Recognition: unknown
ProtoTTA: Prototype-Guided Test-Time Adaptation
Pith reviewed 2026-05-10 11:30 UTC · model grok-4.3
The pith
ProtoTTA adapts prototypical models at test time by minimizing entropy of prototype similarities to improve robustness and restore semantic focus under distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProtoTTA minimizes the entropy of the prototype-similarity distribution on shifted data to encourage confident and prototype-specific activations. Geometric filtering limits updates to samples with reliable activations, and regularization by prototype-importance weights plus model-confidence scores maintains stability. The resulting adaptation improves robustness relative to output-based entropy minimization and restores correct semantic focus in the prototype activations, as measured by novel interpretability metrics and vision-language model evaluations across fine-grained vision, histopathology, and NLP tasks.
What carries the argument
Entropy minimization on the distribution of input-to-prototype similarities, stabilized by geometric filtering of reliable samples.
If this is right
- Prototypical models gain higher accuracy on shifted data while keeping their built-in interpretability.
- Prototype activations realign with the original semantic concepts they were trained to capture.
- The same adaptation procedure works across different prototypical architectures in vision, medical, and text domains.
- Novel interpretability metrics and VLM evaluation provide a quantitative check on whether adaptation preserves human-aligned reasoning.
Where Pith is reading between the lines
- The same entropy-minimization idea on intermediate signals could be tested in other interpretable architectures that expose class-specific representations.
- Preserving prototype focus during adaptation may reduce the need for costly re-annotation of shifted data in domains where interpretability matters.
- If prototypes themselves drift under extreme shifts, an extension that also updates the prototype set could be examined.
Load-bearing premise
Minimizing entropy of the prototype-similarity distribution on shifted data will produce more confident and correct prototype-specific activations without introducing new errors or requiring the prototypes themselves to remain valid under the shift.
What would settle it
If accuracy on the shifted benchmarks fails to rise or the new semantic-alignment and VLM-rated metrics show no improvement over standard output-entropy minimization, the claim that prototype-guided adaptation restores focus and robustness would be falsified.
Figures







read the original abstract
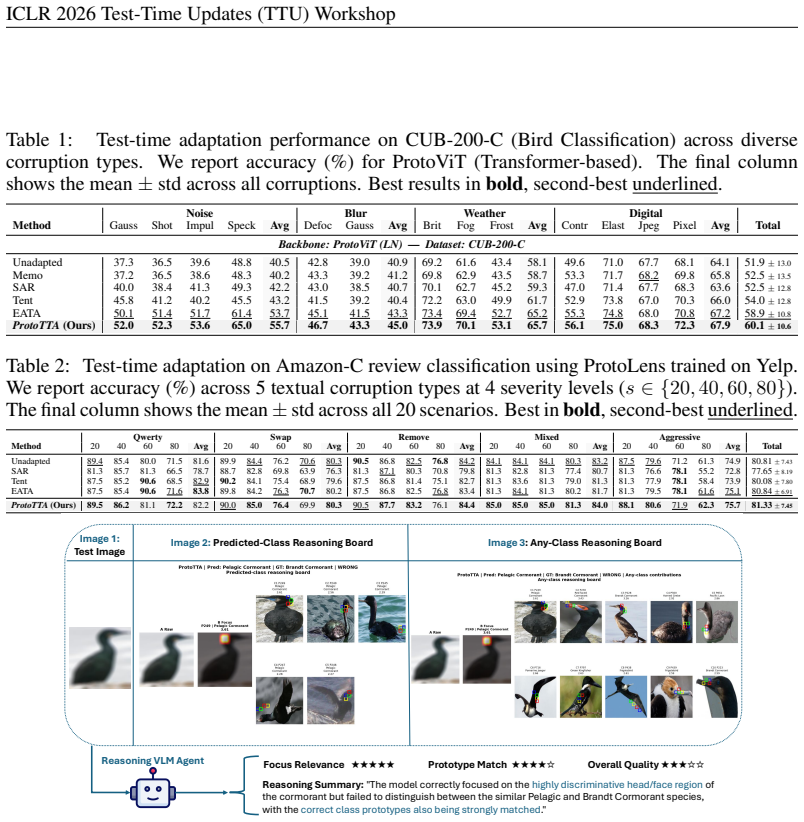
Deep networks that rely on prototypes-interpretable representations that can be related to the model input-have gained significant attention for balancing high accuracy with inherent interpretability, which makes them suitable for critical domains such as healthcare. However, these models are limited by their reliance on training data, which hampers their robustness to distribution shifts. While test-time adaptation (TTA) improves the robustness of deep networks by updating parameters and statistics, the prototypes of interpretable models have not been explored for this purpose. We introduce ProtoTTA, a general framework for prototypical models that leverages intermediate prototype signals rather than relying solely on model outputs. ProtoTTA minimizes the entropy of the prototype-similarity distribution to encourage more confident and prototype-specific activations on shifted data. To maintain stability, we employ geometric filtering to restrict updates to samples with reliable prototype activations, regularized by prototype-importance weights and model-confidence scores. Experiments across four prototypical backbones on four diverse benchmarks spanning fine-grained vision, histopathology, and NLP demonstrate that ProtoTTA improves robustness over standard output entropy minimization while restoring correct semantic focus in prototype activations. We also introduce novel interpretability metrics and a vision-language model (VLM) evaluation framework to explain TTA dynamics, confirming ProtoTTA restores human-aligned semantic focus and correlates reliably with VLM-rated reasoning quality. Code is available at: https://github.com/DeepRCL/ProtoTTA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProtoTTA, a test-time adaptation framework tailored to prototype-based interpretable models. It minimizes the entropy of the prototype-similarity distribution on unlabeled shifted data to promote confident, prototype-specific activations, while applying geometric filtering to restrict updates to samples with reliable activations, regularized by prototype-importance weights and model confidence. Experiments across four prototypical backbones on four benchmarks (fine-grained vision, histopathology, NLP) claim improved robustness over standard output-entropy TTA, and new interpretability metrics plus a VLM evaluation framework are introduced to demonstrate restoration of human-aligned semantic focus in the adapted prototype activations. Code is provided.
Significance. If the empirical gains and semantic-restoration claims hold under rigorous validation, ProtoTTA would meaningfully extend the usability of inherently interpretable prototype models to distribution-shifted regimes, especially in high-stakes domains such as healthcare. The introduction of VLM-based reasoning-quality evaluation for TTA dynamics constitutes a potentially reusable methodological contribution that could improve how future adaptation methods are assessed for semantic fidelity rather than accuracy alone.
major comments (3)
- [Method (entropy minimization and geometric filtering)] The central mechanism (entropy minimization over fixed prototype similarities plus geometric filtering) assumes source prototypes remain semantically aligned after shift. When low-level feature changes occur, the similarity distribution can peak on incorrect prototypes; filtering then excludes ambiguous samples rather than correcting the mapping. This directly affects the claim of 'restoring correct semantic focus' and requires explicit validation (e.g., controlled misalignment experiments or oracle prototype-label checks) that is not evident from the reported metrics.
- [Experiments and interpretability evaluation] The novel interpretability metrics and VLM ratings are presented as confirming human-aligned semantic restoration, yet they appear to quantify post-adaptation confidence and surface plausibility rather than verifying that activated prototypes match the original source-defined semantics. Without an ablation that isolates whether gains arise from true semantic correction versus selective exclusion of misaligned samples, the interpretability claims remain under-supported.
- [Abstract and Experiments] No quantitative results, error bars, data-split details, or statistical significance tests are referenced even in the high-level experimental summary, making it impossible to gauge the magnitude, consistency, or reliability of the reported gains over standard TTA.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., average accuracy gain or interpretability score) to allow readers to immediately assess the scale of improvement.
- [Method] Notation for the prototype-similarity distribution and the geometric filter threshold should be introduced with explicit equations early in the method section to improve readability.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing our honest assessment and outlining revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (entropy minimization and geometric filtering)] The central mechanism (entropy minimization over fixed prototype similarities plus geometric filtering) assumes source prototypes remain semantically aligned after shift. When low-level feature changes occur, the similarity distribution can peak on incorrect prototypes; filtering then excludes ambiguous samples rather than correcting the mapping. This directly affects the claim of 'restoring correct semantic focus' and requires explicit validation (e.g., controlled misalignment experiments or oracle prototype-label checks) that is not evident from the reported metrics.
Authors: We appreciate the referee's careful analysis of the core assumptions. The geometric filtering is explicitly designed to avoid updating on samples with unreliable prototype activations under shift, thereby preventing performance degradation rather than attempting to correct fundamentally misaligned mappings. Entropy minimization is applied only to the filtered samples to sharpen activations toward the most similar available prototypes. While we maintain that this approach restores semantic focus in practice for the distribution shifts tested (as evidenced by our interpretability metrics), we acknowledge that additional controlled validation would strengthen the claims. In the revision, we will add experiments using synthetic low-level feature perturbations to induce controlled misalignment, along with oracle prototype-label consistency checks on a subset of data where ground-truth prototype mappings can be defined. revision: partial
-
Referee: [Experiments and interpretability evaluation] The novel interpretability metrics and VLM ratings are presented as confirming human-aligned semantic restoration, yet they appear to quantify post-adaptation confidence and surface plausibility rather than verifying that activated prototypes match the original source-defined semantics. Without an ablation that isolates whether gains arise from true semantic correction versus selective exclusion of misaligned samples, the interpretability claims remain under-supported.
Authors: We thank the referee for this important distinction. Our interpretability metrics measure changes in prototype activation patterns relative to source semantics, and the VLM evaluation assesses whether the activated prototypes support human-aligned reasoning on shifted inputs. However, we agree that an explicit ablation isolating the contribution of semantic sharpening versus sample exclusion would better support the claims. We will add this ablation in the revised manuscript, comparing full ProtoTTA against variants without geometric filtering and analyzing prototype activation fidelity on samples that remain after filtering. revision: yes
-
Referee: [Abstract and Experiments] No quantitative results, error bars, data-split details, or statistical significance tests are referenced even in the high-level experimental summary, making it impossible to gauge the magnitude, consistency, or reliability of the reported gains over standard TTA.
Authors: We apologize for the lack of quantitative detail in the abstract and high-level summary, which was an oversight. The full experimental section reports mean accuracy improvements with standard deviations across multiple random seeds, details on data splits, and statistical significance tests (e.g., paired t-tests) comparing ProtoTTA to baselines. We will revise the abstract to include specific quantitative gains (such as average accuracy improvements over output-entropy TTA) and ensure all experimental summaries explicitly reference error bars, splits, and significance results. revision: yes
Circularity Check
No circularity in method proposal or empirical claims
full rationale
The paper defines ProtoTTA as a new TTA procedure that minimizes entropy over prototype-similarity distributions (with geometric filtering and regularization) and then reports empirical gains on four backbones and four benchmarks plus new interpretability metrics. No equation or claim reduces by construction to its own inputs; the central mechanism is a design choice whose correctness is asserted via external validation rather than tautology. No self-definitional, fitted-prediction, or load-bearing self-citation patterns appear in the abstract or described framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prototype activations provide reliable intermediate signals for guiding adaptation under distribution shifts
Reference graph
Works this paper leans on
-
[1]
Tide: Training locally interpretable domain generalization models enables test-time correction
Aishwarya Agarwal, Srikrishna Karanam, and Vineet Gandhi. Tide: Training locally interpretable domain generalization models enables test-time correction. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 30210--30220, 2025
2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Grounded test-time adaptation for llm agents
Arthur Chen, Zuxin Liu, Jianguo Zhang, Akshara Prabhakar, Zhiwei Liu, Shelby Heinecke, Silvio Savarese, Victor Zhong, and Caiming Xiong. Grounded test-time adaptation for llm agents. arXiv preprint arXiv:2511.04847, 2025
-
[4]
This looks like that: deep learning for interpretable image recognition
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems, 32, 2019
2019
-
[5]
Deformable protopnet: An interpretable image classifier using deformable prototypes
Jon Donnelly, Alina Jade Barnett, and Chaofan Chen. Deformable protopnet: An interpretable image classifier using deformable prototypes. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10265--10275, 2022
2022
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. Proceedings of the International Conference on Learning Representations, 2019
2019
-
[8]
Novel dataset for fine-grained image categorization: Stanford dogs
Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Fei-Fei Li. Novel dataset for fine-grained image categorization: Stanford dogs. In Proc. CVPR workshop on fine-grained visual categorization (FGVC), volume 2, 2011
2011
-
[9]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
A comprehensive survey on test-time adaptation under distribution shifts
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 133 0 (1): 0 31–64, July 2024. ISSN 1573-1405. doi:10.1007/s11263-024-02181-w. URL http://dx.doi.org/10.1007/s11263-024-02181-w
-
[11]
Interpretable image classification with adaptive prototype-based vision transformers
Chiyu Ma, Jon Donnelly, Wenjun Liu, Soroush Vosoughi, Cynthia Rudin, and Chaofan Chen. Interpretable image classification with adaptive prototype-based vision transformers. Advances in Neural Information Processing Systems, 37: 0 41447--41493, 2024
2024
-
[12]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. In The Internetional Conference on Machine Learning, 2022
2022
-
[13]
Towards stable test-time adaptation in dynamic wild world
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world. In Internetional Conference on Learning Representations, 2023
2023
-
[14]
Diffusion-tta: Test-time adaptation of discriminative models via generative feedback
Mihir Prabhudesai, Tsung-Wei Ke, Alex Li, Deepak Pathak, and Katerina Fragkiadaki. Diffusion-tta: Test-time adaptation of discriminative models via generative feedback. Advances in Neural Information Processing Systems, 36: 0 17567--17583, 2023
2023
-
[15]
Models in the wild: On corruption robustness of neural nlp systems
Barbara Rychalska, Dominika Basaj, Alicja Gosiewska, and Przemys aw Biecek. Models in the wild: On corruption robustness of neural nlp systems. In International Conference on Neural Information Processing, pp.\ 235--247. Springer, 2019
2019
-
[16]
Sahil Sethi, David Chen, Thomas Statchen, Michael C Burkhart, Nipun Bhandari, Bashar Ramadan, and Brett Beaulieu-Jones. Protoecgnet: Case-based interpretable deep learning for multi-label ecg classification with contrastive learning. arXiv preprint arXiv:2504.08713, 2025
-
[17]
SICAPv2 - prostate whole slide images with gleason grades annotations, 2020
Julio Silva-Rodríguez. SICAPv2 - prostate whole slide images with gleason grades annotations, 2020. URL https://data.mendeley.com/datasets/9xxm58dvs3/1
2020
-
[18]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Mpnet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. Mpnet: Masked and permuted pre-training for language understanding. Advances in neural information processing systems, 33: 0 16857--16867, 2020
2020
-
[20]
Protoasnet: Dynamic prototypes for inherently interpretable and uncertainty-aware aortic stenosis classification in echocardiography
Hooman Vaseli, Ang Nan Gu, S Neda Ahmadi Amiri, Michael Y Tsang, Andrea Fung, Nima Kondori, Armin Saadat, Purang Abolmaesumi, and Teresa SM Tsang. Protoasnet: Dynamic prototypes for inherently interpretable and uncertainty-aware aortic stenosis classification in echocardiography. In International conference on medical image computing and computer-assisted...
2023
-
[21]
Happi: Hyperbolic hierarchical part prototypes for image recognition
Hooman Vaseli, Victoria Wu, Nima Kondori, Nguyen Nhat Minh To, Andrea Fung, Ang Nan Gu, and Purang Abolmaesumi. Happi: Hyperbolic hierarchical part prototypes for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 685--694, 2025
2025
-
[22]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. Jul 2011
2011
-
[23]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review arXiv 2006
-
[24]
P roto L ens: Advancing prototype learning for fine-grained interpretability in text classification
Bowen Wei and Ziwei Zhu. P roto L ens: Advancing prototype learning for fine-grained interpretability in text classification. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4503--4523, Vienna, Austri...
-
[25]
Mprotonet: A case-based interpretable model for brain tumor classification with 3d multi-parametric magnetic resonance imaging
Yuanyuan Wei, Roger Tam, and Xiaoying Tang. Mprotonet: A case-based interpretable model for brain tumor classification with 3d multi-parametric magnetic resonance imaging. In Medical Imaging with Deep Learning, pp.\ 1798--1812. PMLR, 2024
2024
-
[26]
Protopformer: concentrating on prototypical parts in vision transformers for interpretable image recognition
Mengqi Xue, Qihan Huang, Haofei Zhang, Jingwen Hu, Jie Song, Mingli Song, and Canghong Jin. Protopformer: concentrating on prototypical parts in vision transformers for interpretable image recognition. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pp.\ 1516--1524, 2024
2024
-
[27]
Memo: Test time robustness via adaptation and augmentation
Marvin Zhang, Sergey Levine, and Chelsea Finn. Memo: Test time robustness via adaptation and augmentation. Advances in neural information processing systems, 35: 0 38629--38642, 2022
2022
-
[28]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[29]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[30]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[31]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.