Recognition: unknown
Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation
Pith reviewed 2026-05-10 11:41 UTC · model grok-4.3
The pith
Sign language translation improves when models reason through an ordered sequence of latent thoughts before generating text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
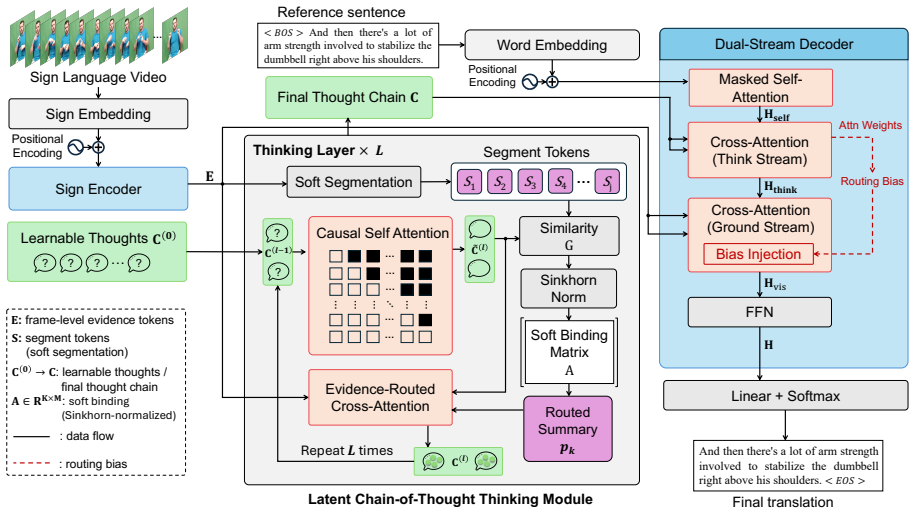
Many SLT systems quietly assume that brief chunks of signing map directly to spoken-language words, but this breaks down because signers often create meaning on the fly using context, space, and movement. The paper therefore treats SLT as mainly a cross-modal reasoning task. It introduces a reasoning-driven framework that places an ordered sequence of latent thoughts as an explicit middle layer between the video and the generated text so that meaning is extracted and organized gradually over time. On top of this, plan-then-ground decoding lets the model first decide what it wants to say and then look back at the video to find supporting evidence, which improves coherence and faithfulness. A新
What carries the argument
Ordered sequence of latent thoughts as an explicit middle layer for gradual meaning extraction, combined with plan-then-ground decoding that separates output planning from video grounding.
If this is right
- Translations gain coherence and faithfulness by separating the decision of what to say from later evidence checking in the video.
- The model handles dynamic use of context, space, and movement in signing more naturally than direct-mapping approaches.
- Consistent performance gains appear over prior gloss-free methods across multiple benchmarks.
- The released dataset supplies stronger context dependencies for testing future reasoning-based SLT systems.
Where Pith is reading between the lines
- The same latent-thought middle layer could be tested on other video-to-text tasks that involve evolving context, such as action captioning.
- Plan-then-ground decoding might lower hallucination rates in long outputs by forcing explicit grounding checks.
- The new dataset could serve as a stress test for any cross-modal model that must track meaning built across an entire sequence rather than local chunks.
Load-bearing premise
That the main failure mode in gloss-free SLT is the assumption of direct chunk-to-word mapping and that latent thoughts plus plan-then-ground can be learned effectively without gloss supervision or extra constraints.
What would settle it
An ablation experiment on the new dataset that removes the latent thoughts layer and plan-then-ground step and still matches or exceeds the full model's translation quality would show the reasoning machinery is not required.
Figures



read the original abstract
Many SLT systems quietly assume that brief chunks of signing map directly to spoken-language words. That assumption breaks down because signers often create meaning on the fly using context, space, and movement. We revisit SLT and argue that it is mainly a cross-modal reasoning task, not just a straightforward video-to-text conversion. We thus introduce a reasoning-driven SLT framework that uses an ordered sequence of latent thoughts as an explicit middle layer between the video and the generated text. These latent thoughts gradually extract and organize meaning over time. On top of this, we use a plan-then-ground decoding method: the model first decides what it wants to say, and then looks back at the video to find the evidence. This separation improves coherence and faithfulness. We also built and released a new large-scale gloss-free SLT dataset with stronger context dependencies and more realistic meanings. Experiments across several benchmarks show consistent gains over existing gloss-free methods. Our code and data are available at https://github.com/fletcherjiang/SignThought.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that gloss-free sign language translation (SLT) is primarily a cross-modal reasoning task rather than a direct video-to-text mapping. It introduces a reasoning-driven framework that inserts an ordered sequence of latent thoughts as an explicit middle layer between video input and generated text, with these thoughts gradually extracting and organizing meaning over time. This is combined with a plan-then-ground decoding strategy in which the model first plans the output and then grounds it by referencing the video evidence. A new large-scale gloss-free SLT dataset with stronger context dependencies is released, and experiments report consistent gains over prior gloss-free methods.
Significance. If the latent thoughts can be shown to function as interpretable, temporally ordered reasoning steps rather than arbitrary internal states, the work could meaningfully shift SLT research toward more explicit reasoning paradigms that better handle contextual, spatial, and non-literal aspects of signing. The public release of code and the new dataset would further support reproducibility and progress on gloss-free settings.
major comments (2)
- [Abstract] Abstract: the central claim that an 'ordered sequence of latent thoughts' forms an explicit middle layer that 'gradually extract[s] and organize[s] meaning over time' is load-bearing, yet the abstract provides no description of the training objective, auxiliary losses, or regularization terms that would enforce ordering or semantic content in the latent sequence. Without such constraints the layer could collapse, rendering performance gains attributable to the new dataset or other architectural changes rather than the proposed reasoning paradigm.
- [Abstract] Abstract: the plan-then-ground decoding method is presented as separating planning from grounding to improve coherence and faithfulness, but no implementation details, loss formulations, or architectural diagrams are referenced that would allow verification of how the two stages interact with the latent-thought layer during training and inference.
minor comments (1)
- The abstract states that experiments show 'consistent gains over existing gloss-free methods' across 'several benchmarks' but supplies neither the specific benchmarks nor any quantitative results, tables, or ablation studies, which hinders immediate assessment of the magnitude and robustness of the improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our core contributions. We agree that the abstract requires expansion to better support the central claims and have revised it accordingly to include brief references to the training objectives, auxiliary losses, and decoding implementation. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that an 'ordered sequence of latent thoughts' forms an explicit middle layer that 'gradually extract[s] and organize[s] meaning over time' is load-bearing, yet the abstract provides no description of the training objective, auxiliary losses, or regularization terms that would enforce ordering or semantic content in the latent sequence. Without such constraints the layer could collapse, rendering performance gains attributable to the new dataset or other architectural changes rather than the proposed reasoning paradigm.
Authors: We acknowledge that the original abstract was too concise on this point and did not reference the mechanisms that enforce ordering and semantic content. In the full manuscript, Section 3.2 defines the training objective as a joint loss combining the primary sequence-to-sequence cross-entropy with an auxiliary contrastive loss over consecutive latent thoughts (to promote temporal ordering) and a mutual-information regularization term (to discourage collapse to uninformative states). Ablation experiments in Section 5.3 demonstrate that removing these terms reduces performance to levels comparable with prior gloss-free baselines, supporting that the gains are tied to the reasoning layer rather than solely the new dataset. We have revised the abstract to include a short clause referencing these constraints. revision: yes
-
Referee: [Abstract] Abstract: the plan-then-ground decoding method is presented as separating planning from grounding to improve coherence and faithfulness, but no implementation details, loss formulations, or architectural diagrams are referenced that would allow verification of how the two stages interact with the latent-thought layer during training and inference.
Authors: We agree the abstract omitted implementation specifics. Section 4.2 of the manuscript details the plan-then-ground decoder: the planning stage generates an intermediate plan token sequence conditioned on the latent thoughts, while the grounding stage performs cross-attention to video features using a dedicated grounding loss (a combination of token-level reconstruction and attention alignment). The two stages share parameters with the latent-thought encoder and are trained end-to-end with a staged curriculum that first optimizes planning then jointly optimizes grounding. A diagram illustrating the interaction is provided in Figure 3. We have updated the abstract to reference this section and added a pointer to the supplementary architectural diagram. revision: yes
Circularity Check
New architectural choices with no derivation chain or self-referential reductions
full rationale
The paper introduces a reasoning-driven framework with latent thoughts as an explicit middle layer and plan-then-ground decoding, plus a new dataset, as architectural and data contributions rather than mathematical derivations. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any central claim to its own inputs by construction. The claims rest on the novelty of the paradigm and empirical gains, which do not exhibit self-definitional, fitted-prediction, or uniqueness-imported circularity. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
latent thoughts
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Mol-Debate: Multi-Agent Debate Improves Structural Reasoning in Molecular Design
Mol-Debate applies multi-agent debate in an iterative loop with perspective orchestration to achieve state-of-the-art text-guided molecular design, scoring 59.82% exact match on ChEBI-20 and 50.52% weighted success on...
Reference graph
Works this paper leans on
-
[1]
Nikolas Adaloglou, Theocharis Chatzis, Ilias Papastratis, Andreas Stergioulas, Georgios Th Papadopoulos, Vassia Zacharopoulou, George J Xydopoulos, Klimnis Atzakas, Dimitris Papazachariou, and Petros Daras. 2021. A comprehensive study on deep learning-based methods for sign language recognition. IEEE transactions on multimedia, 24:1750--1762
2021
-
[2]
Samuel Albanie, G \"u l Varol, Liliane Momeni, Triantafyllos Afouras, Joon Son Chung, Neil Fox, and Andrew Zisserman. 2020. Bsl-1k: Scaling up co-articulated sign language recognition using mouthing cues. In Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XI 16, pages 35--53. Springer
2020
-
[3]
Sign language translation based on transformers for the how2sign dataset
Patricia Cabot Alvarez, Xavier Gir \'o Nieto, and Laia Tarr \'e s Benet. Sign language translation based on transformers for the how2sign dataset
-
[4]
Danielle Bragg, Oscar Koller, Mary Bellard, Larwan Berke, Patrick Boudreault, Annelies Braffort, Naomi Caselli, Matt Huenerfauth, Hernisa Kacorri, and Tessa Verhoef. 2019. Sign language recognition, generation, and translation: An interdisciplinary perspective. In Proceedings of the 21st international ACM SIGACCESS conference on computers and accessibilit...
2019
-
[5]
Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. 2018. Neural sign language translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7784--7793
2018
-
[6]
Necati Cihan Camgoz, Oscar Koller, Simon Hadfield, and Richard Bowden. 2020. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10023--10033
2020
-
[7]
Yutong Chen, Fangyun Wei, Xiao Sun, Zhirong Wu, and Stephen Lin. 2022 a . A simple multi-modality transfer learning baseline for sign language translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5120--5130
2022
-
[8]
Yutong Chen, Ronglai Zuo, Fangyun Wei, Yu Wu, Shujie Liu, and Brian Mak. 2022 b . Two-stream network for sign language recognition and translation. Advances in Neural Information Processing Systems, 35:17043--17056
2022
-
[9]
Zhigang Chen, Benjia Zhou, Yiqing Huang, Jun Wan, Yibo Hu, Hailin Shi, Yanyan Liang, Zhen Lei, and Du Zhang. 2024 a . C ^2 rl: Content and context representation learning for gloss-free sign language translation and retrieval
2024
-
[10]
Zhigang Chen, Benjia Zhou, Jun Li, Jun Wan, Zhen Lei, Ning Jiang, Quan Lu, and Guoqing Zhao. 2024 b . Factorized learning assisted with large language model for gloss-free sign language translation. pages 7071--7081
2024
-
[11]
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. 2026. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 20463--20471
2026
-
[12]
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. 2025. Offset: Segmentation-based focus shift revision for composed image retrieval. In Proceedings of the ACM International Conference on Multimedia, page 6113–6122
2025
-
[13]
Ka Leong Cheng, Zhaoyang Yang, Qifeng Chen, and Yu-Wing Tai. 2020. Fully convolutional networks for continuous sign language recognition. In Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXIV 16, pages 697--714. Springer
2020
-
[14]
Kearsy Cormier, David Quinto-Pozos, Zed Sevcikova, and Adam Schembri. 2012. Lexicalisation and de-lexicalisation processes in sign languages: Comparing depicting constructions and viewpoint gestures. Language & communication, 32(4):329--348
2012
-
[15]
Haonan Dong, Kehan Jiang, Haoran Ye, Wenhao Zhu, Zhaolu Kang, and Guojie Song. 2026. https://arxiv.org/abs/2604.02972 Neureasoner: Towards explainable, controllable, and unified reasoning via mixture-of-neurons . Preprint, arXiv:2604.02972
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giro i Nieto. 2021. https://arxiv.org/abs/2008.08143 How2sign: A large-scale multimodal dataset for continuous american sign language . Preprint, arXiv:2008.08143
-
[17]
Jens Forster, Christoph Schmidt, Oscar Koller, Martin Bellgardt, and Hermann Ney. 2014. Extensions of the sign language recognition and translation corpus rwth-phoenix-weather. In LREC, pages 1911--1916
2014
-
[18]
Jia Gong, Lin Geng Foo, Yixuan He, Hossein Rahmani, and Jun Liu. 2024. Llms are good sign language translators. In CVPR, pages 18362--18372
2024
-
[19]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2025. https://arxiv.org/abs/2412.06769 Training large language models to reason in a continuous latent space . Preprint, arXiv:2412.06769
work page internal anchor Pith review arXiv 2025
-
[20]
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. 2026. Refine: Composed video retrieval via shared and differential semantics enhancement. ACM Transactions on Multimedia Computing, Communications and Applications
2026
-
[21]
Jiani Huang, Shijie Wang, Liangbo Ning, Wenqi Fan, Shuaiqiang Wang, Dawei Yin, and Qing Li. 2026. Towards next-generation recommender systems: A benchmark for personalized recommendation assistant with llms. In Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining, pages 217--226
2026
- [22]
-
[23]
Kehan Jiang, Haonan Dong, Zhaolu Kang, Zhengzhou Zhu, and Guojie Song. 2026 a . https://arxiv.org/abs/2604.02967 Foe: Forest of errors makes the first solution the best in large reasoning models . Preprint, arXiv:2604.02967
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Yiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong Wei. 2026 b . https://doi.org/10.1109/TMI.2025.3637237 Self-paced learning for images of antinuclear antibodies . IEEE Transactions on Medical Imaging, 45(4):1661--1672
-
[25]
Yiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiao-Yong Wei, Chang Wen Chen, and Qing Li. 2024. https://doi.org/10.1145/3664647.3681115 Prior knowledge integration via llm encoding and pseudo event regulation for video moment retrieval . In Proceedings of the 32nd ACM International Conference on Multimedia, MM '24, page 7249–7258, New York, NY, USA. Association...
-
[26]
Peiqi Jiao, Yuecong Min, and Xilin Chen. 2024. Visual alignment pre-training for sign language translation. In European Conference on Computer Vision, pages 349--367. Springer
2024
-
[27]
Oscar Koller, Jens Forster, and Hermann Ney. 2015. Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Computer Vision and Image Understanding, 141:108--125
2015
-
[28]
Oscar Koller, Sepehr Zargaran, and Hermann Ney. 2017. https://doi.org/10.1109/CVPR.2017.364 Re-sign: Re-aligned end-to-end sequence modelling with deep recurrent cnn-hmms . In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3416--3424
-
[29]
Dongxu Li, Cristian Rodriguez, Xin Yu, and Hongdong Li. 2020 a . Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1459--1469
2020
-
[30]
Dongxu Li, Chenchen Xu, Xin Yu, Kaihao Zhang, Benjamin Swift, Hanna Suominen, and Hongdong Li. 2020 b . Tspnet: Hierarchical feature learning via temporal semantic pyramid for sign language translation. Advances in Neural Information Processing Systems, 33:12034--12045
2020
- [31]
-
[32]
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. 2026 a . Retrack: Evidence-driven dual-stream directional anchor calibration network for composed video retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23373--23381
2026
-
[33]
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. 2026 b . Habit: Chrono-synergia robust progressive learning framework for composed image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6762--6770
2026
-
[34]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74--81
2004
- [35]
- [36]
-
[37]
Peiyang Liu, Xi Wang, Ziqiang Cui, and Wei Ye. 2025 b . Queries are not alone: Clustering text embeddings for video search. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 874--883
2025
-
[38]
Peiyang Liu, Jinyu Yang, Lin Wang, Sen Wang, Yunlai Hao, and Huihui Bai. 2023. Retrieval-based unsupervised noisy label detection on text data. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 4099--4104
2023
-
[39]
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. 2024. Compositional chain-of-thought prompting for large multimodal models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14420--14431
2024
-
[40]
Chong-Wah Ngo, Yu-Gang Jiang, Xiao-Yong Wei, Wanlei Zhao, Feng Wang, Xiao Wu, and Hung-Khoon Tan. 2008. Beyond semantic search: What you observe may not be what you think. In IEEE Computer Society
2008
-
[41]
Shuo Ni, Di Wang, He Chen, Haonan Guo, Ning Zhang, and Jing Zhang. 2025. Unigeoseg: Towards unified open-world segmentation for geospatial scenes. arXiv preprint arXiv:2511.23332
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
-
[43]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311--318
2002
-
[44]
Bowen Shi, Diane Brentari, Greg Shakhnarovich, and Karen Livescu. 2022 a . Open-domain sign language translation learned from online video. In EMNLP
2022
- [45]
-
[46]
Laia Tarr \'e s, Gerard I G \'a llego, Amanda Duarte, Jordi Torres, and Xavier Gir \'o -i Nieto. 2023. Sign language translation from instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5624--5634
2023
- [47]
- [48]
-
[49]
Andreas Voskou, Konstantinos P Panousis, Dimitrios Kosmopoulos, Dimitris N Metaxas, and Sotirios Chatzis. 2021. Stochastic transformer networks with linear competing units: Application to end-to-end sl translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11946--11955
2021
-
[50]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . Preprint, arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review arXiv 2023
-
[52]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[53]
Ryan Wong, Necati Cihan Camgoz, and Richard Bowden. 2024. Sign2 GPT : Leveraging large language models for gloss-free sign language translation. In ICLR
2024
-
[54]
Zhen-Qun Yang Xiao-Yong Wei. 2013. Coaching the exploration and exploitation in active learning for interactive video retrieval. IEEE Transactions on Image Processing, 22(3):955--968
2013
-
[55]
Can Xie, Ruotong Pan, Xiangyu Wu, Yunfei Zhang, Jiayi Fu, Tingting Gao, and Guorui Zhou. 2025. Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning. arXiv preprint arXiv:2510.10649
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Kevin Xu and Issei Sato. 2025. https://arxiv.org/abs/2509.25239 A formal comparison between chain-of-thought and latent thought . Preprint, arXiv:2509.25239
work page internal anchor Pith review arXiv 2025
- [57]
-
[58]
Jiayu Yao, He Chen, Yizhuang Xie, Ning Zhang, Mingxu Yang, and Liang Chen. 2025. S 2 net: Spatial-aligned and semantic-discriminative network for remote sensing object detection. IEEE Transactions on Geoscience and Remote Sensing
2025
-
[59]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. https://arxiv.org/abs/2210.03629 React: Synergizing reasoning and acting in language models . Preprint, arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations
2022
-
[61]
Aoxiong Yin, Tianyun Zhong, Li Tang, Weike Jin, Tao Jin, and Zhou Zhao. 2023. Gloss attention for gloss-free sign language translation. In ICCV, pages 2551--2562
2023
- [62]
- [63]
-
[64]
Biao Zhang, Mathias M \"u ller, and Rico Sennrich. 2023. SLTUNET : A simple unified model for sign language translation. In ICLR
2023
-
[65]
Ning Zhang, Shuo Ni, Liang Chen, Tong Wang, and He Chen. 2025 a . High-throughput and energy-efficient fpga-based accelerator for all adder neural networks. IEEE Internet of Things Journal
2025
-
[66]
Wengyu Zhang, Qi Tian, Yi Cao, Wenqi Fan, Dongmei Jiang, Yaowei Wang, Qing Li, and Xiao-Yong Wei. 2025 b . Graphatc: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learning. Briefings in bioinformatics, 26(2):bbaf194
2025
-
[67]
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2024. https://arxiv.org/abs/2302.00923 Multimodal chain-of-thought reasoning in language models . Preprint, arXiv:2302.00923
work page internal anchor Pith review arXiv 2024
-
[68]
Rui Zhao, Liang Zhang, Biao Fu, Cong Hu, Jinsong Su, and Yidong Chen. 2024. Conditional variational autoencoder for sign language translation with cross-modal alignment. In AAAI, pages 19643--19651
2024
-
[69]
Benjia Zhou, Zhigang Chen, Albert Clap \'e s, Jun Wan, Yanyan Liang, Sergio Escalera, Zhen Lei, and Du Zhang. 2023. Gloss-free sign language translation: Improving from visual-language pretraining. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20871--20881
2023
-
[70]
Hao Zhou, Wengang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. 2021. Improving sign language translation with monolingual data by sign back-translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1316--1325
2021
- [71]
-
[72]
Xiaoling Zhou, Wei Ye, Zhemg Lee, Lei Zou, and Shikun Zhang. 2025. Valuing training data via causal inference for in-context learning. IEEE Transactions on Knowledge and Data Engineering
2025
-
[73]
Xiaoling Zhou, Wei Ye, Yidong Wang, Chaoya Jiang, Zhemg Lee, Rui Xie, and Shikun Zhang. 2024 b . Enhancing in-context learning via implicit demonstration augmentation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2810--2828
2024
-
[74]
Inge Zwitserlood. 2012. Classifiers. In Sign language: An international handbook. de Gruyter
2012
-
[75]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[76]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.