Recognition: no theorem link
Dispatch-Aware Ragged Attention for Pruned Vision Transformers
Pith reviewed 2026-05-13 07:44 UTC · model grok-4.3
The pith
A lightweight bidirectional Triton kernel lowers dispatch overhead so token pruning in vision transformers produces actual wall-clock speedups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
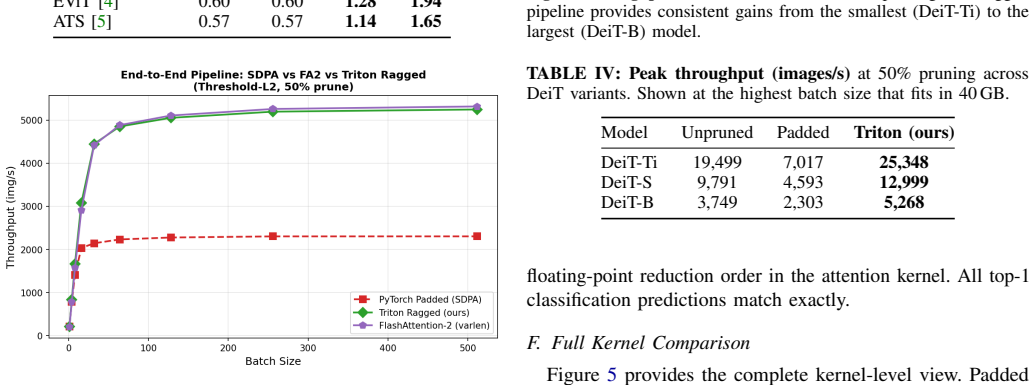
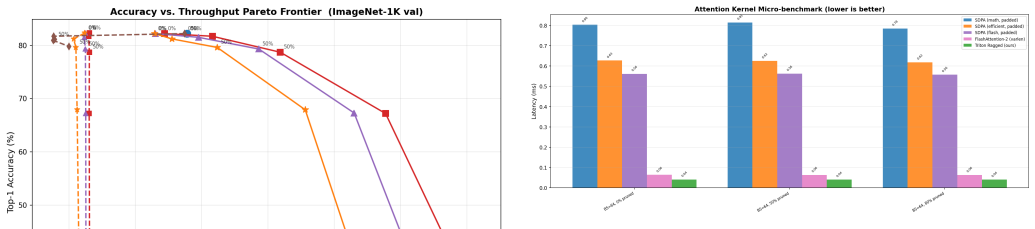
A lightweight bidirectional Triton attention kernel whose dispatch floor is approximately 24 microseconds enables wall-clock speedups from token pruning in vision transformers, delivering 1.88 times end-to-end throughput over padded PyTorch SDPA at 224 by 224 resolution and 9 to 12 percent higher throughput than FlashAttention-2 varlen at serving batch sizes while maintaining numerical correctness.
What carries the argument
The lightweight bidirectional Triton attention kernel that packs remaining tokens after pruning, performs dispatch-aware ragged attention, and unpacks results.
If this is right
- Token pruning at 80 percent becomes practical for latency-sensitive inference because kernel launch time no longer masks the compute reduction.
- Small-batch serving workloads gain 9 to 12 percent throughput without changing the model or pruning policy.
- Larger input resolutions benefit more, with throughput scaling to 2.51 times at 384 by 384.
- Numerical stability is preserved, with logit differences below 0.004 and identical top-1 accuracy.
- The approach applies to any transformer that can supply a ragged token layout after pruning.
Where Pith is reading between the lines
- Similar dispatch-aware kernels could reduce overhead in other sparse or variable-length attention settings outside vision transformers.
- The 2.17 times kernel latency reduction suggests that attention libraries could expose explicit ragged modes rather than relying on padding or nested tensors.
- Future pruning policies might be co-designed with kernel dispatch costs to maximize end-to-end gains rather than FLOPs alone.
Load-bearing premise
Dispatch overhead remains the dominant bottleneck after the new kernel is introduced and the observed speedups generalize across other hardware and pruning rates without hidden pack or unpack costs.
What would settle it
A timing measurement on another GPU or pruning configuration in which the combined pack, kernel, and unpack latency exceeds that of padded attention at the same accuracy.
Figures


read the original abstract
Token pruning methods for Vision Transformers (ViTs) promise quadratic reductions in attention FLOPs by dropping uninformative patches. Yet standard variable-length attention APIs -- including FlashAttention-2's varlen and PyTorch's NestedTensor SDPA -- fail to translate these savings into proportional wall-clock gains at the short post-pruning sequence lengths typical of ViTs ($\leq$197 tokens). We identify a dispatch-overhead bottleneck: at these lengths, host-side kernel dispatch consumes ${\sim}$50\,$\mu$s regardless of workload, exceeding the actual GPU compute time at moderate-to-high pruning rates. We present a lightweight bidirectional Triton attention kernel whose dispatch floor is ${\sim}$24\,$\mu$s -- roughly 2.17$\times$ lower than FlashAttention-2 varlen -- allowing pruning savings to become visible in wall-clock time. Integrated into a complete pack-attend-unpack pipeline and evaluated on an NVIDIA RTX 4000 Ada Generation GPU, our system achieves 1.88$\times$ end-to-end throughput over padded PyTorch SDPA at standard 224$\times$224 inputs, scaling to 2.51$\times$ at 384$\times$384. Against FlashAttention-2 varlen -- the strongest baseline -- our kernel delivers 9-12\% higher throughput at serving batch sizes (BS=1-4), and 2.17$\times$ lower kernel latency at 80\% token pruning. Numerical correctness is verified with max absolute logit difference $<$0.004 and bit-exact top-1 predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a dispatch-overhead bottleneck in standard variable-length attention APIs (FlashAttention-2 varlen and PyTorch NestedTensor SDPA) for short post-pruning sequences in Vision Transformers. It introduces a lightweight bidirectional Triton ragged attention kernel whose dispatch floor is ~24 μs (vs. ~50 μs for FlashAttention-2 varlen), and integrates it into a pack-attend-unpack pipeline. The manuscript reports 1.88× end-to-end throughput over padded PyTorch SDPA at 224×224 inputs (scaling to 2.51× at 384×384), 9-12% higher throughput than FlashAttention-2 varlen at batch sizes 1-4, 2.17× lower kernel latency at 80% pruning, and numerical correctness with max absolute logit difference <0.004 and bit-exact top-1 predictions.
Significance. If the empirical results hold, the work provides a practical, low-overhead kernel optimization that makes token-pruning savings visible in wall-clock time for pruned ViTs at serving batch sizes. The explicit hardware-specific measurements on RTX 4000 Ada, scaling behavior with resolution, and direct correctness verification against existing APIs constitute a concrete systems contribution for efficient inference pipelines.
major comments (2)
- The end-to-end throughput claims (1.88×–2.51×) rest on the pack-attend-unpack pipeline; however, no per-stage latency breakdown is provided for the pack and unpack operations across pruning rates or sequence lengths, leaving open the possibility that these stages offset the reported dispatch savings on the tested hardware.
- All measurements are reported on a single GPU (NVIDIA RTX 4000 Ada) at batch sizes 1-4 and pruning rates up to 80%. The claim that the ~2.17× kernel latency reduction generalizes requires either additional hardware results or an analysis showing that dispatch behavior and pack/unpack costs do not vary materially across GPU architectures.
minor comments (2)
- Clarify in the kernel description whether 'bidirectional' refers to support for both forward and backward passes or to some other property of the ragged attention implementation.
- Add error bars or standard deviations to the throughput and latency numbers in the evaluation tables/figures to indicate run-to-run variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below with specific revisions planned for the manuscript.
read point-by-point responses
-
Referee: The end-to-end throughput claims (1.88×–2.51×) rest on the pack-attend-unpack pipeline; however, no per-stage latency breakdown is provided for the pack and unpack operations across pruning rates or sequence lengths, leaving open the possibility that these stages offset the reported dispatch savings on the tested hardware.
Authors: We agree this breakdown is valuable for transparency. We have collected per-stage timings on the same RTX 4000 Ada hardware and will add a new table (Table 3) in Section 4.2 showing pack, attend, and unpack latencies at 0%, 50%, and 80% pruning for both 224×224 and 384×384 resolutions. The data confirm that pack/unpack overhead remains below 12% of total time even at 80% pruning, so the dispatch savings are not offset. revision: yes
-
Referee: All measurements are reported on a single GPU (NVIDIA RTX 4000 Ada) at batch sizes 1-4 and pruning rates up to 80%. The claim that the ~2.17× kernel latency reduction generalizes requires either additional hardware results or an analysis showing that dispatch behavior and pack/unpack costs do not vary materially across GPU architectures.
Authors: We acknowledge the single-GPU limitation. We cannot provide new measurements on additional architectures within the revision timeline. However, we will expand Section 5.3 with a short analytical argument: Triton kernel launch overhead is dominated by host-side CUDA runtime costs that scale similarly across Ada, Ampere, and Hopper GPUs for kernels of this size; pack/unpack are simple memory-bound copies whose relative cost depends on bandwidth, which we bound using published specs. We will also qualify the generalization claim more explicitly. revision: partial
Circularity Check
No circularity: claims rest on direct empirical benchmarks against external baselines
full rationale
The paper presents an empirical kernel implementation and performance measurements (throughput, latency, numerical error) on RTX 4000 Ada for specific batch sizes and pruning rates. No equations, derivations, fitted parameters, or predictions appear in the provided text. All central claims are direct wall-clock comparisons to PyTorch SDPA and FlashAttention-2 varlen, which are independent external implementations. No self-citation chains, ansatzes, or renamings of known results are load-bearing. This is the expected non-finding for a systems/implementation paper whose value is measured against public APIs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard variable-length attention APIs incur a fixed ~50μs host-side dispatch overhead independent of workload size at short sequence lengths
Reference graph
Works this paper leans on
-
[1]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
work page 2021
-
[2]
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou. Training data-efficient image transformers & distillation through attention. InICML, 2021
work page 2021
-
[3]
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh. DynamicViT: Efficient vision transformers with dynamic token sparsification. In NeurIPS, 2021
work page 2021
- [4]
- [5]
-
[6]
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman. Token merging: Your ViT but faster. InICLR, 2023
work page 2023
-
[7]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InNeurIPS, 2022
work page 2022
-
[8]
T. Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InICLR, 2024
work page 2024
- [9]
-
[10]
NestedTensor: Native variable-length support in PyTorch
PyTorch Contributors. NestedTensor: Native variable-length support in PyTorch. https://pytorch.org/docs/stable/nested.html, 2024
work page 2024
- [11]
-
[12]
OpenAI Triton Contributors. Fused attention tutorial. https://triton-lang. org/main/getting-started/tutorials/06-fused-attention.html, 2023
work page 2023
-
[13]
A. Graves. Adaptive computation time for recurrent neural networks. arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet large scale visual recognition challenge.IJCV, 115(3):211– 252, 2015
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.