Recognition: unknown
Generalization in LLM Problem Solving: The Case of the Shortest Path
Pith reviewed 2026-05-10 10:34 UTC · model grok-4.3
The pith
Language models transfer to unseen maps in shortest-path tasks but fail on longer paths due to recursive instability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a synthetic shortest-path planning environment that cleanly separates spatial transfer from length scaling, language models exhibit strong performance on unseen maps but consistently fail when required to solve longer-horizon instances. The failures trace to recursive instability during inference. Data coverage determines the upper bound on solvable path lengths, reinforcement learning improves training dynamics without expanding that bound, and inference-time scaling raises accuracy on short instances yet cannot overcome the length-scaling collapse.
What carries the argument
A synthetic shortest-path planning environment that supports two orthogonal generalization axes: spatial transfer to unseen maps and length scaling to longer-horizon problems.
If this is right
- Data coverage during training directly determines the maximum path length models can reliably solve.
- Reinforcement learning stabilizes training but leaves the fundamental length limits set by data unchanged.
- Inference-time scaling improves accuracy on short problems yet cannot correct recursive instability on longer ones.
- The observed pattern indicates that current model architectures lack stable mechanisms for recursive planning steps.
Where Pith is reading between the lines
- The same spatial-success and length-failure pattern may appear in other sequential tasks such as puzzle solving or multi-step reasoning.
- Architectures that explicitly manage recursion depth could extend the length scaling that current models lack.
- The factor-separation approach used here can diagnose generalization limits in planning problems beyond graphs.
Load-bearing premise
The synthetic shortest-path environment cleanly isolates the effects of data coverage, training paradigm, and inference strategy without introducing task-specific artifacts that would not appear in other sequential problems.
What would settle it
Training models on paths of maximum length 10 and testing them on paths of length 20 while holding all other factors fixed would directly test whether recursive instability produces the observed length-scaling failure.
Figures















read the original abstract
Whether language models can systematically generalize remains actively debated. Yet empirical performance is jointly shaped by multiple factors such as training data, training paradigms, and inference-time strategies, making failures difficult to interpret. We introduce a controlled synthetic environment based on shortest-path planning, a canonical composable sequential optimization problem. The setup enables clean separation of these factors and supports two orthogonal axes of generalization: spatial transfer to unseen maps and length scaling to longer-horizon problems. We find that models exhibit strong spatial transfer but consistently fail under length scaling due to recursive instability. We further analyze how distinct stages of the learning pipeline influence systematic problem-solving: for example, data coverage sets capability limits; reinforcement learning improves training stability but does not expand those limits; and inference-time scaling enhances performance but cannot rescue length-scaling failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a controlled synthetic shortest-path planning environment to study LLM generalization along two axes: spatial transfer to unseen maps and length scaling to longer-horizon problems. It reports that models show strong spatial transfer but consistently fail under length scaling, attributing this to recursive instability. The work further examines pipeline stages, finding that data coverage sets capability limits, reinforcement learning improves training stability without expanding those limits, and inference-time scaling boosts performance but cannot overcome length-scaling failures.
Significance. If the results hold, the controlled synthetic setup provides a clean testbed for isolating effects of data coverage, training paradigms, and inference strategies on systematic problem-solving in sequential tasks. This separation is a strength, as is the focus on reproducible synthetic environments that support falsifiable claims about generalization axes. The findings could guide improvements in LLM planning capabilities, particularly by highlighting barriers to length scaling.
major comments (1)
- Abstract and analysis of length scaling: the attribution of failures to 'recursive instability' lacks an independent operational definition or diagnostic (e.g., measurable error accumulation across recursive subproblem solutions or divergence as a function of recursion depth). Without this, the explanation risks circularity with the observed performance drop itself, rather than isolating the mechanism from alternatives like context limits or graph representation in text. This is load-bearing for the central interpretation of why length scaling fails while spatial transfer succeeds.
minor comments (2)
- Methods section: the description of the synthetic environment and how it cleanly isolates factors could include more explicit pseudocode or parameter settings to aid reproducibility.
- Results presentation: quantitative metrics for 'strong spatial transfer' and 'recursive instability' should be accompanied by error bars or statistical tests across multiple runs and model scales.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of the work's potential contribution. We address the single major comment below and have revised the manuscript to strengthen the analysis of length scaling.
read point-by-point responses
-
Referee: Abstract and analysis of length scaling: the attribution of failures to 'recursive instability' lacks an independent operational definition or diagnostic (e.g., measurable error accumulation across recursive subproblem solutions or divergence as a function of recursion depth). Without this, the explanation risks circularity with the observed performance drop itself, rather than isolating the mechanism from alternatives like context limits or graph representation in text. This is load-bearing for the central interpretation of why length scaling fails while spatial transfer succeeds.
Authors: We agree that an explicit, independent operational definition is required to avoid any appearance of circularity and to better isolate the proposed mechanism. In the revised manuscript we introduce a new subsection that defines recursive instability as the measurable compounding of local subproblem errors with increasing recursion depth. We operationalize this via two diagnostics: (1) the rate at which predicted subpath lengths diverge from optimal values as depth grows, computed on fixed-length prompts that hold context size constant, and (2) an ablation that varies textual graph encodings while keeping depth fixed. These metrics are reported alongside the original length-scaling curves and demonstrate that error accumulation tracks horizon length even when context limits and representation format are controlled, thereby supporting the differential explanation for spatial transfer versus length scaling. revision: yes
Circularity Check
No circularity detected in empirical generalization analysis
full rationale
The paper introduces a new synthetic shortest-path environment to isolate factors like data coverage, training paradigms, and inference strategies, then reports empirical observations on spatial transfer success versus length-scaling failures. Central claims rest on controlled experimental results rather than any derivation that reduces by construction to fitted inputs, self-definitions, or self-citation chains. Terms such as 'recursive instability' function as post-hoc descriptive labels for observed performance drops and do not create a self-referential loop where the explanation is equivalent to the input data by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The synthetic shortest-path environment cleanly separates training data, training paradigms, and inference-time strategies
Reference graph
Works this paper leans on
-
[1]
Amirhesam Abedsoltan, Huaqing Zhang, Kaiyue Wen, Hongzhou Lin, Jingzhao Zhang, and Mikhail Belkin. Task generalization with autoregressive compositional structure: Can learning fromd tasks generalize tod {t} tasks?arXiv preprint arXiv:2502.08991,
-
[2]
On provable length and compositional generalization.arXiv preprint arXiv:2402.04875,
Kartik Ahuja and Amin Mansouri. On provable length and compositional generalization.arXiv preprint arXiv:2402.04875,
-
[3]
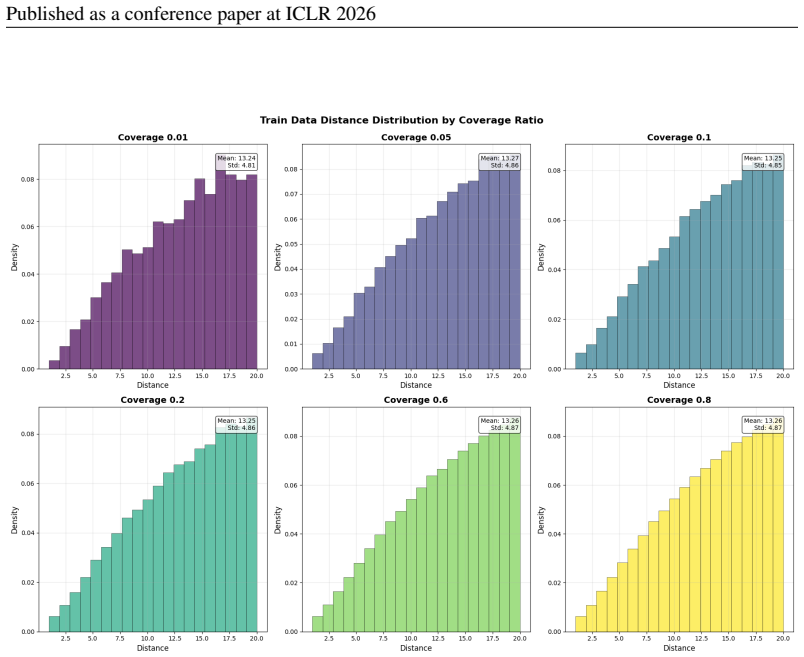
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi
URLhttps://github.com/meta-llama/ llama3/blob/main/MODEL_CARD.md. Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computa...
2019
-
[4]
Association for Computational Lin- guistics. doi: 10.18653/v1/N19-1245. URLhttps://aclanthology.org/N19-1245. Cem Anil, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Am- brose Slone, Guy Gur-Ari, Ethan Dyer, and Behnam Neyshabur. Exploring length generalization in large language models. InAdvances in Neural Information Proce...
-
[5]
arXiv preprint arXiv:1811.12889 , year=
Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Systematic generalization: what is required and can it be learned?arXiv preprint arXiv:1811.12889,
-
[6]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
URLhttps: //matharena.ai/. Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review arXiv
-
[7]
Ziyang Cai, Nayoung Lee, Avi Schwarzschild, Samet Oymak, and Dimitris Papailiopoulos. Ex- trapolation by association: Length generalization transfer in transformers.arXiv preprint arXiv:2506.09251,
-
[8]
Hoyeon Chang, Jinho Park, Hanseul Cho, Sohee Yang, Miyoung Ko, Hyeonbin Hwang, Seungpil Won, Dohaeng Lee, Youbin Ahn, and Minjoon Seo. The coverage principle: A framework for understanding compositional generalization.arXiv preprint arXiv:2505.20278,
-
[9]
arXiv preprint arXiv:2504.11468 , year=
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models. arXiv preprint arXiv:2504.11468,
-
[10]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161,
work page internal anchor Pith review arXiv
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Spectral journey: How trans- formers predict the shortest path.arXiv preprint arXiv:2502.08794,
11 Published as a conference paper at ICLR 2026 Andrew Cohen, Andrey Gromov, Kaiyu Yang, and Yuandong Tian. Spectral journey: How trans- formers predict the shortest path.arXiv preprint arXiv:2502.08794,
-
[13]
Róbert Csordás, Kazuki Irie, and Jürgen Schmidhuber. Ctl++: Evaluating generalization on never- seen compositional patterns of known functions, and compatibility of neural representations. arXiv preprint arXiv:2210.06350,
-
[14]
Xinnan Dai, Qihao Wen, Yifei Shen, Hongzhi Wen, Dongsheng Li, Jiliang Tang, and Caihua Shan. Revisiting the graph reasoning ability of large language models: Case studies in translation, con- nectivity and shortest path.arXiv preprint arXiv:2408.09529,
-
[15]
Verna Dankers, Elia Bruni, and Dieuwke Hupkes. The paradox of the compositionality of natural language: A neural machine translation case study.arXiv preprint arXiv:2108.05885,
-
[17]
arXiv preprint arXiv:2409.15647 (2024)
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[18]
A general theory for compositional generalization.arXiv preprint arXiv:2405.11743,
Jingwen Fu, Zhizheng Zhang, Yan Lu, and Nanning Zheng. A general theory for compositional generalization.arXiv preprint arXiv:2405.11743,
-
[19]
Compositional generalization in semantic parsing: Pre-training vs
Daniel Furrer, Marc van Zee, Nathan Scales, and Nathanael Schärli. Compositional generalization in semantic parsing: Pre-training vs. specialized architectures.arXiv preprint arXiv:2007.08970,
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
12 Published as a conference paper at ICLR 2026 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938,
work page internal anchor Pith review arXiv
-
[22]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[23]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review arXiv
-
[24]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian
Samy Jelassi, Stéphane d’Ascoli, Carles Domingo-Enrich, Yuhuai Wu, Yuanzhi Li, and François Charton. Length generalization in arithmetic transformers.arXiv preprint arXiv:2306.15400,
-
[25]
URLhttps://openreview. net/forum?id=VTF8yNQM66. Mason Kamb and Surya Ganguli. An analytic theory of creativity in convolutional diffusion models. arXiv preprint arXiv:2412.20292,
-
[26]
arXiv preprint arXiv:1912.09713 , year=
Daniel Keysers, Nathanael Schärli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashu- bin, Nikola Momchev, Danila Sinopalnikov, Lukasz Stafiniak, Tibor Tihon, et al. Measur- ing compositional generalization: A comprehensive method on realistic data.arXiv preprint arXiv:1912.09713,
-
[27]
Najoung Kim and Tal Linzen. Cogs: A compositional generalization challenge based on semantic interpretation.arXiv preprint arXiv:2010.05465,
-
[28]
arXiv preprint arXiv:2505.00661 , year=
Andrew K Lampinen, Arslan Chaudhry, Stephanie CY Chan, Cody Wild, Diane Wan, Alex Ku, Jörg Bornschein, Razvan Pascanu, Murray Shanahan, and James L McClelland. On the generalization of language models from in-context learning and finetuning: a controlled study.arXiv preprint arXiv:2505.00661,
-
[29]
Martha Lewis, Nihal V Nayak, Peilin Yu, Qinan Yu, Jack Merullo, Stephen H Bach, and Ellie Pavlick. Does clip bind concepts? probing compositionality in large image models.arXiv preprint arXiv:2212.10537,
-
[30]
Emergent world representations: Exploring a sequence model trained on a synthetic task
13 Published as a conference paper at ICLR 2026 Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Watten- berg. Emergent world representations: Exploring a sequence model trained on a synthetic task. ICLR, 2023a. Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoy...
2026
-
[31]
When does compositional structure yield compositional gener- alization? a kernel theory
Samuel Lippl and Kim Stachenfeld. When does compositional structure yield compositional gener- alization? a kernel theory. InThe Thirteenth International Conference on Learning Representa- tions. Adam Liška, Germán Kruszewski, and Marco Baroni. Memorize or generalize? searching for a compositional rnn in a haystack.arXiv preprint arXiv:1802.06467,
-
[32]
Scaling up rl: Unlocking diverse reasoning in llms via prolonged training,
Mingjie Liu, Shizhe Diao, Jian Hu, Ximing Lu, Xin Dong, Hao Zhang, Alexander Bukharin, Shaokun Zhang, Jiaqi Zeng, Makesh Narsimhan Sreedhar, et al. Scaling up rl: Unlocking di- verse reasoning in llms via prolonged training.arXiv preprint arXiv:2507.12507, 2025a. Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. P...
-
[33]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Bin Cui, et al. Learning what reinforcement learning can’t: In- terleaved online fine-tuning for hardest questions.arXiv preprint arXiv:2506.07527,
-
[34]
arXiv preprint arXiv:2310.17022 , year=
Sidharth Mudgal, Jong Lee, Harish Ganapathy, YaGuang Li, Tao Wang, Yanping Huang, Zhifeng Chen, Heng-Tze Cheng, Michael Collins, Trevor Strohman, et al. Controlled decoding from language models.arXiv preprint arXiv:2310.17022,
-
[35]
The eos decision and length extrapolation.arXiv preprint arXiv:2010.07174,
Benjamin Newman, John Hewitt, Percy Liang, and Christopher D Manning. The eos decision and length extrapolation.arXiv preprint arXiv:2010.07174,
-
[36]
Yaniv Nikankin, Anja Reusch, Aaron Mueller, and Yonatan Belinkov. Arithmetic without algo- rithms: Language models solve math with a bag of heuristics.arXiv preprint arXiv:2410.21272,
-
[37]
Making transformers solve compositional tasks.arXiv preprint arXiv:2108.04378,
Santiago Ontanon, Joshua Ainslie, Vaclav Cvicek, and Zachary Fisher. Making transformers solve compositional tasks.arXiv preprint arXiv:2108.04378,
-
[38]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277,
work page internal anchor Pith review arXiv
-
[39]
arXiv preprint arXiv:2310.19956 , year=
Jackson Petty, Sjoerd van Steenkiste, Ishita Dasgupta, Fei Sha, Dan Garrette, and Tal Linzen. The impact of depth on compositional generalization in transformer language models.arXiv preprint arXiv:2310.19956,
-
[40]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein
14 Published as a conference paper at ICLR 2026 Philip Quirke and Fazl Barez. Understanding addition in transformers.arXiv preprint arXiv:2310.13121,
-
[41]
Understanding addition and subtraction in transformers.arXiv preprint arXiv:2402.02619, 2024
Philip Quirke, Clement Neo, and Fazl Barez. Arithmetic in transformers explained.arXiv preprint arXiv:2402.02619,
-
[42]
URLhttps://arxiv.org/abs/2412.15115. Rahul Ramesh, Ekdeep Singh Lubana, Mikail Khona, Robert P Dick, and Hidenori Tanaka. Com- positional capabilities of autoregressive transformers: A study on synthetic, interpretable tasks. arXiv preprint arXiv:2311.12997,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Attention as a hypernetwork.arXiv preprint arXiv:2406.05816,
Simon Schug, Seijin Kobayashi, Yassir Akram, João Sacramento, and Razvan Pascanu. Attention as a hypernetwork.arXiv preprint arXiv:2406.05816,
-
[44]
Sania Sinha, Tanawan Premsri, and Parisa Kordjamshidi. A survey on compositional learning of ai models: Theoretical and experimental practices.arXiv preprint arXiv:2406.08787,
-
[45]
Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhiwei Steven Wu, and J
Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhiwei Steven Wu, and J Andrew Bagnell. All roads lead to likelihood: The value of reinforcement learning in fine-tuning.arXiv preprint arXiv:2503.01067,
-
[46]
URLhttps://qwenlm. github.io/blog/qwen2.5/. Guiyao Tie, Zeli Zhao, Dingjie Song, Fuyang Wei, Rong Zhou, Yurou Dai, Wen Yin, Zhejian Yang, Jiangyue Yan, Yao Su, et al. Large language models post-training: Surveying techniques from alignment to reasoning.arXiv preprint arXiv:2503.06072,
-
[47]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
-
[48]
Yuxiang Wang, Xinnan Dai, Wenqi Fan, and Yao Ma. Exploring graph tasks with pure llms: A comprehensive benchmark and investigation.arXiv preprint arXiv:2502.18771, 2025a. Zehong Wang, Zheyuan Liu, Tianyi Ma, Jiazheng Li, Zheyuan Zhang, Xingbo Fu, Yiyang Li, Zhengqing Yuan, Wei Song, Yijun Ma, et al. Graph foundation models: A comprehensive survey. arXiv p...
-
[49]
15 Published as a conference paper at ICLR 2026 Thaddäus Wiedemer, Jack Brady, Alexander Panfilov, Attila Juhos, Matthias Bethge, and Wieland Brendel. Provable compositional generalization for object-centric learning.arXiv preprint arXiv:2310.05327, 2023a. Thaddäus Wiedemer, Prasanna Mayilvahanan, Matthias Bethge, and Wieland Brendel. Composi- tional gene...
-
[50]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pp. 38–45,
2020
-
[51]
arXiv preprint arXiv:2507.14843 , year=
Fang Wu, Weihao Xuan, Ximing Lu, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may not escape its origin, 2025.URL https://arxiv. org/abs/2507.14843. Zhuoyan Xu, Zhenmei Shi, and Yingyu Liang. Do large language models have compositional abil- ity? an investigation into limitations and scalability.arXiv preprint arXiv:2407.15720,
-
[52]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does re- inforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025a. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does re- inforcement learning really incentivize re...
-
[53]
Improving llms’ generalized reasoning abilities by graph problems.arXiv preprint arXiv:2507.17168,
Qifan Zhang, Nuo Chen, Zehua Li, Miao Peng, Jing Tang, and Jia Li. Improving llms’ generalized reasoning abilities by graph problems.arXiv preprint arXiv:2507.17168,
-
[54]
Can llm graph reasoning generalize beyond pattern memorization?arXiv preprint arXiv:2406.15992,
Yizhuo Zhang, Heng Wang, Shangbin Feng, Zhaoxuan Tan, Xiaochuang Han, Tianxing He, and Yulia Tsvetkov. Can llm graph reasoning generalize beyond pattern memorization?arXiv preprint arXiv:2406.15992,
-
[55]
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, and Xuanjing Huang. Exploring the compositional deficiency of large language models in mathematical reasoning.arXiv preprint arXiv:2405.06680,
-
[56]
What Algorithms Can Transformers Learn? A Study in Length Generalization,
Hattie Zhou, Arwen Bradley, Etai Littwin, Noam Razin, Omid Saremi, Josh Susskind, Samy Bengio, and Preetum Nakkiran. What algorithms can transformers learn? a study in length generalization. arXiv preprint arXiv:2310.16028,
-
[57]
19 D.2 Probing: Model tracks distance to the end node
16 Published as a conference paper at ICLR 2026 Appendix Contents A Limitations 18 B LLM usage 18 C Related works 18 D Additional results 19 D.1 Implementation and licensing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 D.2 Probing: Model tracks distance to the end node . . . . . . . . . . . . . . . . . . . 19 D.3 Pretraining does not interf...
2026
-
[58]
In language, how- ever, understanding remains fragmented: studies have pointed to a variety of factors (e.g., from model-side (Kazemnejad et al., 2023; Petty et al.,
and theoretically (Wiedemer et al., 2023b;a). In language, how- ever, understanding remains fragmented: studies have pointed to a variety of factors (e.g., from model-side (Kazemnejad et al., 2023; Petty et al.,
2023
-
[59]
map semantics
to data-side (Ahuja & Mansouri, 2024; Chang et al., 2025)), but lacking an integrated account. Our work takes a data-centric perspective, unifying the recurring factors into a coherent view of how they jointly shape the model’s systematic extrapolation. Inspired by progress in vision, where disentangled primitives and rules have enabled clearer advances, ...
2024
-
[60]
shows minimal variation. These statistics confirm that increasing coverage does not introduce systematic changes to the length distribution, ensuring that our analyses isolate the effect of coverage itself rather than incidental differences in distance exposure. D.5 EXTENDED ANALYSIS OF COVERAGE AND DIVERSITY If more distinct questions are more valuable,w...
2018
-
[61]
Evenc = 0.8corresponds only to a tiny fraction of the universe of possible primitives
Remark.We stress that coverage is definedonly locally relative to the training map, not the global universe. Evenc = 0.8corresponds only to a tiny fraction of the universe of possible primitives. Since the model is expected (and observed) to spatially transfer to (infinitely) many disjoint maps ˆG= ( ˆV , ˆA), including nodes from all such maps in the den...
2026
-
[62]
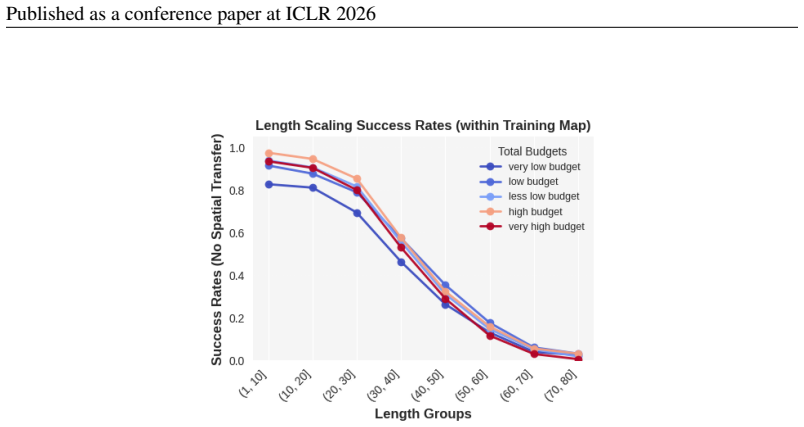
We control the total number of question–answer records to remain fixed across conditions. We use the same evaluation protocol as before, with one training mapGand three independent and disjoint maps ˆG, and report the average performance (measured by the success rate) over the three test maps. D.5.1 MARGINAL EFFECTS We draw two key observations from Figur...
2026
-
[63]
This achieves strong performance at a much lower computational cost than maximizing both dimensions
is to target mid-to-high coverage (≥32%) with modest diversity (8–32). This achieves strong performance at a much lower computational cost than maximizing both dimensions. Beyond this regime, both coverage and diversity show di- minishing returns. Note that dataset size is approximately controlled across conditions by varying the number of answers, which ...
2026
-
[64]
These programs provide a direct way to extract the primitives within questions
for evaluation because: (1) it con- tains six well-separated conceptual categories (gain, geometry, probability, physics, general, other), spanning a range of difficulties and posing greater challenges to commonly used 7B models than simpler math benchmarks such as GSM8K (Qwen et al., 2025); and (2) critically, it provideslin- earized operation programs. ...
2025
-
[65]
add”, “multiply
across three representative difficulty categories in MathQA:probability(easy),gain(medium), andphysics(hard). For each category, we fix a tight training budget of roughly20%of its available samples (approximately1,000examples), except for theprobabilitysplit, which uses50%due to its extremely small size. All models are evaluated on the test set correspond...
2026
-
[66]
29 Published as a conference paper at ICLR 2026 Figure 17: Representative failure cases (SFT) for the (10,
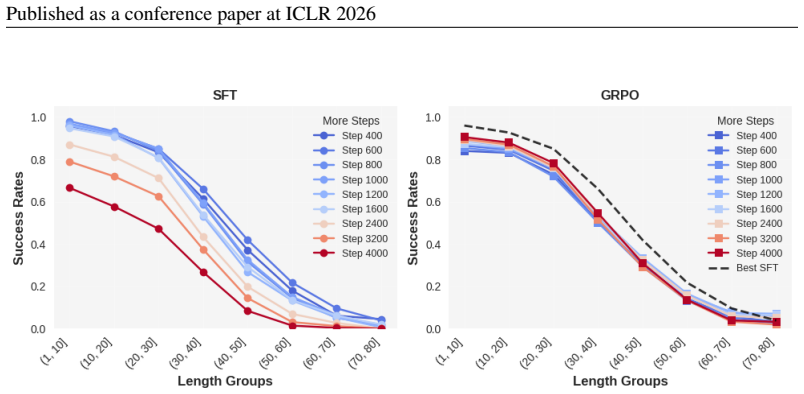
These qualitative findings show that SFT and GRPO exhibit nearly identical failure modes, rein- forcing our conclusion that GRPO stabilizes training but does not surpass the performance ceiling established by the best SFT model. 29 Published as a conference paper at ICLR 2026 Figure 17: Representative failure cases (SFT) for the (10,
2026
-
[67]
30 Published as a conference paper at ICLR 2026 Figure 18: Representative failure cases (GRPO) for the (10,
length group. 30 Published as a conference paper at ICLR 2026 Figure 18: Representative failure cases (GRPO) for the (10,
2026
-
[68]
31 Published as a conference paper at ICLR 2026 Figure 19: Representative failure cases (SFT) for the (40,
length group. 31 Published as a conference paper at ICLR 2026 Figure 19: Representative failure cases (SFT) for the (40,
2026
-
[69]
32 Published as a conference paper at ICLR 2026 Figure 20: Representative failure cases (GRPO) for the (40,
length group. 32 Published as a conference paper at ICLR 2026 Figure 20: Representative failure cases (GRPO) for the (40,
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.