Recognition: unknown
AnimationBench: Are Video Models Good at Character-Centric Animation?
Pith reviewed 2026-05-10 11:44 UTC · model grok-4.3
The pith
AnimationBench evaluates character animation in video models by scoring against the twelve basic principles of animation rather than realism alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
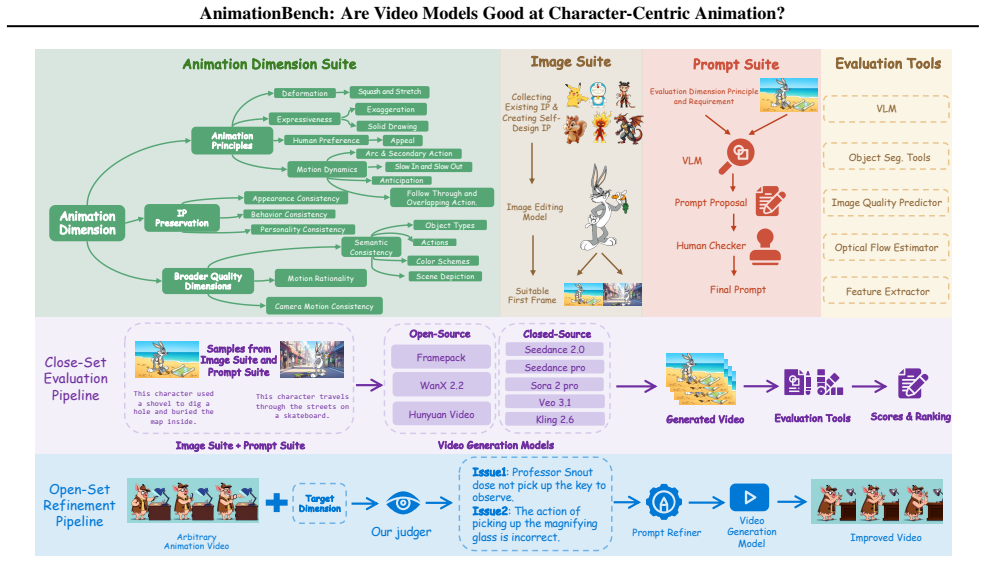
AnimationBench is the first systematic benchmark for image-to-video animation generation that operationalizes the Twelve Basic Principles of Animation and IP Preservation into VLM-scorable evaluation dimensions, adds broader quality checks for semantic consistency, motion rationality, and camera motion consistency, supports both standardized close-set and flexible open-set evaluation modes, and produces scores that align with human judgment while exposing animation-specific weaknesses in current I2V models that realism-focused benchmarks miss.
What carries the argument
AnimationBench, which converts the twelve basic principles of animation and IP preservation into objective evaluation dimensions that VLMs can score automatically.
If this is right
- I2V models can be compared more reliably on animation tasks, revealing which architectures handle stylized motion and character consistency best.
- Model developers gain diagnostic signals for specific failures such as broken timing or inconsistent character design that realism benchmarks hide.
- Evaluation pipelines become more adaptable, supporting both fixed leaderboards and custom open-domain test sets without new human annotation campaigns.
- Progress in animation generation can be tracked separately from photorealistic video generation, avoiding conflation of the two goals.
Where Pith is reading between the lines
- Adoption of this benchmark could shift training objectives toward explicit optimization of the twelve principles rather than generic realism losses.
- The same principle-to-dimension translation approach might extend to other stylized domains such as cartoon, anime, or motion-graphic video generation.
- If the open-set mode proves robust, it could reduce the need for large fixed prompt sets when evaluating new models on emerging animation styles.
Load-bearing premise
The twelve basic principles of animation can be translated into objective, VLM-scorable dimensions without substantial loss of meaning or introduction of model-specific biases.
What would settle it
Collect human ratings on the same set of animated videos using the twelve principles as explicit criteria and check whether the benchmark's automatic scores correlate strongly with those ratings.
Figures









read the original abstract
Video generation has advanced rapidly, with recent methods producing increasingly convincing animated results. However, existing benchmarks-largely designed for realistic videos-struggle to evaluate animation-style generation with its stylized appearance, exaggerated motion, and character-centric consistency. Moreover, they also rely on fixed prompt sets and rigid pipelines, offering limited flexibility for open-domain content and custom evaluation needs. To address this gap, we introduce AnimationBench, the first systematic benchmark for evaluating animation image-to-video generation. AnimationBench operationalizes the Twelve Basic Principles of Animation and IP Preservation into measurable evaluation dimensions, together with Broader Quality Dimensions including semantic consistency, motion rationality, and camera motion consistency. The benchmark supports both a standardized close-set evaluation for reproducible comparison and a flexible open-set evaluation for diagnostic analysis, and leverages visual-language models for scalable assessment. Extensive experiments show that AnimationBench aligns well with human judgment and exposes animation-specific quality differences overlooked by realism-oriented benchmarks, leading to more informative and discriminative evaluation of state-of-the-art I2V models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnimationBench, the first systematic benchmark for evaluating image-to-video (I2V) models on character-centric animation generation. It operationalizes the Twelve Basic Principles of Animation plus IP preservation into measurable dimensions, augments them with broader quality axes (semantic consistency, motion rationality, camera motion consistency), and supports both standardized close-set evaluation for reproducible comparisons and flexible open-set evaluation for diagnostics. The benchmark relies on VLMs for scalable scoring, with experiments claiming strong alignment to human judgment and superior ability to reveal animation-specific quality gaps missed by realism-oriented benchmarks.
Significance. If the human-alignment results hold, AnimationBench would address a clear gap in video generation evaluation by providing animation-tailored metrics that capture stylized motion, exaggeration, and character consistency rather than defaulting to photographic realism. The dual closed/open-set design and use of established animation principles are strengths that could guide more relevant model improvements and enable diagnostic analysis beyond fixed prompt sets.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The central claim that 'AnimationBench aligns well with human judgment' is load-bearing for the contribution, yet the translation of qualitative principles (anticipation, exaggeration, character consistency, IP preservation) into VLM prompts and numeric scores is the weakest link. Without explicit prompt templates, scoring rubrics, or ablations on VLM choice (and their potential photographic bias on stylized content), the reported alignment could be artifactual rather than evidence that the benchmark genuinely exposes animation-specific differences.
- [Benchmark Design] Benchmark Design: The operationalization of the 12 principles into VLM-scorable dimensions risks author-driven choices in what counts as 'measurable' and how scores are aggregated; this could undermine the claim of objective, discriminative evaluation. A concrete test (e.g., inter-rater agreement between VLM and multiple human annotators per principle, or sensitivity analysis to prompt wording) is needed to confirm the dimensions are not circular with the authors' own definitions.
minor comments (2)
- The distinction between close-set and open-set protocols could be clarified earlier, including how open-set avoids prompt cherry-picking while remaining reproducible.
- Figure captions and tables reporting human-VLM correlations should include exact sample sizes, confidence intervals, and the specific VLM(s) used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify key areas where additional transparency and validation can strengthen the presentation of AnimationBench. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim that 'AnimationBench aligns well with human judgment' is load-bearing for the contribution, yet the translation of qualitative principles (anticipation, exaggeration, character consistency, IP preservation) into VLM prompts and numeric scores is the weakest link. Without explicit prompt templates, scoring rubrics, or ablations on VLM choice (and their potential photographic bias on stylized content), the reported alignment could be artifactual rather than evidence that the benchmark genuinely exposes animation-specific differences.
Authors: We agree that the human-alignment claim requires stronger supporting documentation. The manuscript describes the evaluation dimensions and VLM-assisted scoring process in Section 3 and reports correlation results in Section 4, but does not include the verbatim prompt templates or rubrics. In the revised version we will add the complete prompt templates and numeric scoring rubrics for each principle and broader dimension to the appendix. We will also include an ablation across multiple VLMs (including models with different training distributions) to quantify any photographic bias on stylized content and to show that the reported alignment is robust rather than model-specific. revision: yes
-
Referee: [Benchmark Design] The operationalization of the 12 principles into VLM-scorable dimensions risks author-driven choices in what counts as 'measurable' and how scores are aggregated; this could undermine the claim of objective, discriminative evaluation. A concrete test (e.g., inter-rater agreement between VLM and multiple human annotators per principle, or sensitivity analysis to prompt wording) is needed to confirm the dimensions are not circular with the authors' own definitions.
Authors: We acknowledge that operationalizing qualitative principles inevitably involves design choices and that explicit validation against those choices is necessary. The current human study (Section 4) demonstrates overall correlation between VLM scores and human ratings, but does not report per-principle inter-annotator agreement with multiple raters or prompt-sensitivity results. In the revision we will add a prompt-wording sensitivity analysis. We will also expand the human evaluation protocol to include multiple annotators per principle on a held-out subset and report agreement statistics. These additions will directly address concerns about circularity and author-driven aggregation. revision: partial
Circularity Check
No significant circularity: validation uses independent human judgments
full rationale
The paper operationalizes the Twelve Basic Principles of Animation plus IP preservation into VLM-scored dimensions and validates the resulting benchmark via extensive experiments that compare against human judgments. This external human alignment check is independent of the authors' definitions and scoring choices. No equations, fitted parameters, or self-citation chains reduce any central claim to a tautology or input by construction. The derivation remains self-contained against external benchmarks, consistent with the default expectation for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Twelve Basic Principles of Animation can be operationalized into measurable evaluation dimensions.
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K
Ac- cessed: 2026-04-14. Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K. V ., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., R¨adle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.-H., Zhou, Y ., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li...
2026
-
[4]
SAM 3: Segment Anything with Concepts
URL https://arxiv.org/abs/ 2511.16719. Chen, S., Chen, Y ., Chen, Y ., Chen, Z., Cheng, F., Chi, X., Cong, J., Cui, Q., Dong, Q., Fan, J., et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y ., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113,
work page internal anchor Pith review arXiv
-
[7]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
URL https://deepmind.google/models/veo/. He, X., Jiang, D., Nie, P., Liu, M., Jiang, Z., Su, M., Ma, W., Lin, J., Ye, C., Lu, Y ., et al. Videoscore2: Think before you score in generative video evaluation.arXiv preprint arXiv:2509.22799,
-
[8]
Jiang, Y ., Xu, B., Yang, S., Yin, M., Liu, J., Xu, C., Wang, S., Wu, Y ., Zhu, B., Zhang, X., et al. Anisora: Exploring the frontiers of animation video generation in the sora era. arXiv preprint arXiv:2412.10255,
-
[9]
Worldmodelbench: Judging video generation models as world models
URLhttps://kling.ai/. Li, D., Fang, Y ., Chen, Y ., Yang, S., Cao, S., Wong, J., Luo, M., Wang, X., Yin, H., Gonzalez, J. E., et al. World- modelbench: Judging video generation models as world models.arXiv preprint arXiv:2502.20694,
-
[10]
10 AnimationBench: Are Video Models Good at Character-Centric Animation? Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y ., Li, D., Qiao, Y ., and Luo, P. To- wards world simulator: Crafting physical commonsense- based benchmark for video generation.arXiv preprint arXiv:2410.05363,
-
[11]
URL https://openai.com/index/ video-generation-models-as-world-simulators/ . Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., Wang, Y ., Ye, A., Ren, G., Ma, Q., Liang, W., Lian, X., Wu, X., Zhong, Y ., Li, Z., Gong, C., Lei, G., Cheng, L., Zhang, L., Li, M., Zhang, R., Hu, S., Huang, S., Wang, X., Zhao, Y ....
-
[12]
doi: 10.48550/ARXIV . 2503.09642. URLhttps://doi.org/10.48550/ arXiv.2503.09642. Simonyan, K. and Zisserman, A. Very deep convolu- tional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review doi:10.48550/arxiv
-
[13]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a
Wu, B., Zou, C., Li, C., Huang, D., Yang, F., Tan, H., Peng, J., Wu, J., Xiong, J., Jiang, J., et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a. Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.-m., Bai, S., Xu, X., Chen, Y ., et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025b. Yang, A., Li,...
-
[16]
Zhang, L. and Agrawala, M. Packing input frame context in next-frame prediction models for video generation.arXiv preprint arXiv:2504.12626,
-
[17]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., Zhang, F., Gu, L., Zhang, Y ., He, J., Zheng, W.-S., et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review arXiv
-
[18]
Related Work A.1
11 AnimationBench: Are Video Models Good at Character-Centric Animation? A. Related Work A.1. Video Generation Benchmark and Evaluation Evaluating video generation models has been a persistent challenge in recent years. Benchmarks such as the VBench series (Huang et al., 2024; 2025; Zheng et al.,
2024
-
[19]
benchmark have introduced relevant criteria for animated content, existing frameworks remain largely adapted from conventional video evaluation and do not specifically address the unique demands and challenges of animation video generation. A.2. Animation Video Generation The development of diffusion models has driven significant progress in general video...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.