Recognition: unknown
Brain Score Tracks Shared Properties of Languages: Evidence from Many Natural Languages and Structured Sequences
Pith reviewed 2026-05-10 11:00 UTC · model grok-4.3
The pith
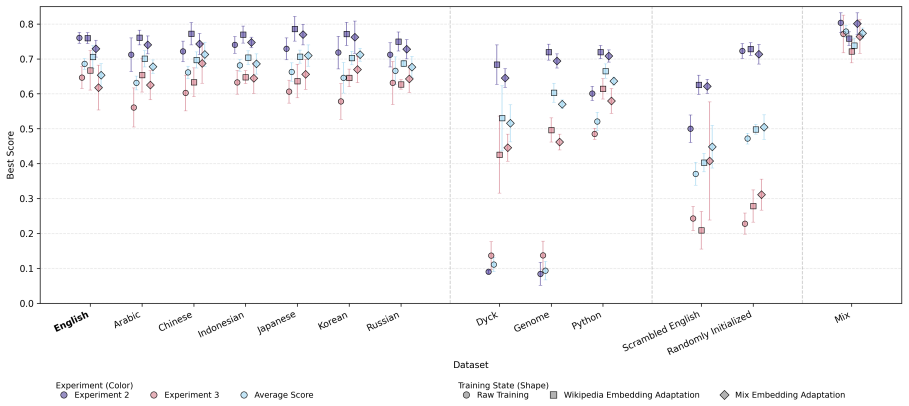
Models trained on genomes, Python, or nested brackets achieve Brain Scores close to natural-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Language models trained on diverse natural languages from many families yield similar Brain Scores, while models trained on the human genome, Python code, and nested parentheses also produce Brain Scores close to those of natural-language models. Brain Score therefore measures models' ability to extract common structural properties present across structured sequences rather than features unique to human language.
What carries the argument
Brain Score, defined as the accuracy with which language-model hidden states predict fMRI voxel responses recorded while humans read natural sentences.
Load-bearing premise
That Brain Score still measures similarity to human language processing when the model has never seen natural language in its training data.
What would settle it
Finding that models trained on unstructured random sequences produce Brain Scores as high as those from genome, code, or natural-language training would show the metric does not track shared structural properties.
Figures

read the original abstract
Recent breakthroughs in language models (LMs) using neural networks have raised the question: how similar are these models' processing to human language processing? Results using a framework called Brain Score (BS) -- predicting fMRI activations during reading from LM activations -- have been used to argue for a high degree of similarity. To understand this similarity, we conduct experiments by training LMs on various types of input data and evaluate them on BS. We find that models trained on various natural languages from many different language families have very similar BS performance. LMs trained on other structured data -- the human genome, Python, and pure hierarchical structure (nested parentheses) -- also perform reasonably well and close to natural languages in some cases. These findings suggest that BS can highlight language models' ability to extract common structure across natural languages, but that the metric may not be sensitive enough to allow us to infer human-like processing from a high BS score alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the specificity of Brain Score (BS) by training language models on a variety of natural languages from different families and on non-linguistic structured sequences including the human genome, Python code, and nested parentheses. It reports that BS performance is similar across natural languages and reasonably close for the structured data models, suggesting that BS measures shared structural properties rather than uniquely human language processing.
Significance. If the quantitative results support the qualitative claims, this paper makes a valuable contribution by providing evidence that high Brain Scores can be achieved without training on natural language, thereby limiting the inferences one can draw about human-like processing from BS alone. The use of diverse natural languages and multiple types of structured data is a strength, as is the focus on falsifying the specificity of the metric. This could prompt reevaluation of BS as a benchmark in the field.
major comments (3)
- [Results] The claim that LMs trained on genome, Python, and nested parentheses 'perform reasonably well and close to natural languages in some cases' is central but presented without specific numerical BS values, standard errors, or p-values comparing to natural language baselines (see also the abstract). This makes it impossible to assess the magnitude and reliability of the 'close' performance.
- [Methods] There is no mention of controlling for model size, training data volume, or number of parameters across the different training regimes. Since BS involves linear regression from LM activations, differences in model capacity could confound the comparisons between natural language and structured data models.
- [Discussion] The interpretation that BS 'may not be sensitive enough to allow us to infer human-like processing' rests on the assumption that the fMRI prediction task remains valid for models without natural language exposure; however, no analysis is provided on the quality of the linear mappings or voxel selection for these models.
minor comments (2)
- [Abstract] The abstract uses vague terms like 'reasonably well' and 'in some cases' without quantifying what that means; consider adding a brief mention of the range of BS values observed.
- [Introduction] Ensure that the definition of Brain Score is clearly restated with reference to the original BS paper for readers unfamiliar with the framework.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the constructive feedback and the recognition of the paper's potential contribution. Below we provide point-by-point responses to the major comments, outlining the revisions we will make to address them.
read point-by-point responses
-
Referee: [Results] The claim that LMs trained on genome, Python, and nested parentheses 'perform reasonably well and close to natural languages in some cases' is central but presented without specific numerical BS values, standard errors, or p-values comparing to natural language baselines (see also the abstract). This makes it impossible to assess the magnitude and reliability of the 'close' performance.
Authors: We agree that the presentation would benefit from more precise quantitative details. In the revised manuscript, we will include a table or expanded figure caption with the exact Brain Score values for models trained on genome, Python, and nested parentheses, along with standard errors and p-values from statistical tests against the natural language baselines. This will enable readers to evaluate the degree of similarity more rigorously. revision: yes
-
Referee: [Methods] There is no mention of controlling for model size, training data volume, or number of parameters across the different training regimes. Since BS involves linear regression from LM activations, differences in model capacity could confound the comparisons between natural language and structured data models.
Authors: We recognize this potential issue. Our models were based on comparable transformer architectures, but parameter counts and data volumes were not strictly matched across all conditions owing to the unique characteristics of each dataset. We will update the Methods section to detail the specific model configurations, including parameter numbers and training data sizes. We will also discuss the implications of any mismatches and consider adding a control experiment if possible in future work, though for the current revision we will at minimum provide transparency on these factors. revision: partial
-
Referee: [Discussion] The interpretation that BS 'may not be sensitive enough to allow us to infer human-like processing' rests on the assumption that the fMRI prediction task remains valid for models without natural language exposure; however, no analysis is provided on the quality of the linear mappings or voxel selection for these models.
Authors: The Brain Score framework applies the identical prediction pipeline, including linear regression and voxel selection (retaining voxels with significant cross-validated prediction), to all models irrespective of their training data. This ensures the task validity by construction. To address the referee's point, we will incorporate additional analyses in the revised version, such as reporting average R^2 values of the linear mappings and the number of selected voxels for the non-natural-language models, to confirm that the prediction quality is not substantially degraded. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper reports empirical results from training LMs on natural languages, the human genome, Python code, and nested parentheses, then directly comparing their Brain Scores on fMRI prediction during language reading. No equations, parameter fitting, derivations, or self-citations are described that reduce any claim to its inputs by construction. All central findings are presented as measured outcomes of distinct training regimes, rendering the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Douglas Biber. 1988. Variation across speech and writing. Cambridge University Press, Cambridge, England
1988
-
[4]
Douglas Biber. 1993. https://aclanthology.org/J93-2001/ Using Register - Diversified Corpora for General Language Studies . Computational Linguistics, 19(2):219--241
1993
-
[5]
Zhenguang Cai, Xufeng Duan, David Haslett, Shuqi Wang, and Martin Pickering. 2024. https://doi.org/10.18653/v1/2024.cmcl-1.4 Do large language models resemble humans in language use? In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics , pages 37--56, Bangkok, Thailand. Association for Computational Linguistics
-
[6]
Cheng-Han Chiang and Hung-yi Lee. 2022. https://doi.org/10.1609/aaai.v36i10.21295 On the Transferability of Pre -trained Language Models : A Study from Artificial Datasets . Proceedings of the AAAI Conference on Artificial Intelligence, 36(10):10518--10525
-
[7]
Dryer and Martin Haspelmath, editors
Matthew S. Dryer and Martin Haspelmath, editors. 2013. https://doi.org/10.5281/zenodo.13950591 WALS Online (v2020.4) . Zenodo
-
[8]
Manuel Faysse. 2023. https://huggingface.co/datasets/manu/project_gutenberg Project Gutenberg . Hugging Face Datasets
2023
-
[9]
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, and Jonathan C. Kao. 2024. https://doi.org/10.48550/arXiv.2406.01538 What Are Large Language Models Mapping to in the Brain ? A Case Against Over - Reliance on Brain Scores . ArXiv:2406.01538 [cs]
-
[10]
Hosseini, Martin Schrimpf, Yian Zhang, Samuel Bowman, Noga Zaslavsky, and Evelina Fedorenko
Eghbal A. Hosseini, Martin Schrimpf, Yian Zhang, Samuel Bowman, Noga Zaslavsky, and Evelina Fedorenko. 2024. https://doi.org/10.1162/nol_a_00137 Artificial Neural Network Language Models Predict Human Brain Responses to Language Even After a Developmentally Realistic Amount of Training . Neurobiology of Language, 5(1):43--63
-
[11]
Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen
Michael Y. Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen. 2025. https://doi.org/10.18653/v1/2025.acl-long.478 Between Circuits and Chomsky : Pre -pretraining on Formal Languages Imparts Linguistic Biases . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 9691--9709...
-
[12]
Liangze Jiang, Zachary Shinnick, Anton van den Hengel, Hemanth Saratchandran, and Damien Teney. 2026. https://doi.org/10.48550/arXiv.2601.21725 Procedural Pretraining : Warming Up Language Models with Abstract Data . ArXiv:2601.21725 [cs]
-
[13]
Carina Kauf, Greta Tuckute, Roger Levy, Jacob Andreas, and Evelina Fedorenko. 2024. https://doi.org/10.1162/nol_a_00116 Lexical- Semantic Content , Not Syntactic Structure , Is the Main Contributor to ANN - Brain Similarity of fMRI Responses in the Language Network . Neurobiology of Language, 5(1):7--42
-
[14]
Najoung Kim, Sebastian Schuster, and Shubham Toshniwal. 2024. https://doi.org/10.48550/arXiv.2405.21068 Code Pretraining Improves Entity Tracking Abilities of Language Models . ArXiv:2405.21068 [cs]
-
[15]
Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. 2022. The Stack : 3 TB of permissively licensed source code. Preprint
2022
-
[16]
National Center for Biotechnology Information . 2022. https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_000001405.40/ Genome assembly GRCh38.p14 . Accession No. GCF\_000001405.40
2022
-
[17]
Isabel Papadimitriou and Dan Jurafsky. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.554 Learning Music Helps You Read : Using Transfer to Study Linguistic Structure in Language Models . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 6829--6839, Online. Association for Computational Linguistics
-
[18]
Isabel Papadimitriou and Dan Jurafsky. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.563 Injecting structural hints: Using language models to study inductive biases in language learning . In Findings of the Association for Computational Linguistics : EMNLP 2023 , pages 8402--8413, Singapore. Association for Computational Linguistics
-
[19]
Hale, Bertrand Thirion, and Christophe Pallier
Alexandre Pasquiou, Yair Lakretz, John T. Hale, Bertrand Thirion, and Christophe Pallier. 2022. https://proceedings.mlr.press/v162/pasquiou22a.html Neural Language Models are not Born Equal to Fit Brain Data , but Training Helps . In Proceedings of the 39th International Conference on Machine Learning , pages 17499--17516. PMLR
2022
-
[20]
Gershman, Nancy Kanwisher, Matthew Botvinick, and Evelina Fedorenko
Francisco Pereira, Bin Lou, Brianna Pritchett, Samuel Ritter, Samuel J. Gershman, Nancy Kanwisher, Matthew Botvinick, and Evelina Fedorenko. 2018. https://doi.org/10.1038/s41467-018-03068-4 Toward a universal decoder of linguistic meaning from brain activation . Nature Communications, 9(1):963
-
[21]
Project Gutenberg . n.d. https://www.gutenberg.org/ [link]
-
[22]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf Language Models are Unsupervised Multitask Learners . OpenAI Blog
2019
-
[23]
Ryokan Ri and Yoshimasa Tsuruoka. 2022. https://doi.org/10.18653/v1/2022.acl-long.504 Pretraining with Artificial Language : Studying Transferable Knowledge in Language Models . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 7302--7315, Dublin, Ireland. Association for Computati...
-
[24]
Hosseini, Nancy Kanwisher, Joshua B
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. 2021. https://doi.org/10.1073/pnas.2105646118 The neural architecture of language: Integrative modeling converges on predictive processing . Proceedings of the National Academy of Sciences, 118(45):e2105646118
-
[25]
Majaj, Rishi Rajalingham, Elias B
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. 2018. https://www.biorxiv.org/content/10.1101/407007v2 Brain-score: Which artificial neural network for object recognition is most brain...
-
[26]
Martin Schrimpf, Jonas Kubilius, Michael J Lee, N Apurva Ratan Murty, Robert Ajemian, and James J DiCarlo. 2020. https://www.cell.com/neuron/fulltext/S0896-6273(20)30605-X Integrative benchmarking to advance neurally mechanistic models of human intelligence . Neuron
2020
-
[27]
Wikimedia Foundation . 2023. https://huggingface.co/datasets/wikimedia/wikipedia Wikimedia Downloads
2023
-
[28]
Ethan Gotlieb Wilcox, Richard Futrell, and Roger Levy. 2024. https://doi.org/10.1162/ling_a_00491 Using Computational Models to Test Syntactic Learnability . Linguistic Inquiry, 55(4):805--848
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.