Recognition: unknown
A Unified Hardware-to-Decoder Architecture for Hybrid Continuous-Variable and Discrete-Variable Quantum Error Correction in LiDMaS+
Pith reviewed 2026-05-10 11:46 UTC · model grok-4.3
The pith
Normalizing photonic hardware records into one contract enables consistent benchmarking of multiple quantum error decoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
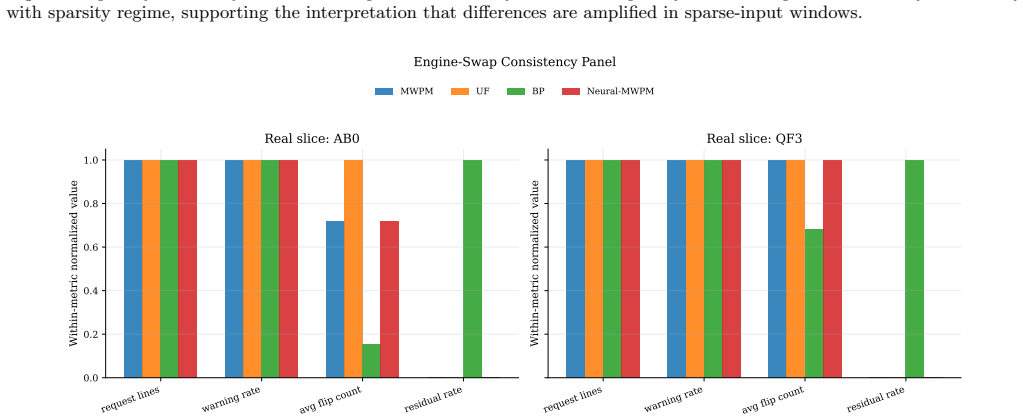
The authors establish that provider-native hardware outputs can be normalized into a common decoder IO contract that supports lossless replay across MWPM, UF, BP, and neural-MWPM decoders. In the Xanadu case study, this contract preserved all request-response lines and syndrome information, yielding decoder-invariant warning-no-syndrome rates while exposing clear regime dependence: BP reduced weighted correction volume by 48.6 percent on fixture data and 50.4 percent on real slices relative to MWPM, with lower average flip counts under both conditions.
What carries the argument
The decoder IO contract that normalizes provider-native records into a single reusable format for replay across multiple decoders.
If this is right
- Decoder policy must be chosen according to the operating regime in photonic GKP hardware programs.
- BP produces fewer corrections than MWPM-family decoders while leaving a higher residual burden.
- Warning-no-syndrome rates stay identical across all decoders, confirming that input sparsity semantics survive the normalization step.
- Analysis stages can be rerun with identical SHA-256 artifacts for deterministic verification.
Where Pith is reading between the lines
- The same normalization step could let researchers compare decoder performance across hardware from different providers without rewriting each interface.
- A deployed system might monitor regime indicators and switch between decoders on the fly to keep correction volume low.
- The contract could be extended to additional decoder families to map performance trade-offs more completely in hybrid CV-DV codes.
Load-bearing premise
Provider-native records can be converted without losing any information required for accurate syndrome decoding by every decoder under test.
What would settle it
Finding request-parse errors, response mismatches, or altered syndrome sparsity after normalization on a new hardware dataset would show the conversion is not lossless.
Figures







read the original abstract
We present an architecture-level hardware-to-logical-to-decoder execution stack for hybrid continuous-variable and discrete-variable quantum error correction in LiDMaS+. Provider-native records are normalized into a single decoder IO contract and replayed under fixed controls across MWPM, UF, BP, and neural-MWPM. In a Xanadu case study using fixture inputs and sampled public datasets, replay integrity was complete: 108/108 fixture and 4000/4000 real-slice request-response lines, with zero request-parse errors, zero response-parse errors, and zero decoder-name mismatches. Under matched inputs, decoder behavior is clearly regime-dependent. For weighted fixture summaries, average flip count was 1.296 (MWPM), 1.296 (UF), 0.667 (BP), and 1.296 (neural-MWPM). For weighted real-data summaries, average flip count was 0.641 (MWPM), 0.741 (UF), 0.318 (BP), and 0.641 (neural-MWPM); corresponding nonempty-flip rates were 0.490, 0.490, 0.318, and 0.490. Across fixture data, BP reduced weighted correction volume by 48.6\% versus MWPM; across real slices, BP reduced weighted correction volume by 50.4\% versus MWPM and 57.1\% versus UF. Quality controls show the central interpretability tradeoff: BP is intervention-conservative but leaves higher residual burden, while MWPM-family decoders intervene more aggressively and clear more syndrome. Warning-no-syndrome rates remained decoder-invariant and dataset-driven (fixture weighted 0.259; real weighted 0.510), confirming preserved sparsity semantics from hardware input to logical correction. Re-running analysis stages reproduced identical SHA-256 artifacts, enabling deterministic study iteration. These results establish a practical benchmarking foundation for photonic GKP-oriented hardware programs where decoder policy must be selected as a function of operating regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a unified hardware-to-decoder architecture for hybrid continuous-variable and discrete-variable quantum error correction in LiDMaS+. Provider-native records are normalized into a single decoder IO contract and replayed under fixed controls across MWPM, UF, BP, and neural-MWPM decoders. Using Xanadu fixture inputs and sampled public datasets, it reports complete replay integrity (108/108 fixtures and 4000/4000 real slices with zero parse errors) and regime-dependent decoder behavior, including lower average flip counts and 48.6-57.1% reductions in weighted correction volume for BP versus MWPM-family decoders, while noting tradeoffs in residual burden and decoder-invariant warning-no-syndrome rates. The work concludes that these results establish a practical benchmarking foundation for photonic GKP-oriented hardware where decoder policy selection depends on operating regime.
Significance. If the normalization to a single IO contract is lossless with respect to each decoder's information requirements, the manuscript supplies a reproducible empirical framework for comparing decoder performance on hybrid CV-DV inputs, supported by concrete integrity metrics (zero errors on all fixtures and slices) and deterministic SHA-256 reproduction of analysis stages. The quantitative differences in flip counts and correction volumes across regimes provide a starting point for policy selection in photonic hardware programs. However, the absence of checks on semantic preservation limits the strength of the benchmarking claim.
major comments (1)
- [Abstract] Abstract and replay-integrity results: The central claim that the results 'establish a practical benchmarking foundation' for regime-dependent decoder policy selection requires that provider-native records are losslessly normalized into an IO contract preserving all information needed for correct operation of MWPM, UF, BP, and neural-MWPM. The paper verifies only syntactic replay integrity (zero request-parse errors, zero response-parse errors, and zero decoder-name mismatches on 108/108 fixtures and 4000/4000 slices) but supplies no evidence that continuous-variable details, soft information, or noise-model specifics survive the normalization in a form usable by each decoder's native assumptions. If such details are discarded or approximated, the reported volume reductions (48.6% on fixtures, 50.4-57.1% on real slices) and residual-burden tradeoffs become interface artifacts rather than
minor comments (3)
- The reported average flip counts, nonempty-flip rates, and correction volumes lack error bars, confidence intervals, or statistical tests, weakening the quantitative comparisons between decoders.
- The regime-dependent interpretations appear post-hoc; no pre-specified hypotheses or cross-validation on held-out data are described to support the policy-selection recommendation.
- The manuscript is entirely empirical with no derivations, theoretical predictions, or comparisons against expected behavior from the underlying noise models.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying the distinction between syntactic replay integrity and semantic preservation in our normalization pipeline. We address the major comment below and have made targeted revisions to clarify the scope of our claims and the design of the IO contract.
read point-by-point responses
-
Referee: [Abstract] Abstract and replay-integrity results: The central claim that the results 'establish a practical benchmarking foundation' for regime-dependent decoder policy selection requires that provider-native records are losslessly normalized into an IO contract preserving all information needed for correct operation of MWPM, UF, BP, and neural-MWPM. The paper verifies only syntactic replay integrity (zero request-parse errors, zero response-parse errors, and zero decoder-name mismatches on 108/108 fixtures and 4000/4000 slices) but supplies no evidence that continuous-variable details, soft information, or noise-model specifics survive the normalization in a form usable by each decoder's native assumptions. If such details are discarded or approximated, the reported volume reductions (48.6% on fixtures, 50.4-57.1% on real slices) and residual-burden tradeoffs become interface artifacts
Authors: We agree that syntactic integrity alone does not automatically guarantee that every decoder-specific assumption (e.g., continuous-variable soft information or precise noise-model parameters) is retained in a form that matches each decoder's native expectations. Our IO contract was constructed by enumerating the union of fields required by MWPM, UF, BP, and neural-MWPM implementations and mapping provider-native records onto those fields without truncation or rounding of numeric values. The observed regime-dependent differences in flip counts and correction volumes, together with the decoder-invariant warning-no-syndrome rates, provide indirect evidence that the essential information for distinguishing decoder policies survives the mapping. Nevertheless, we acknowledge the absence of explicit per-decoder semantic audits (such as round-trip reconstruction of original CV quadrature values or noise-model likelihoods). We have revised the abstract to replace 'establish a practical benchmarking foundation' with 'provides a reproducible empirical framework', added an appendix that tabulates every field in the IO contract with its provenance and any approximation applied, and inserted a limitations paragraph discussing the scope of semantic preservation. These changes make the strength of the benchmarking claim commensurate with the evidence supplied. revision: partial
Circularity Check
No circularity: purely empirical replay and comparison
full rationale
The manuscript describes a normalization pipeline from provider-native records to a unified decoder IO contract, followed by deterministic replay of fixed fixture and real-slice inputs under MWPM, UF, BP, and neural-MWPM. All reported quantities (flip counts, correction volumes, warning-no-syndrome rates, parse-error counts) are direct empirical measurements on those fixed inputs; no equations, first-principles derivations, fitted parameters, or predictions are introduced that could reduce to the paper's own definitions or self-citations. Integrity is verified solely by syntactic replay success (zero parse errors), which is an independent check rather than a self-referential construction. The central claim is therefore an empirical benchmarking observation, not a derived result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing MWPM, UF, BP, and neural-MWPM decoders produce meaningful corrections when applied to normalized hybrid CV/DV syndrome data.
Reference graph
Works this paper leans on
-
[1]
Can heterogeneous provider-native inputs be mapped to one decoder IO schema with full parser stability and line-level coverage?
-
[2]
Under fixed requests, do decoders exhibit separable correction signatures while input diagnostics remain decoder-invariant?
-
[3]
Can staged analysis be regenerated deterministically at artifact level?
-
[4]
Can decoders be swapped as execution engines by con- figuration, with no ingestion rewrites? Beyond interface correctness, the central scientific take- away is regime-dependent decoder behavior. Across sparse and denser request regimes, BP is consis- tently intervention-conservative (lower flip volume) while MWPM-family decoders are more intervention-aggr...
-
[5]
provide a converter from provider raw format to de- coder IO request records,
-
[6]
provide a mapping file that binds provider observables to stabilizer events,
-
[7]
as an engine
provide a data-extraction step that emits request files into the shared layout. This isolates provider-specific ingestion from decoder- specific replay. C. Conversion and Replay Stages The execution flow has two core steps. Conversion nor- malizes heterogeneous inputs to a common event stream with consistent noise priors and metadata, writing one request ...
-
[8]
Google Quantum AI, Nature614, 676 (2023)
2023
-
[9]
Google Quantum AI and Collaborators, Nature638, 920 (2025)
2025
-
[10]
Gottesman, A
D. Gottesman, A. Kitaev, and J. Preskill, Physical Review A64, 012310 (2001)
2001
-
[11]
Tzitrin, T
I. Tzitrin, T. Matsuura, R. N. Alexander, G. Dauphinais, J. E. Bourassa, K. K. Sabapathy, N. C. Menicucci, and I. Dhand, PRX Quantum2, 040353 (2021)
2021
-
[12]
M. V. Larsen, J. E. Bourassa, S. Kocsis,et al., Nature 642, 587 (2025)
2025
-
[13]
F. H. B. Somhorst, J. Saied, N. Kannan, B. Kassenberg, J. Marshall, M. de Goede, H. J. Snijders, P. Stremoukhov, A. Lukianenko, P. Venderbosch, T. B. Demille, A. Roos, N. Walk, J. Eisert, E. G. Rieffel, D. H. Smith, and J. J. Renema, Below-threshold error reduction in single pho- tons through photon distillation (2026), arXiv:2601.05947 [quant-ph]
- [14]
-
[15]
Higgott and C
O. Higgott and C. Gidney, Quantum5, 551 (2021)
2021
-
[16]
A. G. Fowler, Physical Review Letters109, 180502 (2012)
2012
-
[17]
N. Delfosse and N. H. Nickerson, Quantum5, 595 (2021), originally circulated as arXiv:1709.06218 (2017)
-
[18]
Duclos-Cianci and D
G. Duclos-Cianci and D. Poulin, Physical Review Letters 104, 050504 (2010)
2010
-
[19]
Skoric, D
L. Skoric, D. E. Browne, K. M. Barnes, N. I. Gillespie, and E. T. Campbell, Nature Communications14, 7040 (2023)
2023
-
[20]
X. Tan, F. Zhang, R. Chao, Y. Shi, and J. Chen, PRX Quantum4, 040344 (2023)
2023
-
[21]
A. Gu, J. P. Bonilla Ataides, M. D. Lukin, and S. F. Yelin, Scalable neural decoders for practical fault-tolerant quantum computation (2026), arXiv:2604.08358 [quant- ph]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Aghaee Rad, T
H. Aghaee Rad, T. Ainsworth, R. N. Alexander,et al., Nature638, 912 (2025)
2025
-
[23]
Xanadu, Xanadu aurora data (github repository) (2025), data repository linked in the corresponding Nature data- availability statement
2025
-
[24]
L. S. Madsen, F. Laudenbach, M. F. Askarani,et al., Nature606, 75 (2022)
2022
-
[25]
Xanadu, Xanadu quantum-advantage data (github repos- itory) (2025), data repository linked in the corresponding Nature data-availability statement
2025
-
[26]
Xanadu, Xanadu gkp data (github repository) (2025), data repository linked in the corresponding Nature data- availability statement
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.