Millman, editors,Proceedings of the 9th Python in Science Conference, pages 56 – 61,
work page internal anchor Pith review arXiv
-
[22]
On layer normalization in the transformer architecture, 2020
URL https://arxiv.org/abs/2002.04745. Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms,
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.