Recognition: unknown
How Do LLMs and VLMs Understand Viewpoint Rotation Without Vision? An Interpretability Study
Pith reviewed 2026-05-10 10:42 UTC · model grok-4.3
The pith
LLMs and VLMs encode viewpoint information in hidden states but fail to bind it to corresponding observations, producing hallucinations in final layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Although models encode viewpoint information in the hidden states, they appear to struggle to bind the viewpoint position with corresponding observation, resulting in a hallucination in final layers.
What carries the argument
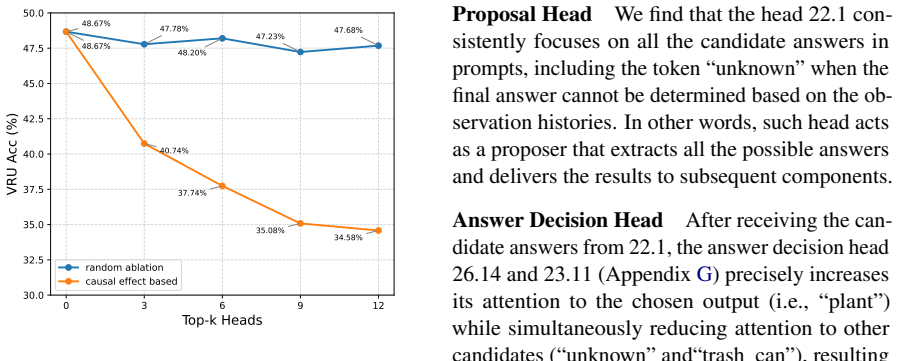
Head-wise causal intervention applied to attention heads, which isolates the heads responsible for linking viewpoint positions to observations.
If this is right
- Models encode viewpoint positions internally yet still output incorrect observations because the binding step fails.
- Selective fine-tuning of the attention heads identified by causal intervention raises VRU accuracy.
- The same fine-tuning leaves generic language abilities intact rather than causing forgetting.
- Human-level performance on the same textual task demonstrates that the required spatial binding is achievable in principle.
Where Pith is reading between the lines
- The identified binding failure may limit performance on any multi-step text reasoning task that requires maintaining distinct states and their associated content.
- Architectures that explicitly separate and re-associate positional and content representations could mitigate the same limitation on other spatial or sequential problems.
Load-bearing premise
The constructed textual dataset accurately captures the requirements of viewpoint rotation understanding without introducing ambiguities or task-specific artifacts that humans handle differently from models.
What would settle it
If a model variant is found that maintains accurate position-to-observation bindings through all layers and achieves near-human accuracy on the same textual rotation sequences, the claim of an inherent binding failure would be falsified.
Figures














read the original abstract
Over the past year, spatial intelligence has drawn increasing attention. Many prior works study it from the perspective of visual-spatial intelligence, where models have access to visuospatial information from visual inputs. However, in the absence of visual information, whether linguistic intelligence alone is sufficient to endow models with spatial intelligence, and how models perform relevant tasks with text-only inputs still remain unexplored. Therefore, in this paper, we focus on a fundamental and critical capability in spatial intelligence from a linguistic perspective: viewpoint rotation understanding (VRU). Specifically, LLMs and VLMs are asked to infer their final viewpoint and predict the corresponding observation in an environment given textual description of viewpoint rotation and observation over multiple steps. We find that both LLMs and VLMs perform poorly on our proposed dataset while human can easily achieve 100% accuracy, indicating a substantial gap between current model capabilities and the requirements of spatial intelligence. To uncover the underlying mechanisms, we conduct a layer-wise probing analysis and head-wise causal intervention. Our findings reveal that although models encode viewpoint information in the hidden states, they appear to struggle to bind the viewpoint position with corresponding observation, resulting in a hallucination in final layers. Finally, we selectively fine-tune the key attention heads identified by causal intervention to improve VRU performance. Experimental results demonstrate that such selective fine-tuning achieves improved VRU performance while avoiding catastrophic forgetting of generic abilities. Our dataset and code will be released at https://github.com/Young-Zhen/VRU_Interpret .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a text-only Viewpoint Rotation Understanding (VRU) task and dataset in which LLMs and VLMs must infer a final viewpoint and corresponding observation after multi-step textual descriptions of rotations and observations. Models achieve low accuracy while humans reach 100%, and layer-wise probing plus head-wise causal interventions are used to argue that viewpoint information is encoded in hidden states but fails to bind to observations, producing hallucinations in final layers. Selective fine-tuning of the implicated attention heads is shown to improve VRU performance without catastrophic forgetting of general capabilities.
Significance. If the binding-failure mechanism is robustly demonstrated, the work identifies a concrete limitation in how current models perform spatial reasoning from language alone and supplies a targeted intervention (selective head fine-tuning) that could be broadly useful. The public release of the dataset and code would support follow-up studies on linguistic spatial intelligence.
major comments (3)
- Dataset construction and validation: the central claim that poor performance reflects a binding deficit rather than dataset artifacts (lexical shortcuts, ambiguous rotation directions, or multiple consistent interpretations) requires explicit controls. The manuscript reports human 100% accuracy but does not appear to include analysis of inter-annotator agreement on the textual descriptions, adversarial variants, or checks for pattern-matching solutions that models could exploit without true spatial binding.
- Experimental results section: quantitative details on model accuracies, probing R² or accuracy curves, intervention effect sizes (e.g., accuracy drop when heads are ablated), baselines (random, majority-class, or simpler text models), and error analysis are not provided in the described experiments. Without these, it is difficult to assess whether the observed final-layer hallucination is load-bearing for the binding claim or could arise from other factors.
- Causal intervention and fine-tuning: the identification of 'key attention heads' via causal intervention and the subsequent selective fine-tuning lack reported metrics on how many heads were selected, the precise performance delta versus full fine-tuning or LoRA, and controls for whether the improvement is specific to VRU or generalizes to other spatial tasks.
minor comments (2)
- Clarify the precise definition of 'hallucination in final layers'—whether it refers to incorrect token generation, internal representation mismatch, or output inconsistency—and provide layer-wise accuracy or logit visualizations to support the claim.
- The abstract and introduction would benefit from a short related-work paragraph distinguishing VRU from prior text-based spatial reasoning benchmarks (e.g., those involving navigation or mental rotation in language models).
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We have carefully considered each major comment and will make revisions to address them, as detailed below.
read point-by-point responses
-
Referee: [—] Dataset construction and validation: the central claim that poor performance reflects a binding deficit rather than dataset artifacts (lexical shortcuts, ambiguous rotation directions, or multiple consistent interpretations) requires explicit controls. The manuscript reports human 100% accuracy but does not appear to include analysis of inter-annotator agreement on the textual descriptions, adversarial variants, or checks for pattern-matching solutions that models could exploit without true spatial binding.
Authors: We agree with the referee that rigorous validation of the dataset is essential to substantiate our claim regarding the binding deficit. While the manuscript highlights the 100% human accuracy to indicate the task's solvability, we acknowledge the absence of inter-annotator agreement metrics and adversarial testing. In the revised version, we will add: (1) inter-annotator agreement scores for the textual descriptions, (2) adversarial variants designed to probe for lexical shortcuts and ambiguous rotations, and (3) analysis showing that models cannot solve the task via pattern matching alone. These additions will strengthen the evidence that the performance gap arises from a failure in binding viewpoint information to observations rather than dataset artifacts. revision: yes
-
Referee: [—] Experimental results section: quantitative details on model accuracies, probing R² or accuracy curves, intervention effect sizes (e.g., accuracy drop when heads are ablated), baselines (random, majority-class, or simpler text models), and error analysis are not provided in the described experiments. Without these, it is difficult to assess whether the observed final-layer hallucination is load-bearing for the binding claim or could arise from other factors.
Authors: We appreciate the need for more comprehensive quantitative reporting. The current manuscript describes the overall findings but omits detailed metrics. We will revise the experimental results section to include: specific accuracy numbers for each model with error bars, layer-wise probing results with R² values and accuracy curves, effect sizes from causal interventions (including accuracy drops from head ablations), comparisons against random, majority-class, and simpler baselines, and a thorough error analysis of model failures. This will provide clearer support for the final-layer hallucination phenomenon and its relation to the binding claim. revision: yes
-
Referee: [—] Causal intervention and fine-tuning: the identification of 'key attention heads' via causal intervention and the subsequent selective fine-tuning lack reported metrics on how many heads were selected, the precise performance delta versus full fine-tuning or LoRA, and controls for whether the improvement is specific to VRU or generalizes to other spatial tasks.
Authors: We thank the referee for highlighting the need for more precise reporting on the intervention and fine-tuning experiments. In the revision, we will specify the number of key attention heads identified through causal intervention, report the exact performance improvements on the VRU task, provide comparisons of selective fine-tuning against full fine-tuning and LoRA in terms of VRU accuracy gains and retention of general capabilities, and include controls demonstrating that the improvements are specific to VRU by evaluating on additional spatial reasoning tasks. These details will better illustrate the efficacy and targeted nature of our approach. revision: yes
Circularity Check
No significant circularity: empirical dataset, probing, and interventions are independent of inputs
full rationale
The paper constructs a new textual VRU dataset, evaluates LLMs/VLMs on it, performs layer-wise probing to detect encoded viewpoint information, applies head-wise causal interventions to test binding, and reports selective fine-tuning outcomes. No equation, definition, or central claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the binding-failure and hallucination observations are measured outcomes rather than tautological restatements of the task setup. Human 100% accuracy serves as an external benchmark, and the work remains self-contained without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal interventions on attention heads can isolate their functional role in binding information across layers
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.11239 , year=
Beyond flatlands: Unlocking spatial intelli- gence by decoupling 3d reasoning from numerical regression.Preprint, arXiv:2511.11239. Zhongbin Guo, Zhen Yang, Yushan Li, Xinyue Zhang, Wenyu Gao, Jiacheng Wang, Chengzhi Li, Xiangrui Liu, and Ping Jian. 2026. Can llms see without pix- els? benchmarking spatial intelligence from textual descriptions.Preprint, ...
-
[2]
How does GPT-2 compute greater-than?: In- terpreting mathematical abilities in a pre-trained lan- guage model. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neu- ral Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Ma...
work page internal anchor Pith review arXiv 2023
-
[3]
Advancing spatial reasoning in large language models: An in-depth evaluation and enhancement using the stepgame benchmark. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applica- tions of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence...
-
[4]
MLLM can see? dynamic correction decoding for hallucination mitigation. InThe Thirteenth In- ternational Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net. Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Sharon Li, and Neel Joshi. 2024. Is A picture worth A thousand words? delving into spatial ...
-
[5]
arXiv preprint arXiv:2501.14457 , year=
OpenReview.net. Zeping Yu and Sophia Ananiadou. 2024. Interpret- ing arithmetic mechanism in large language models through comparative neuron analysis. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 3293–3306. Association for Computational Linguistics. Zep...
-
[6]
unknown” with “sad
of 1.0, which strongly demonstrates the inter- annotator reliability. C Layer-wise Probing C.1 Dataset for Probing For probingdirection(the probing label is shown after▷): Labels for Probing Direction content: < task description > Initial Observation: avocado Action: Turn to the right by 270 degrees ▷right Observation: router Action: Turn to the left by 9...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.