Recognition: no theorem link
Scalable Neural Decoders for Practical Fault-Tolerant Quantum Computation
Pith reviewed 2026-05-10 18:08 UTC · model grok-4.3
The pith
A convolutional neural network decoder for quantum error correction achieves logical error rates up to 17 times lower than existing methods while delivering orders of magnitude higher speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
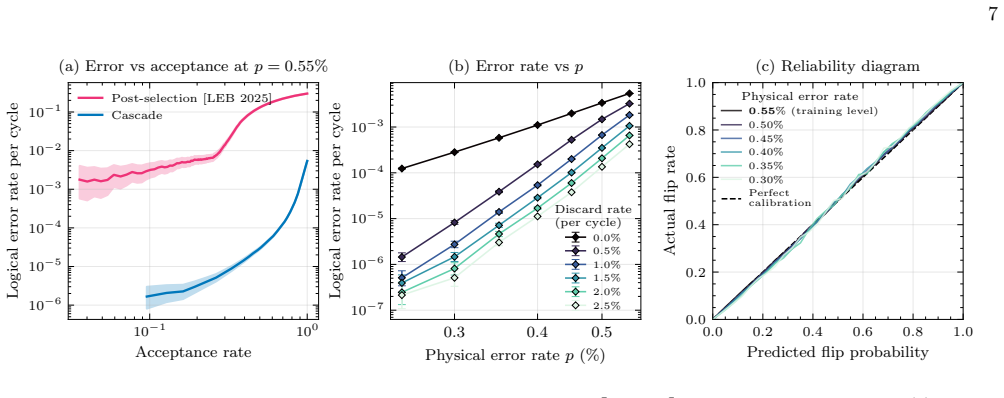
A convolutional neural network decoder exploiting the geometric structure of QEC codes probes a novel waterfall regime of error suppression. For the [144, 12, 12] Gross code, it achieves logical error rates up to ~17x below existing decoders, reaching ~10^{-10} at physical error p=0.1%, with 3-5 orders of magnitude higher throughput, and produces well-calibrated confidence estimates that can reduce overhead in repeat-until-success protocols.
What carries the argument
Convolutional neural network decoder that exploits the geometric structure of quantum error correction codes to enable fast, accurate decoding in a waterfall error suppression regime.
Load-bearing premise
The neural network trained on idealized simulated error models will maintain its performance when deployed on real quantum hardware amid device-specific noise and imperfections.
What would settle it
Measuring logical error rates on actual quantum hardware for the Gross code that fail to reach around 10^{-10} at 0.1% physical error or show throughput insufficient for real-time decoding.
Figures




read the original abstract
Quantum error correction (QEC) is essential for scalable quantum computing. However, it requires classical decoders that are fast and accurate enough to keep pace with quantum hardware. While quantum low-density parity-check codes have recently emerged as a promising route to efficient fault tolerance, current decoding algorithms do not allow one to realize the full potential of these codes in practical settings. Here, we introduce a convolutional neural network decoder that exploits the geometric structure of QEC codes, and use it to probe a novel "waterfall" regime of error suppression, demonstrating that the logical error rates required for large-scale fault-tolerant algorithms are attainable with modest code sizes at current physical error rates, and with latencies within the real-time budgets of several leading hardware platforms. For example, for the $[144, 12, 12]$ Gross code, the decoder achieves logical error rates up to $\sim 17$x below existing decoders - reaching logical error rates $\sim 10^{-10}$ at physical error $p=0.1\%$ - with 3-5 orders of magnitude higher throughput. This decoder also produces well-calibrated confidence estimates that can significantly reduce the time overhead of repeat-until-success protocols. Taken together, these results suggest that the space-time costs associated with fault-tolerant quantum computation may be significantly lower than previously anticipated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a convolutional neural network (CNN) decoder that exploits the geometric structure of quantum low-density parity-check codes. For the [144,12,12] Gross code, it reports logical error rates up to ~17x lower than existing decoders, reaching ~10^{-10} at physical error rate p=0.1%, with 3-5 orders of magnitude higher throughput and well-calibrated confidence estimates suitable for repeat-until-success protocols. The central claim is that this enables practical fault-tolerant quantum computation at modest code sizes and current physical error rates with real-time latencies.
Significance. If the performance numbers and scaling hold under realistic conditions, the work would demonstrate that neural decoders can substantially reduce the space-time overhead of fault-tolerant quantum computing by achieving target logical error rates with smaller codes and higher speed than conventional decoders. The explicit use of geometric structure in the CNN architecture and the production of calibrated confidence scores are notable strengths that could be broadly applicable.
major comments (3)
- [Results (Gross code performance)] Results section (around the [144,12,12] Gross code performance figures): The headline logical error rate of ~10^{-10} at p=0.1% is stated without direct Monte Carlo evidence. At this physical error rate, reliable statistics require >10^{11} shots, which is infeasible; the value must derive from fitting curves obtained at p ≳ 0.5%. The manuscript must specify the exact fitting model (e.g., power-law exponent), the p-range used, goodness-of-fit metrics, and tests for error floors or training-distribution mismatch. Without this, both the absolute rate and the ~17x improvement factor rest on an unverified extrapolation assumption.
- [Methods] Methods section (training and data generation): The description of training-data generation, error-model details, validation splits, and hyperparameter choices is insufficient to reproduce or assess robustness. Because the central performance claims are empirical, the absence of these specifics (including how the network was exposed to low-p regimes during training) makes it impossible to evaluate whether the reported scaling is an artifact of the simulation setup.
- [Implementation and latency analysis] Latency and hardware claims: Assertions that the decoder meets real-time budgets of leading hardware platforms rely on idealized latency measurements. The manuscript should provide concrete end-to-end timing benchmarks that incorporate device-specific effects (e.g., measurement latency, classical control overhead) rather than simulation-only figures, as these directly support the practicality claim.
minor comments (2)
- [Figures] Figure captions and axis labels in the performance plots should explicitly state the number of Monte Carlo shots per data point and whether error bars are shown or omitted.
- [Introduction] The abstract and introduction cite prior neural decoders only in passing; a short dedicated paragraph comparing architectural choices and performance baselines would improve context.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and support for our claims where possible.
read point-by-point responses
-
Referee: Results section (around the [144,12,12] Gross code performance figures): The headline logical error rate of ~10^{-10} at p=0.1% is stated without direct Monte Carlo evidence. At this physical error rate, reliable statistics require >10^{11} shots, which is infeasible; the value must derive from fitting curves obtained at p ≳ 0.5%. The manuscript must specify the exact fitting model (e.g., power-law exponent), the p-range used, goodness-of-fit metrics, and tests for error floors or training-distribution mismatch. Without this, both the absolute rate and the ~17x improvement factor rest on an unverified extrapolation assumption.
Authors: We agree that direct Monte Carlo sampling at p=0.1% is infeasible and that the reported rate is extrapolated from higher-p simulations. In the revised manuscript we will explicitly document the fitting procedure: the power-law model and its exponent, the precise p-range used for fitting (0.5%–2%), goodness-of-fit metrics (R^{2} and residual analysis), and checks for error floors or training-distribution mismatch performed by comparing extrapolated predictions against additional low-p validation runs where feasible. The ~17x improvement factor is computed directly at physical error rates where both decoders have sufficient statistics; the extrapolated values preserve the same relative ordering. revision: yes
-
Referee: Methods section (training and data generation): The description of training-data generation, error-model details, validation splits, and hyperparameter choices is insufficient to reproduce or assess robustness. Because the central performance claims are empirical, the absence of these specifics (including how the network was exposed to low-p regimes during training) makes it impossible to evaluate whether the reported scaling is an artifact of the simulation setup.
Authors: We acknowledge the current methods section is too terse for full reproducibility. The revised manuscript will expand this section with: the exact error model (depolarizing noise with per-qubit and per-measurement rates), number of training samples generated at each physical error rate, the train/validation/test splits, all hyperparameter values (network depth, filter sizes, learning rate schedule, batch size, epochs), and a description of how low-p regimes were included in training data to ensure the network learns the correct scaling. These additions will allow independent assessment of robustness. revision: yes
-
Referee: Latency and hardware claims: Assertions that the decoder meets real-time budgets of leading hardware platforms rely on idealized latency measurements. The manuscript should provide concrete end-to-end timing benchmarks that incorporate device-specific effects (e.g., measurement latency, classical control overhead) rather than simulation-only figures, as these directly support the practicality claim.
Authors: The reported latencies are obtained from optimized GPU inference simulations. We agree that device-specific effects should be addressed. In revision we will add estimates that fold in typical measurement latencies and classical control overheads drawn from the literature on leading superconducting and trapped-ion platforms, together with a discussion of how these affect the overall real-time budget. Full end-to-end hardware benchmarks on a specific quantum device lie outside the scope of the present theoretical work; we will therefore clarify the modeling assumptions and note the idealized nature of the core inference timing. revision: partial
Circularity Check
No circularity; results are empirical ML evaluations on simulated data
full rationale
The paper introduces a CNN decoder for QEC codes and reports its performance via training on Monte Carlo-generated error syndromes followed by direct evaluation of logical error rates and throughput on test data. No derivation chain is present that reduces a claimed result to its own inputs by construction, self-definition, or load-bearing self-citation. The reported logical error rates (including the ~10^{-10} figure at p=0.1%) are presented as outcomes of the trained model rather than analytic predictions forced by fitted parameters or prior self-work. Standard CNN design choices are justified by code geometry without circular reduction, and comparisons to existing decoders are independent empirical benchmarks. The paper is self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- CNN weights and biases
- Training hyperparameters (learning rate, batch size, epochs)
axioms (2)
- domain assumption Standard depolarizing noise model accurately represents hardware errors for the purpose of decoder benchmarking.
- domain assumption The geometric structure of the code can be faithfully represented as input channels to a convolutional network.
Forward citations
Cited by 3 Pith papers
-
High-fidelity entangling gates and nonlocal circuits with neutral atoms
Neutral-atom system delivers state-of-the-art CZ gate fidelity of 99.854% (99.941% postselected) and demonstrates coherent rearrangement for nonlocal quantum circuits.
-
Towards Ultra-High-Rate Quantum Error Correction with Reconfigurable Atom Arrays
A family of quantum LDPC codes with encoding rates exceeding 1/2 achieves logical error rates of 10^{-13} per round on atom arrays under 0.1% circuit noise using hierarchical decoding.
-
A Unified Hardware-to-Decoder Architecture for Hybrid Continuous-Variable and Discrete-Variable Quantum Error Correction in LiDMaS+
A benchmarking framework for hybrid quantum error correction shows belief propagation reduces weighted correction volume by 48-57% compared to MWPM-family decoders while preserving input sparsity.
Reference graph
Works this paper leans on
-
[1]
& Zemor, G
Leverrier, A. & Zemor, G. Quantum Tanner codes. In 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), 872–883 (IEEE, 2022)
2022
-
[2]
& Kalachev, G
Panteleev, P. & Kalachev, G. Quantum ldpc codes with almost linear minimum distance.IEEE Transactions on Information Theory68, 213–229 (2022)
2022
-
[3]
Bravyi, S.et al.High-threshold and low-overhead fault- tolerant quantum memory.Nature627, 778–782 (2024)
2024
-
[4]
& Chung, Y
Poulin, D. & Chung, Y. On the iterative decoding of sparse quantum codes.Quantum Information and Com- putation8, 986–1000 (2008)
2008
-
[5]
R., Burton, S
Roffe, J., White, D. R., Burton, S. & Campbell, E. De- coding across the quantum low-density parity-check code landscape.Physical Review Research2, 043423 (2020)
2020
-
[6]
Tesseract: A Search-Based Decoder for Quantum Error Correction,
Beni, L. A., Higgott, O. & Shutty, N. Tesseract: A search-based decoder for quantum error correction. Preprint at https://arxiv.org/abs/2503.10988 (2025)
-
[7]
& Eker˚ a, M
Gidney, C. & Eker˚ a, M. How to factor 2048 bit RSA in- tegers in 8 hours using 20 million noisy qubits.Quantum 5, 433 (2021)
2048
-
[8]
Assessing requirements to scale to practical quantum advantage
Beverland, M. E.et al.Assessing requirements to scale to practical quantum advantage. Preprint at https://arxiv.org/abs/2211.07629 (2022)
work page internal anchor Pith review arXiv 2022
-
[9]
J., Harty, T
Ballance, C. J., Harty, T. P., Linke, N. M., Sepiol, M. A. & Lucas, D. M. High-fidelity quantum logic gates using trapped-ion hyperfine qubits.Physical Review Letters 117, 060504 (2016)
2016
-
[10]
Li, R.et al.Realization of high-fidelity cz gate based on a double-transmon coupler.Physical Review X14, 041050 (2024)
2024
-
[11]
J.et al.High-fidelity entangling gates and nonlocal circuits with neutral atoms.In preparation (2025)
Evered, S. J.et al.High-fidelity entangling gates and nonlocal circuits with neutral atoms.In preparation (2025)
2025
-
[12]
M¨ uller, T.et al.Improved belief propagation is sufficient for real-time decoding of quantum memory. Preprint at https://arxiv.org/abs/2506.01779 (2025)
-
[13]
T., Terhal, B
Campbell, E. T., Terhal, B. M. & Vuillot, C. Roads towards fault-tolerant universal quantum computation. Nature549, 172–179 (2017)
2017
-
[14]
C., Brown, B
Smith, S. C., Brown, B. J. & Bartlett, S. D. Mitigat- ing errors in logical qubits.Communications Physics7 (2024)
2024
-
[15]
Blue, J., Avlani, H., He, Z., Ziyin, L. & Chuang, I. L. Machine learning decoding of circuit-level noise for bivariate bicycle codes. Preprint at https://arxiv.org/abs/2504.13043 (2025)
-
[16]
Feynman, R. P. Simulating physics with computers.In- ternational Journal of Theoretical Physics21, 467–488 (1982)
1982
-
[17]
Shor, P. W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer.SIAM Journal on Computing26, 1484–1509 (1997)
1997
-
[18]
D., Love, P
Aspuru-Guzik, A., Dutoi, A. D., Love, P. J. & Head- Gordon, M. Simulated quantum computation of molecu- lar energies.Science309, 1704–1707 (2005)
2005
-
[19]
& Ben-Or, M
Aharonov, D. & Ben-Or, M. Fault-Tolerant Quantum Computation with Constant Error Rate.SIAM Journal on Computing38, 1207–1282 (2008)
2008
-
[20]
& Zurek, W
Knill, E., Laflamme, R. & Zurek, W. H. Resilient quan- tum computation: error models and thresholds.Proceed- ings of the Royal Society of London. Series A: Mathe- matical, Physical and Engineering Sciences454, 365–384 (1998)
1998
-
[21]
Exponential suppression of bit or phase errors with cyclic error correction.Nature595, 383–387 (2021)
Google Quantum AI. Exponential suppression of bit or phase errors with cyclic error correction.Nature595, 383–387 (2021)
2021
-
[22]
Quantum error correction below the surface code threshold.Nature638, 920–926 (2025)
Google Quantum AI and Collaborators. Quantum error correction below the surface code threshold.Nature638, 920–926 (2025)
2025
-
[23]
Bluvstein, D.et al.Logical quantum processor based on reconfigurable atom arrays.Nature626, 58–65 (2024)
2024
-
[24]
Bluvstein, D.et al.A fault-tolerant neutral-atom archi- tecture for universal quantum computation.Nature649, 39–46 (2026)
2026
-
[25]
Demonstration of logical qubits and repeated error correction with better-than-physical error rates,
Paetznick, A.et al.Demonstration of logical qubits and repeated error correction with better-than-physical er- ror rates. Preprint at https://arxiv.org/abs/2404.02280 (2024)
-
[26]
G., Mariantoni, M., Martinis, J
Fowler, A. G., Mariantoni, M., Martinis, J. M. & Cle- land, A. N. Surface codes: Towards practical large-scale quantum computation.Physical Review A86, 032324 (2012)
2012
-
[27]
& Martin-Delgado, M
Bombin, H. & Martin-Delgado, M. A. Topological quan- tum distillation.Physical Review Letters97, 180501 (2006)
2006
-
[28]
& Kalachev, G
Panteleev, P. & Kalachev, G. Asymptotically good Quan- tum and locally testable classical LDPC codes. InPro- ceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, 375–388 (ACM, 2022)
2022
-
[29]
& Vasi´ c, B
Raveendran, N. & Vasi´ c, B. Trapping sets of quantum ldpc codes.Quantum5, 562 (2021)
2021
-
[30]
& Kalachev, G
Panteleev, P. & Kalachev, G. Degenerate Quantum LDPC Codes With Good Finite Length Performance. Quantum5, 585 (2021)
2021
-
[31]
Gu, S., Wang, L. & Kubica, A. The color code, the surface code, and the transversal cnot: Np- hardness of minimum-weight decoding (2026). URL https://arxiv.org/abs/2603.22064. Preprint at https://arxiv.org/abs/2603.22064
-
[32]
Low-density parity-check codes.IEEE Transactions on Information Theory8, 21–28 (1962)
Gallager, R. Low-density parity-check codes.IEEE Transactions on Information Theory8, 21–28 (1962)
1962
-
[33]
MacKay, D. J. C. & Neal, R. M. Near Shannon limit per- formance of low density parity check codes.Electronics Letters32, 1645–1646 (1996)
1996
-
[34]
A game of surface codes: Large-scale quan- tum computing with lattice surgery.Quantum3, 128 (2019)
Litinski, D. A game of surface codes: Large-scale quan- tum computing with lattice surgery.Quantum3, 128 (2019)
2019
-
[35]
InProceedings of the 52nd Annual International Sympo- sium on Computer Architecture (SIGARCH ’25), 1432– 1448 (ACM, 2025)
Zhou, H.et al.Resource analysis of low-overhead transversal architectures for reconfigurable atom arrays. InProceedings of the 52nd Annual International Sympo- sium on Computer Architecture (SIGARCH ’25), 1432– 1448 (ACM, 2025)
2025
-
[36]
Richardson, T. J. & Urbanke, R. L. The capacity of low-density parity-check codes under message-passing de- coding.IEEE Transactions on Information Theory47, 599–618 (2001)
2001
-
[37]
Richardson, T. J. & Urbanke, R. L.Modern coding theory 9 (Cambridge University Press, Cambridge, 2009)
2009
-
[38]
Watson, F. H. E. & Barrett, S. D. Logical error rate scaling of the toric code.New Journal of Physics16, 093045 (2014)
2014
-
[39]
& Sakaniwa, K
Kasai, K., Hagiwara, M., Imai, H. & Sakaniwa, K. Quan- tum error correction beyond the bounded distance decod- ing limit.IEEE Transactions on Information Theory58, 1223–1230 (2012)
2012
-
[40]
Komoto, D. & Kasai, K. Quantum error correc- tion near the coding theoretical bound. Preprint at https://arxiv.org/abs/2412.21171 (2025)
-
[41]
Error Mitigation of Fault-Tolerant Quantum Circuits with Soft Information,
Zhou, Z., Pexton, S., Kubica, A. & Ding, Y. Error mit- igation of fault-tolerant quantum circuits with soft in- formation. Preprint at https://arxiv.org/abs/2512.09863 (2025)
-
[42]
Magic tricycles: Efficient magic state generation with finite block-length quantum LDPC codes
Menon, V.et al.Magic tricycles: Efficient magic state generation with finite block-length quantum ldpc codes. Preprint at https://arxiv.org/abs/2508.10714 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Breuckmann, N. P. & Eberhardt, J. N. Quantum low- density parity-check codes.PRX Quantum2(2021)
2021
-
[44]
For all reference decoders, we use BP+OSD with de- faultstimbposdsettings (product-sum BP, 30 iterations, combination-sweep OSD of order 60) [5], Relay with hyperparameters tuned following the authors’ recom- mended procedure [12], and Tesseract in the short-beam configuration [6]
-
[45]
This includes per-invocation overhead amortized across rounds
Reported amortized latencies are computed as total wall- clock time divided by (batch size×syndrome rounds). This includes per-invocation overhead amortized across rounds
-
[46]
Terhal, B. M. Quantum error correction for quantum memories.Reviews of Modern Physics87, 307–346 (2015)
2015
-
[47]
E., Barnes, K
Skoric, L., Browne, D. E., Barnes, K. M., Gillespie, N. I. & Campbell, E. T. Parallel window decoding enables scalable fault tolerant quantum computation.Nature Communications14, 7040 (2023)
2023
-
[48]
Efficient Post- Selection for General Quantum LDPC Codes,
Lee, S.-H., English, L. & Bartlett, S. D. Efficient post- selection for general quantum ldpc codes. Preprint at https://arxiv.org/abs/2510.05795 (2025)
-
[49]
Bausch, J.et al.Learning high-accuracy error decoding for quantum processors.Nature635, 834–840 (2024)
2024
-
[50]
arXiv preprint arXiv:2512.07737 , year=
Senior, A. W.et al.A scalable and real-time neu- ral decoder for topological quantum codes. Preprint at https://arxiv.org/abs/2512.07737 (2025)
-
[51]
& Gidney, C
Higgott, O. & Gidney, C. Sparse Blossom: correcting a million errors per core second with minimum-weight matching.Quantum9, 1600 (2025)
2025
-
[52]
arXiv preprint arXiv:2510.21600 , year=
Maurer, T.et al.Real-time decoding of the gross code memory with FPGAs. Preprint at https://arxiv.org/abs/2510.21600 (2025)
- [53]
-
[54]
Xu, Q.et al.Constant-overhead fault-tolerant quantum computation with reconfigurable atom arrays.Nature Physics20, 1084–1090 (2024)
2024
-
[55]
Breaking the orthogonality barrier in quantum LDPC codes,
Kasai, K. Breaking the orthogonality bar- rier in quantum ldpc codes. Preprint at https://arxiv.org/abs/2601.08824 (2026)
-
[56]
Gottesman, D.Stabilizer codes and quantum error cor- rection. Ph.D. thesis, California Institute of Technology, Pasadena, CA (1997). [57]P L is defined by invertingP block =1−( 1+(1−2PL)R 2 ) k , the block error rate ofkindependent qubits each failing with odd-parity probability[1−(1−2PL)R]/2 overRrounds
1997
-
[57]
& Preskill, J
Dennis, E., Kitaev, A., Landahl, A. & Preskill, J. Topological quantum memory.Journal of Mathematical Physics43, 4452–4505 (2002)
2002
-
[58]
PyMatching: A Python Package for De- coding Quantum Codes with Minimum-Weight Perfect Matching.ACM Transactions on Quantum Computing 3, 1–16 (2022)
Higgott, O. PyMatching: A Python Package for De- coding Quantum Codes with Minimum-Weight Perfect Matching.ACM Transactions on Quantum Computing 3, 1–16 (2022)
2022
-
[59]
C., Kubica, A., Flammia, S
Higgott, O., Bohdanowicz, T. C., Kubica, A., Flammia, S. T. & Campbell, E. T. Improved Decoding of Circuit Noise and Fragile Boundaries of Tailored Surface Codes. Physical Review X13, 031007 (2023)
2023
-
[60]
& Nickerson, N
Delfosse, N. & Nickerson, N. H. Almost-linear time de- coding algorithm for topological codes.Quantum5, 595 (2021)
2021
-
[61]
Hillmann, T.et al.Localized statistics decoding for quan- tum low-density parity-check codes.Nature Communica- tions16(2025)
2025
-
[62]
Nachmani, E.et al.Deep learning methods for improved decoding of linear codes.IEEE Journal of Selected Topics in Signal Processing12, 119–131 (2018)
2018
-
[63]
& Renes, J
Gong, A., Cammerer, S. & Renes, J. M. Graph neural networks for enhanced decoding of quantum ldpc codes. In2024 IEEE International Symposium on Information Theory (ISIT), 2700–2705 (2024)
2024
-
[64]
Ninkovic, V., Kundacina, O., Vukobratovic, D., H¨ ager, C. & i Amat, A. G. Decoding quantum ldpc codes using graph neural networks. Preprint at https://arxiv.org/abs/2408.05170 (2024)
-
[65]
& Poulin, D
Duclos-Cianci, G. & Poulin, D. Fast decoders for topolog- ical quantum codes.Physical Review Letters104(2010)
2010
-
[66]
Local active error correction from simulated con- finement
Lake, E. Local active error correction from simulated con- finement. Preprint at https://arxiv.org/abs/2510.08056 (2025)
-
[67]
InThe Semantic Web, 593–607 (Springer International Publishing, 2018)
Schlichtkrull, M.et al.Modeling Relational Data with Graph Convolutional Networks. InThe Semantic Web, 593–607 (Springer International Publishing, 2018)
2018
-
[68]
& Shi, H
Hassani, A., Walton, S., Li, J., Li, S. & Shi, H. Neighbor- hood attention transformer. In2023 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 6185–6194 (2023)
2023
-
[69]
& Sun, J
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (2016)
2016
-
[70]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A. G.et al.Mobilenets: Efficient convolutional neural networks for mobile vision applications. Preprint at https://arxiv.org/abs/1704.04861 (2017)
work page internal anchor Pith review arXiv 2017
-
[71]
In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11966–11976 (IEEE, 2022)
Liu, Z.et al.A ConvNet for the 2020s. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11966–11976 (IEEE, 2022)
2022
-
[72]
InAdvances in Neural Infor- mation Processing Systems, vol
Yang, G.et al.Tuning large neural networks via zero-shot hyperparameter transfer. InAdvances in Neural Infor- mation Processing Systems, vol. 34, 17084–17097 (Curran Associates, Inc., 2021)
2021
-
[73]
Stim: a fast stabilizer circuit simulator
Gidney, C. Stim: a fast stabilizer circuit simulator. Quantum5, 497 (2021)
2021
-
[74]
Jordan, K.et al.Muon: An optimizer for hidden layers in neural networks.https://kellerjordan.github.io/ posts/muon/(2024)
2024
-
[75]
Symbolic discovery of optimization algorithms,
Chen, X.et al.Symbolic discovery of optimization al- gorithms. Preprint at https://arxiv.org/abs/2302.06675 10 (2023)
-
[76]
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D. P. & Wilson, A. G. Averaging weights leads to wider optima and better generalization. Preprint at https://arxiv.org/abs/1803.05407 (2018)
work page Pith review arXiv 2018
-
[77]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Power, A., Burda, Y., Edwards, H., Babuschkin, I. & Misra, V. Grokking: Generalization beyond over- fitting on small algorithmic datasets. Preprint at https://arxiv.org/abs/2201.02177 (2022)
work page internal anchor Pith review arXiv 2022
-
[78]
InAdvances in Neural Information Processing Systems(2022)
Liu, Z.et al.Towards understanding grokking: An ef- fective theory of representation learning. InAdvances in Neural Information Processing Systems(2022)
2022
-
[79]
& Jochym-O’Connor, T
Maskara, N., Kubica, A. & Jochym-O’Connor, T. Advan- tages of versatile neural-network decoding for topological codes.Phys. Rev. A99, 052351 (2019)
2019
-
[80]
Torchao: Pytorch-native training-to-serving model optimization.https://github.com/pytorch/ao (2024)
torchao. Torchao: Pytorch-native training-to-serving model optimization.https://github.com/pytorch/ao (2024). BSD-3-Clause license
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.