Recognition: no theorem link
Aletheia: Gradient-Guided Layer Selection for Efficient LoRA Fine-Tuning Across Architectures
Pith reviewed 2026-05-13 18:31 UTC · model grok-4.3
The pith
A gradient probe ranks transformer layers by task relevance so LoRA adapters can be applied only to the top-ranked ones, delivering 15-28 percent faster fine-tuning with nearly unchanged benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
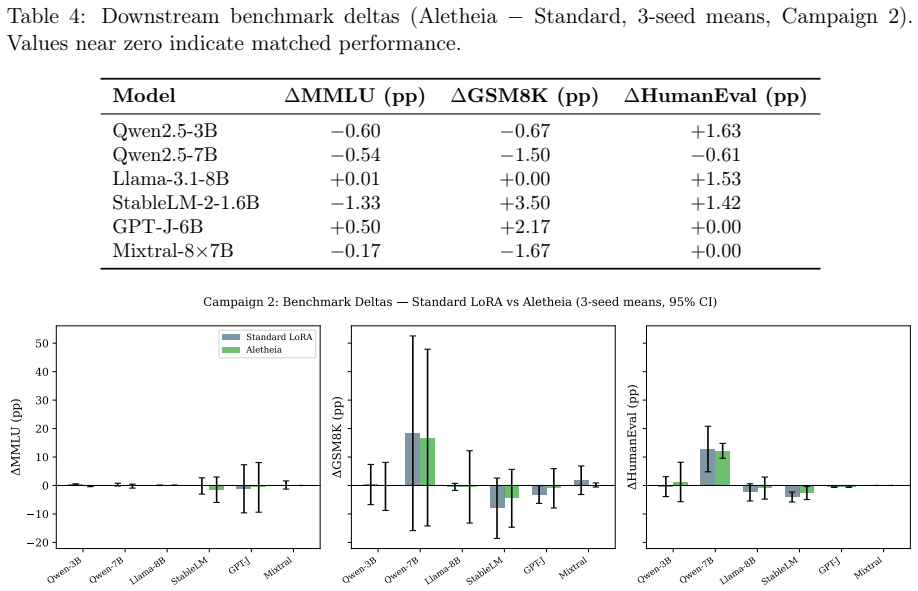
Aletheia uses a lightweight gradient probe to identify the most task-relevant layers and applies LoRA adapters only to those layers with asymmetric rank allocation. Across the tested models this selective placement produces a 15-28 percent training speedup (mean 23.1 percent, p < 0.001) while downstream behavior on the evaluated benchmarks remains broadly matched and extra forgetting stays bounded.
What carries the argument
The gradient probe that computes per-layer importance scores from a short forward-backward pass to select a subset of layers for asymmetric-rank LoRA adaptation.
If this is right
- Training time falls by a mean of 23.1 percent with p less than 0.001.
- Downstream scores on MMLU, GSM8K, and HumanEval remain broadly matched with only bounded extra forgetting.
- The speed gain appears across dense and Mixture-of-Experts models from 0.5B to 72B parameters.
- Campaign 1 records a 100 percent per-model speed win rate.
Where Pith is reading between the lines
- Layer relevance for adaptation is task-dependent rather than uniform, so blanket application wastes resources on most models.
- The same selection logic could be tested on other parameter-efficient methods such as prefix tuning or adapter modules.
- Dynamic re-ranking of layers during a long training run might further improve the speed-accuracy trade-off.
Load-bearing premise
The gradient probe must accurately identify which layers matter for the downstream task so that skipping the rest does not degrade generalization.
What would settle it
A new task where full-layer LoRA clearly outperforms the gradient-selected subset on the same benchmarks, or where re-adding the omitted layers restores a measurable gap, would falsify the efficiency-without-damage claim.
Figures




read the original abstract
Low-Rank Adaptation (LoRA) has become the dominant parameter-efficient fine-tuning method for large language models, yet standard practice applies LoRA adapters uniformly to all transformer layers regardless of their relevance to the downstream task. We introduce Aletheia, a gradient-guided layer selection method that identifies the most task-relevant layers via a lightweight gradient probe and applies LoRA adapters only to those layers with asymmetric rank allocation. Across 81 experiment rows covering 14 successful models from 8 architecture families (0.5B-72B parameters, including dense and Mixture-of-Experts architectures), with one additional documented failed Pythia/GPT-NeoX attempt in Campaign 2, Aletheia achieves a 15-28% training speedup (mean 23.1%, p < 0.001) with bounded extra forgetting and broadly matched downstream behavior on the evaluated MMLU, GSM8K, and HumanEval benchmark pack. Across the tested families and scales, Campaign 1 shows a 100% per-model speed win rate and Campaign 2 shows broadly preserved downstream behavior within a bounded-degradation framing. Together these results support a practical model-economics claim: intelligent layer selection can make LoRA fine-tuning materially more efficient without introducing major downstream damage on the evaluated set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Aletheia, a gradient-guided layer selection technique for efficient LoRA fine-tuning of large language models. It claims that by using a lightweight gradient probe to identify task-relevant layers and applying LoRA only to those with asymmetric rank allocation, it achieves 15-28% training speedups (mean 23.1%, p<0.001) with bounded extra forgetting and matched performance on MMLU, GSM8K, and HumanEval across 81 experiments on 14 models spanning 8 architecture families from 0.5B to 72B parameters.
Significance. If the results hold, the work provides empirical evidence that selective application of LoRA can materially improve fine-tuning efficiency without substantial downstream costs, supported by broad testing across scales and architectures including dense and MoE models. The scale of experiments (81 rows with statistical tests) strengthens the practical model-economics claim.
major comments (2)
- [Experiments] Experiments (Campaign 1/2, 81 rows): no ablation compares gradient-guided selection to random selection of the same number of layers (or to bottom-k/middle-k heuristics). Reported 15-28% speedups and matched downstream scores are measured only against uniform full-layer LoRA; without this control it is impossible to isolate whether gains arise from the probe's ranking or simply from reduced adapter count.
- [Method] Method (gradient probe): full implementation details are missing, including exact probe batch size, threshold rule, and computation that avoids selection bias. This directly affects verification of the claim that the probe accurately ranks task-relevant layers without missing critical ones.
minor comments (2)
- [Abstract] Abstract: the parenthetical reference to the single failed Pythia/GPT-NeoX attempt should state its implications for robustness or scope.
- [Method] Notation: 'asymmetric rank allocation' is used without an explicit equation or pseudocode definition; add one for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the suggested changes in the revised version.
read point-by-point responses
-
Referee: Experiments (Campaign 1/2, 81 rows): no ablation compares gradient-guided selection to random selection of the same number of layers (or to bottom-k/middle-k heuristics). Reported 15-28% speedups and matched downstream scores are measured only against uniform full-layer LoRA; without this control it is impossible to isolate whether gains arise from the probe's ranking or simply from reduced adapter count.
Authors: We agree that this control is necessary to isolate the contribution of the gradient probe. The current results show consistent speedups over full-layer LoRA, but they do not yet distinguish gradient-guided selection from simply using fewer adapters. We will add ablations comparing to random selection of the same number of layers as well as bottom-k and middle-k heuristics, including updated tables, statistical tests, and discussion in the revised manuscript. revision: yes
-
Referee: [Method] Method (gradient probe): full implementation details are missing, including exact probe batch size, threshold rule, and computation that avoids selection bias. This directly affects verification of the claim that the probe accurately ranks task-relevant layers without missing critical ones.
Authors: We acknowledge the omission of these details. In the revised manuscript we will expand the method section to specify the probe batch size (32), the exact threshold rule (select layers whose gradient norm exceeds the median across layers), and the use of a held-out probe batch to compute gradients before any fine-tuning begins, thereby avoiding selection bias. We will also add pseudocode for the full layer-selection procedure. revision: yes
Circularity Check
Empirical gradient-probe procedure tested on external benchmarks; no derivation reduces to fitted parameters or self-citation chains by construction.
full rationale
The paper defines Aletheia as a concrete experimental workflow: compute a lightweight gradient probe on a small calibration set, rank layers by a relevance metric, allocate LoRA adapters asymmetrically to the selected subset, and measure wall-clock speedup plus downstream scores on MMLU/GSM8K/HumanEval. All reported gains (15-28% mean 23.1%) are obtained by direct comparison to uniform full-layer LoRA on the same models and tasks. No equations are given that would make the final accuracy or runtime a mathematical identity of the probe output; the selection rule is an external heuristic whose utility is assessed against held-out benchmarks rather than being presupposed. No self-citations appear as load-bearing premises, and the method contains no fitted parameters that are later renamed as predictions. The derivation is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (2)
- gradient probe batch size and threshold
- asymmetric rank allocation rule
axioms (1)
- domain assumption Gradient norms from a lightweight probe correlate with task-specific layer importance
Forward citations
Cited by 1 Pith paper
-
Gradient-Based LoRA Rank Allocation Under GRPO: An Empirical Study
Gradient-based proportional LoRA rank allocation under GRPO reduces accuracy by 4.5 points versus uniform allocation because GRPO gradients are flatter across layers and non-uniform ranks amplify importance differences.
Reference graph
Works this paper leans on
-
[1]
Chen, M., Tworek, J., Jun, H., et al. (2021). Evaluating large language models trained on code. arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Cobbe, K., Kosaraju, V., Bavarian, M., et al. (2021). Training verifiers to solve math word problems. arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. NeurIPS 2023. arXiv:2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
-
[5]
Hendrycks, D., Burns, C., Basart, S., et al. (2021). Measuring massive multitask language understanding. ICLR 2021. arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Hu, E.J., Shen, Y., Wallis, P., et al. (2022). LoRA: Low-rank adaptation of large language models. ICLR 2022. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [7]
- [8]
-
[9]
Zhang, Q., Chen, M., Bukharin, A., et al. (2023). AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning. ICLR 2023. arXiv:2303.10512
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.