Recognition: unknown
DeepER-Med: Advancing Deep Evidence-Based Research in Medicine Through Agentic AI
Pith reviewed 2026-05-10 10:30 UTC · model grok-4.3
The pith
DeepER-Med structures medical research as an explicit agentic workflow that produces novel insights aligned with clinical recommendations in most tested cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
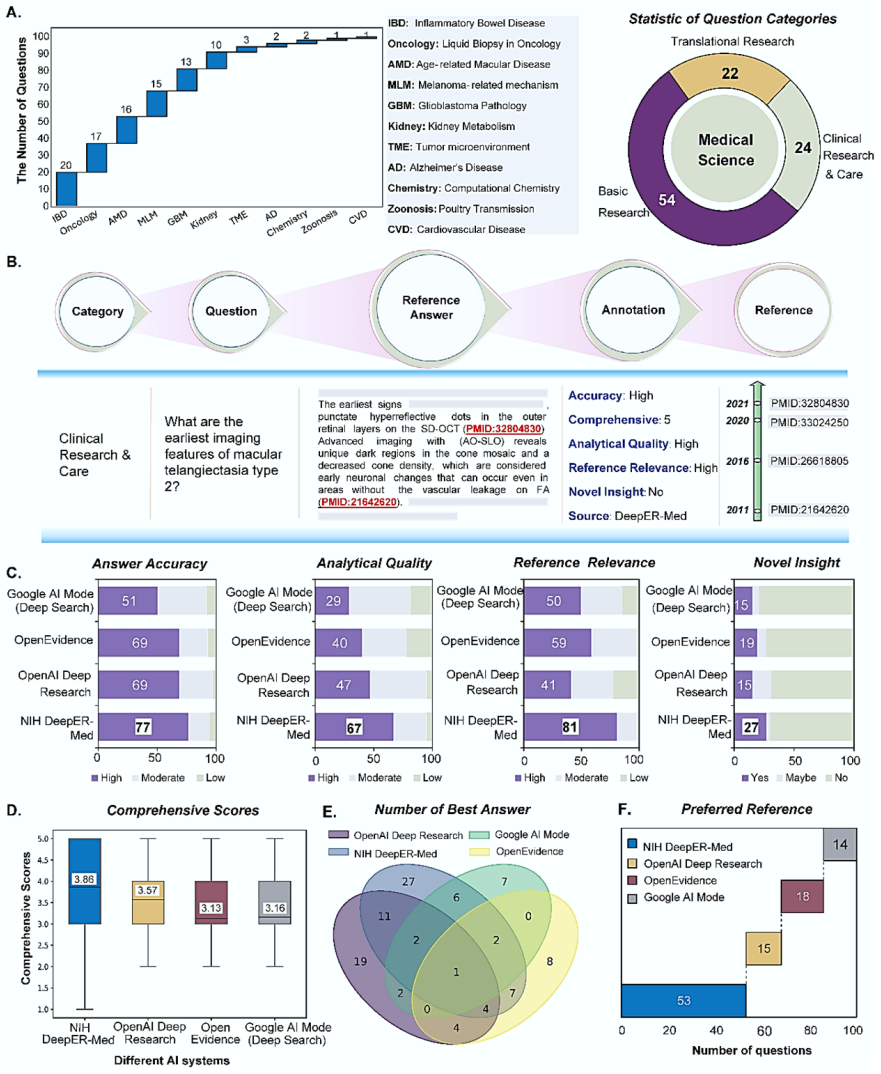
DeepER-Med is an agentic AI system that performs deep evidence-based research in medicine through three modules of research planning, agentic collaboration, and evidence synthesis, outperforming production-grade platforms on multiple criteria including novel scientific insights and aligning with clinical recommendations in seven of eight real-world cases.
What carries the argument
The inspectable workflow of research planning, agentic collaboration, and evidence synthesis that enforces explicit evidence appraisal at each step.
If this is right
- The system can support medical decision making by producing conclusions that align with clinical practice in real cases.
- It enables generation of novel scientific insights that exceed what standard production platforms deliver.
- The DeepER-MedQA dataset provides a realistic benchmark for testing AI on complex, evidence-grounded medical questions.
- Explicit evidence appraisal reduces the risk of compounding errors in research outputs.
Where Pith is reading between the lines
- The workflow could be adapted to other evidence-heavy domains such as legal or policy research if the three-module structure generalizes.
- Larger-scale deployment might reveal whether the alignment rate holds beyond the initial eight cases.
- Integration with existing medical databases could test whether the planning module scales to broader literature searches.
Load-bearing premise
The 11-expert panel produces unbiased questions and objective evaluations of novel insights and clinical alignment.
What would settle it
A new collection of medical research questions evaluated by clinicians where DeepER-Med outputs show lower alignment with recommendations or fewer novel insights than competing platforms.
Figures

read the original abstract
Trustworthiness and transparency are essential for the clinical adoption of artificial intelligence (AI) in healthcare and biomedical research. Recent deep research systems aim to accelerate evidence-grounded scientific discovery by integrating AI agents with multi-hop information retrieval, reasoning, and synthesis. However, most existing systems lack explicit and inspectable criteria for evidence appraisal, creating a risk of compounding errors and making it difficult for researchers and clinicians to assess the reliability of their outputs. In parallel, current benchmarking approaches rarely evaluate performance on complex, real-world medical questions. Here, we introduce DeepER-Med, a Deep Evidence-based Research framework for Medicine with an agentic AI system. DeepER-Med frames deep medical research as an explicit and inspectable workflow of evidence-based generation, consisting of three modules: research planning, agentic collaboration, and evidence synthesis. To support realistic evaluation, we also present DeepER-MedQA, an evidence-grounded dataset comprising 100 expert-level research questions derived from authentic medical research scenarios and curated by a multidisciplinary panel of 11 biomedical experts. Expert manual evaluation demonstrates that DeepER-Med consistently outperforms widely used production-grade platforms across multiple criteria, including the generation of novel scientific insights. We further demonstrate the practical utility of DeepER-Med through eight real-world clinical cases. Human clinician assessment indicates that DeepER-Med's conclusions align with clinical recommendations in seven cases, highlighting its potential for medical research and decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeepER-Med, an agentic AI framework for evidence-based medical research comprising three modules (research planning, agentic collaboration, and evidence synthesis). It also presents the DeepER-MedQA dataset of 100 expert-curated questions from authentic medical scenarios and reports expert manual evaluations claiming that DeepER-Med outperforms production-grade platforms on criteria including novel scientific insight generation, plus alignment with clinical recommendations in 7 of 8 real-world cases.
Significance. If the evaluation claims hold under rigorous controls, the work could advance trustworthy AI for biomedical research by providing an explicit, inspectable workflow and a challenging real-world benchmark dataset. The emphasis on multi-expert curation and clinical case utility is a positive step beyond synthetic benchmarks. However, the unverifiable nature of the headline performance claims substantially reduces the current significance.
major comments (3)
- [Abstract and Results (expert manual evaluation)] The central claim that DeepER-Med 'consistently outperforms widely used production-grade platforms across multiple criteria, including the generation of novel scientific insights' rests entirely on manual expert evaluation by the same 11-expert panel that curated the dataset. No section describes blinding of evaluators to system outputs, inter-rater reliability statistics (e.g., Fleiss' kappa), explicit scoring rubrics or thresholds for 'novel scientific insight,' or statistical tests comparing systems. This directly undermines verifiability of the outperformance result.
- [Abstract and Clinical Cases subsection] The practical utility demonstration states that 'Human clinician assessment indicates that DeepER-Med's conclusions align with clinical recommendations in seven cases.' No details are supplied on the alignment criteria, whether the eight cases were selected independently of the 100-question set, blinding, or quantitative measures of agreement/disagreement. Without these, the 7/8 alignment rate cannot be distinguished from subjective bias.
- [Dataset description (Methods)] DeepER-MedQA is described as 'comprising 100 expert-level research questions derived from authentic medical research scenarios and curated by a multidisciplinary panel of 11 biomedical experts.' No exclusion criteria, inter-rater agreement on question inclusion, or definition of 'authentic' scenarios are provided, raising concerns about selection bias and benchmark objectivity.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the specific production-grade platforms used as baselines and the exact number of criteria on which outperformance was assessed.
- [Framework description] Notation for the three-module workflow could be made more consistent (e.g., explicit labels or a diagram reference) to aid readers in following the agentic collaboration module.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects of transparency in our evaluation methods. We address each major comment below and will incorporate revisions to strengthen the verifiability of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and Results (expert manual evaluation)] The central claim that DeepER-Med 'consistently outperforms widely used production-grade platforms across multiple criteria, including the generation of novel scientific insights' rests entirely on manual expert evaluation by the same 11-expert panel that curated the dataset. No section describes blinding of evaluators to system outputs, inter-rater reliability statistics (e.g., Fleiss' kappa), explicit scoring rubrics or thresholds for 'novel scientific insight,' or statistical tests comparing systems. This directly undermines verifiability of the outperformance result.
Authors: We agree that additional methodological details are required to support verifiability. In the revised manuscript, we will expand the evaluation subsection to describe the protocol in full, including the blinding procedure (outputs were anonymized and evaluators were not informed of the source system), the explicit scoring rubric with thresholds for novel scientific insight and other criteria, inter-rater reliability statistics such as Fleiss' kappa across the 11 experts, and the statistical tests (e.g., Wilcoxon signed-rank) used for system comparisons. These additions will directly address the concern while preserving the expert-driven nature of the assessment. revision: yes
-
Referee: [Abstract and Clinical Cases subsection] The practical utility demonstration states that 'Human clinician assessment indicates that DeepER-Med's conclusions align with clinical recommendations in seven cases.' No details are supplied on the alignment criteria, whether the eight cases were selected independently of the 100-question set, blinding, or quantitative measures of agreement/disagreement. Without these, the 7/8 alignment rate cannot be distinguished from subjective bias.
Authors: We concur that the clinical case description lacks necessary specifics. The revised version will detail the alignment criteria (covering diagnostic conclusions, treatment suggestions, and evidence grounding), confirm independent selection of the eight cases from real-world queries separate from DeepER-MedQA, describe the blinding of assessing clinicians, and report quantitative measures including per-case agreement counts and noted discrepancies. This will allow clearer evaluation of the 7/8 alignment result. revision: yes
-
Referee: [Dataset description (Methods)] DeepER-MedQA is described as 'comprising 100 expert-level research questions derived from authentic medical research scenarios and curated by a multidisciplinary panel of 11 biomedical experts.' No exclusion criteria, inter-rater agreement on question inclusion, or definition of 'authentic' scenarios are provided, raising concerns about selection bias and benchmark objectivity.
Authors: We acknowledge the need for greater precision in the dataset description. We will revise the Methods to specify exclusion criteria (e.g., questions with insufficient public evidence or overly narrow scope), inter-rater agreement on inclusion (percentage agreement and Fleiss' kappa among the 11 experts), and a formal definition of 'authentic' scenarios with sourcing examples from clinical and research contexts. These changes will reduce ambiguity around selection bias and benchmark construction. revision: yes
Circularity Check
No circularity: claims rest on external expert evaluations, not internal definitions or self-referential fits
full rationale
The paper introduces DeepER-Med as an agentic workflow (research planning, agentic collaboration, evidence synthesis) and the DeepER-MedQA dataset curated by an 11-expert panel. Performance claims rely on manual expert assessments of outputs against production platforms and clinical cases. No equations, parameter fitting, or derivations appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central results are therefore not equivalent to inputs by construction; they depend on independent human judgments external to the system's own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI agents guided by explicit criteria can perform reliable multi-hop information retrieval, reasoning, and synthesis without compounding errors.
- domain assumption Expert manual evaluation by a multidisciplinary panel provides an objective and reproducible measure of output quality including novelty of insights.
invented entities (1)
-
DeepER-Med three-module workflow (research planning, agentic collaboration, evidence synthesis)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Considerations for Agentic Research in Public Health
CDC Artificial Intelligence (2026). Considerations for Agentic Research in Public Health. From https://www.cdc.gov/ai/resources/considerations-for-agentic-research-in-public-health.html, retrieved on March 31, 2026
2026
-
[2]
& Zitnik, M
Wang, H., Fu, T., Du, Y ., Gao, W., Huang, K., Liu, Z., ... & Zitnik, M. (2023). Scientific discovery in the age of artificial intelligence. Nature, 620(7972), 47-60
2023
-
[3]
Abou Ali, M., Dornaika, F ., & Charafeddine, J. (2025). Agentic AI: a comprehensive survey of architectures, applications, and future directions. Artificial Intelligence Review, 59(1), 11
2025
-
[4]
Bolanos, F ., Salatino, A., Osborne, F ., & Motta, E. (2024). Artificial intelligence for literature reviews: opportunities and challenges. Artificial Intelligence Review, 57(10), 259
2024
-
[5]
Asai, A., He, J., Shao, R., Shi, W., Singh, A., Chang, J. C., ... & Hajishirzi, H. (2026). Synthesizing scientific literature with retrieval-augmented language models. Nature, 1-7
2026
-
[6]
T., Srinivasan, S., Yang, G
Loke, W. T., Srinivasan, S., Yang, G. D., Zou, K., Ong, A. Y ., Zhu, L. Z., ... & Tham, Y . C. (2025). Can 'Deep Research' agents and general AI agentic systems autonomously perform systematic review and meta - analysis? Eye, 1-3
2025
-
[7]
Završnik, J., Kokol, P ., Žlahtič, B., & Blažun Vošner, H. (2024). Artificial intelligence and pediatrics: synthetic knowledge synthesis. Electronics, 13(3), 512
2024
-
[8]
O., Qiu, T., Shee, Y .,
Li, H., Sarkar, S., Lu, W., Loftus, P . O., Qiu, T., Shee, Y ., ... & Batista, V . S. (2026). Collective intelligence for AI-assisted chemical synthesis. Nature, 1-3
2026
-
[9]
R., & Kulik, H
Xin, H., Kitchin, J. R., & Kulik, H. J. (2025). Towards agentic science for advancing scientific discovery. Nature Machine Intelligence, 7(9), 1373-1375
2025
-
[10]
OpenAI. (2024). Introducing deep research. From https://openai.com/index/introducing -deep-research/, retrieved on February 9, 2026
2024
-
[11]
Patel, N., Grewal, H., Buddhavarapu, V ., Dhillon, G., & Buddavarapru, V . (2025). OpenEvidence: Enhancing medical student clinical rotations with AI but with limitations. Cureus, 17(1), e76867
2025
-
[12]
Nature medicine 31, 3207 (2025)
For trustworthy AI, keep the human in the loop. Nature medicine 31, 3207 (2025)
2025
-
[13]
& Xie, W
Wu, C., Qiu, P ., Liu, J., Gu, H., Li, N., Zhang, Y ., ... & Xie, W. (2025). Towards evaluating and building versatile large language models for medicine. npj Digital Medicine, 8(1), 58
2025
-
[14]
Laurent, J. M., Janizek, J. D., Ruzo, M., Hinks, M. M., Hammerling, M. J., Narayanan, S., ... & Rodriques, S. G. (2024). Lab -bench: Measuring capabilities of language models for biology research. arXiv preprint arXiv:2407.10362
-
[15]
Weidener, L., Brkić, M., Jovanović, M., Singh, R., Baccin, C., Ulgac, E., ... & Meduri, A. (2026). Rethinking the AI Scientist: Interactive Multi-Agent Workflows for Scientific Discovery. arXiv preprint arXiv:2601.12542
-
[16]
Wong, M. Y . H., Ong, A. Y ., Merle, D. A., & Keane, P . A. (2026). Deep Research Agents: Major Breakthrough or Incremental Progress for Medical AI?. Journal of Medical Internet Research, 28, e88195
2026
-
[17]
Subbiah, V . (2023). The next generation of evidence-based medicine. Nature medicine, 29(1), 49-58
2023
-
[18]
F ., Shortliffe, E
Peng, Y ., Rousseau, J. F ., Shortliffe, E. H., & Weng, C. (2023). AI-generated text may have a role in evidence- based medicine. Nature medicine, 29(7), 1593-1594
2023
-
[19]
Li, J., Deng, Y ., Sun, Q., Zhu, J., Tian, Y ., Li, J., & Zhu, T. (2024). Benchmarking large language models in evidence-based medicine. IEEE journal of biomedical and health informatics, 29(9), 6143-6156
2024
-
[20]
(2025, July)
Wu, J., Zhu, J., Liu, Y ., Xu, M., & Jin, Y . (2025, July). Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 28489-28503)
2025
-
[21]
(2025): AI in Search: Going beyond information to intelligence
Google. (2025): AI in Search: Going beyond information to intelligence. From https://blog.google/products- and-platforms/products/search/google-search-ai-mode-update/, retrieved on April 12, 2026
2025
-
[22]
S., Jackson, M
Low, Y . S., Jackson, M. L., Hyde, R. J., Brown, R. E., Sanghavi, N. M., Baldwin, J. D., ... & Gombar, S. (2025). Answering real-world clinical questions using large language model, retrieval-augmented generation, and agentic systems. Digital health, 11, 20552076251348850
2025
-
[23]
C., Yeganova, L., Wilbur, W
Jin, Q., Kim, W., Chen, Q., Comeau, D. C., Yeganova, L., Wilbur, W. J., & Lu, Z. (2023). Medcpt: Contrastive pre-trained transformers with large -scale pubmed search logs for zero -shot biomedical information retrieval. Bioinformatics, 39(11), btad651
2023
-
[24]
Stone, J. V . (2024). Information theory: a tutorial introduction to the principles and applications of information theory
2024
-
[25]
Witten, E. (2020). A mini-introduction to information theory. La Rivista del Nuovo Cimento, 43(4), 187-227
2020
-
[26]
Polyanskiy, Y ., & Wu, Y . (2025). Information theory: From coding to learning. Cambridge university press
2025
-
[27]
Shui, C., Chen, Q., Wen, J., Zhou, F ., Gagné, C., & Wang, B. (2022). A novel domain adaptation theory with Jensen–Shannon divergence. Knowledge-Based Systems, 257, 109808
2022
-
[28]
Fan, W., & Xiao, F . (2022). A complex Jensen –Shannon divergence in complex evidence theory with its application in multi- source information fusion. Engineering Applications of Artificial Intelligence , 116, 105362
2022
-
[29]
& Hooi, B
He, X., Tian, Y ., Sun, Y ., Chawla, N., Laurent, T., LeCun, Y ., ... & Hooi, B. (2024). G -retriever: Retrieval - augmented generation for textual graph understanding and question answering. Advances in Neural Information Processing Systems, 37, 132876-132907
2024
-
[30]
K., Ding, B., Joty, S., Poria, S., & Bing, L
Li, X., Zhao, R., Chia, Y . K., Ding, B., Joty, S., Poria, S., & Bing, L. Chain -of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources. In The Twelfth International Conference on Learning Representations
-
[31]
T., Zhang, S., Carignan, D., Edgar, R., Fusi, N.,
Nori, H., Lee, Y . T., Zhang, S., Carignan, D., Edgar, R., Fusi, N., ... & Horvitz, E. (2023). Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine. Medicine, 84(88.3), 77- 3
2023
-
[32]
Wu, J., Deng, W., Li, X., Liu, S., Mi, T ., Peng, Y ., ... & Zhou, Y . (2025). Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs. arXiv preprint arXiv:2504.00993
-
[33]
W., Hou, L., Longpre, S., Zoph, B., Tay, Y ., Fedus, W.,
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y ., Fedus, W., ... & Wei, J. (2024). Scaling instruction - finetuned language models. Journal of Machine Learning Research, 25(70), 1-53
2024
-
[34]
(2019, November)
Jin, Q., Dhingra, B., Liu, Z., Cohen, W., & Lu, X. (2019, November). Pubmedqa: A dataset for biomedical research question answering. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP) (pp. 2567-2577)
2019
- [35]
-
[36]
Gupta, D., Bartels, D., & Demner -Fushman, D. (2025). a Dataset of Medical Questions Paired with automatically Generated answers and Evidence-supported References. Scientific Data, 12(1), 1035
2025
- [37]
-
[38]
UI Health (UIC): Researchers and Clinicians. (2026). Precision Oncology Tumor Board. From https://cancer.uillinois.edu/researchers-clinicians/precision-oncology-tumor-board/, retrieved on February 20, 2026
2026
-
[39]
& Leskovec, J
Huang, K., Zhang, S., Wang, H., Qu, Y ., Lu, Y ., Roohani, Y ., ... & Leskovec, J. (2025). Biomni: A general - purpose biomedical ai agent. bioRxiv
2025
- [40]
-
[41]
Sokolova, K., Kosenkov, D., Nallamotu, K., Vedula, S., Sokolov, D., Sapiro, G., & Troyanskaya, O. G. (2025). An Evidence-Grounded Research Assistant for Functional Genomics and Drug Target Assessment. bioRxiv, 2025-12
2025
-
[42]
T., Xu, E., Singh, K., Lavaert, M., Link, V
Zhang, Y ., Bailey, J. T., Xu, E., Singh, K., Lavaert, M., Link, V . M., ... & Yang, Q. (2022). Mucosal -associated invariant T cells restrict reactive oxidative damage and preserve meningeal barrier integrity and cognitive function. Nature immunology, 23(12), 1714-1725
2022
-
[43]
T., Nakajima, D., & Fujimaki, H
Win-Shwe, T. T., Nakajima, D., & Fujimaki, H. (2010). Can T -cell deficiency affect spatial learning ability following toluene exposure? Neuroimmunomodulation, 17(2), 132-134
2010
-
[44]
Hao, Q., Xu, F ., Li, Y ., & Evans, J. (2026). Artificial intelligence tools expand scientists’ impact but contract science’s focus. Nature, 1-7
2026
-
[45]
Microsoft Corporation. (2025). Azure OpenAI in Azure AI Foundry Models 2025 May 20. From https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models?tabs=global- standard%2Cstandard-chat-completions, retrieved on February 9, 2026
2025
-
[46]
MongoDB –The application data platform
MongoDB, Inc. MongoDB –The application data platform. From https://www.mongodb.com/, retrieved on February 9, 2026
2026
-
[47]
Islam, R., & Moushi, O. M. (2025, June). Gpt -4o: The cutting -edge advancement in multimodal llm. In Intelligent Computing Proceedings of the Computing Conference (pp. 47 -60). Cham: Springer Nature Switzerland
2025
-
[48]
Chandak, P ., Huang, K., & Zitnik, M. (2023). Building a knowledge graph to enable precision medicine. Scientific data, 10(1), 67
2023
-
[49]
I., Baker, K
Hutchins, B. I., Baker, K. L., Davis, M. T., Diwersy, M. A., Haque, E., Harriman, R. M., ... & Santangelo, G. M. (2019). The NIH Open Citation Collection: A public access, broad coverage resource. PLoS biology, 17(10), e3000385
2019
-
[50]
S., Nadkarni, G
Omar, M., Nassar, S., Hijazi, K., Glicksberg, B. S., Nadkarni, G. N., & Klang, E. (2025). Generating credible referenced medical research: A comparative study of openAI's GPT -4 and Google's gemini. Computers in biology and medicine, 185, 109545
2025
-
[51]
Streamlit— The fastest way to build data apps in Python
Streamlit. Streamlit— The fastest way to build data apps in Python. From https://streamlit.io/, retrieved on February 9, 2026
2026
-
[52]
OpenAI. (2025). Introducing GPT -5.2. From https://openai.com/index/introducing -gpt-5-2/, retrieved on February 9, 2026. Appendix Append Table 1. Comparing DeepER-Med with existing AI agents . Five dimensions spanning evidence presence, transparency in evidence inclusion, medical -oriented research, research-level agents, and expert-aligned evaluation ar...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.