Recognition: unknown
Spec2Cov: An Agentic Framework for Code Coverage Closure of Digital Hardware Designs
Pith reviewed 2026-05-10 08:10 UTC · model grok-4.3
The pith
Spec2Cov uses an LLM agent to generate and refine test stimulus from hardware design specifications, reaching full code coverage on simpler designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
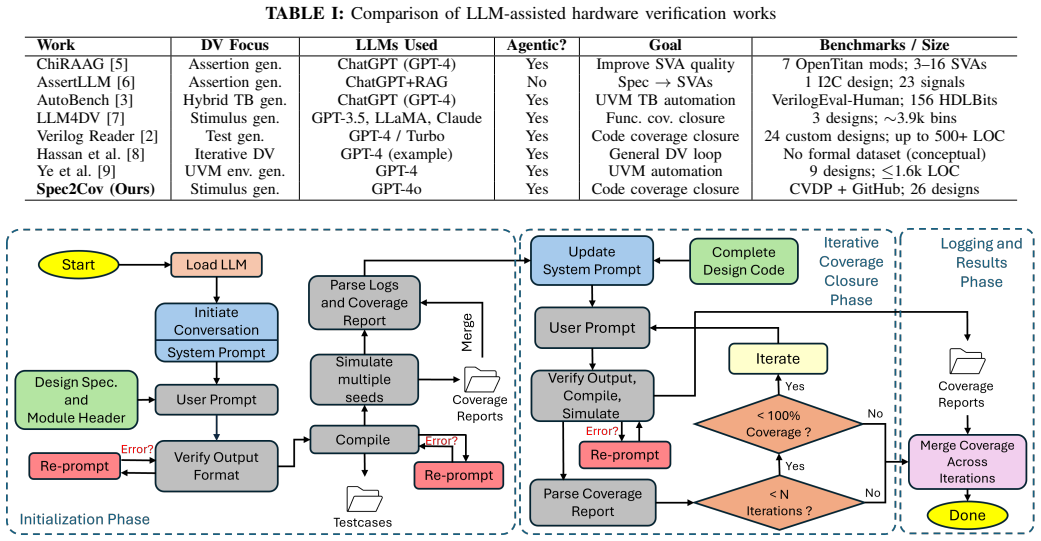
Spec2Cov is an agentic framework that automatically generates test stimulus directly from design specifications by coordinating an LLM with a hardware simulator. It manages compilation and simulation errors, parses coverage reports, and feeds results back for refinement without requiring model fine-tuning. Across 26 designs of varying size and complexity, including problems from the CVDP benchmark suite, the framework achieves 100 percent coverage on simpler designs and up to 49 percent on more complex designs.
What carries the argument
The iterative agentic loop that lets the LLM generate tests, receive coverage and error feedback from the simulator, and refine subsequent stimulus.
If this is right
- Coverage closure shifts from labor-intensive manual test writing to automated iteration driven by simulation feedback.
- The same framework can handle designs ranging from simple to moderately complex without changes to the underlying model.
- Specific coordination features between the LLM and simulator measurably improve results on realistic hardware problems.
- Verification teams could reduce time spent on stimulus creation while still targeting specification alignment.
- The method applies directly to problems in existing benchmark suites such as CVDP.
Where Pith is reading between the lines
- Similar feedback-driven agent loops could be tested on software test generation or mixed-signal verification tasks.
- Larger gains on complex designs may appear once newer LLMs with longer context windows replace the current off-the-shelf model.
- Combining the generated stimulus with formal property checking might address the coverage gaps that remain on harder designs.
- Teams adopting the approach would likely need processes for reviewing and approving the automatically produced tests.
Load-bearing premise
An off-the-shelf LLM can produce test stimulus that meaningfully advances coverage when guided only by coverage reports and error messages, without domain-specific fine-tuning or human repairs to the generated tests.
What would settle it
A run of Spec2Cov on one of the more complex CVDP designs that shows coverage gains no higher than those produced by standard constrained-random testing after the same number of iterations.
Figures



read the original abstract
Hardware verification is one of the most challenging stages of the hardware design process, requiring significant time and resources to ensure a design is fully validated and production-ready. Verification teams aim to maximize design coverage while ensuring correct behavior and alignment with the specification. Coverage closure, which relies on iterative constrained-random and directed testing, is still largely manual and therefore slow and labor-intensive. Recent advances show that the code generation capabilities of Large Language Models (LLMs) can be integrated with external tools to build agentic workflows that autonomously perform hardware design and verification tasks. In this work, we introduce Spec2Cov, an agentic framework that automatically and iteratively generates test stimulus directly from design specifications to accelerate coverage closure. Spec2Cov coordinates interactions between an LLM and a hardware simulator, managing compilation and simulation errors, parsing coverage reports, and feeding results back to the model for refinement. We present features that improve Spec2Cov's effectiveness without additional fine-tuning and evaluate their impact. Across 26 designs of varying size and complexity, including problems from the CVDP benchmark suite, Spec2Cov demonstrates promising performance, achieving 100% coverage on simpler designs and up to 49% on more complex designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Spec2Cov, an agentic framework that uses an off-the-shelf LLM to iteratively generate hardware test stimulus directly from design specifications. The system coordinates with a simulator to manage compilation/simulation errors, parse coverage reports, and feed results back for refinement, with added features to improve effectiveness without fine-tuning. It reports evaluation results across 26 designs of varying size and complexity (including CVDP benchmarks), claiming 100% coverage on simpler designs and up to 49% on more complex ones.
Significance. If the reported coverage results are reproducible and achieved with no human repair or selection of LLM-generated tests, the work would demonstrate a practical, autonomous workflow for accelerating coverage closure in hardware verification. This could meaningfully reduce the manual effort currently required in constrained-random and directed testing, building on existing LLM-tool integration patterns in the field.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central performance claim (100% coverage on simpler designs, up to 49% on complex ones across 26 designs) is stated without any quantitative details on the number of runs per design, variance across runs, failure modes, or the precise definition and measurement of coverage (e.g., line, branch, or functional). This omission prevents verification of the result's reliability and reproducibility.
- [Evaluation] Evaluation section: The autonomy claim—that stimulus is generated and refined using only LLM + simulator feedback, error messages, and coverage reports with no human repair or selective discarding of tests—is load-bearing for the paper's contribution but unsupported by data on intervention rates, raw LLM output success fraction, or post-generation editing. Without this, the weakest assumption (off-the-shelf LLM sufficiency without domain-specific tuning or human fixes) cannot be assessed.
minor comments (2)
- [Evaluation] The description of framework features that improve effectiveness (mentioned in the abstract) would benefit from explicit ablation results or quantitative impact metrics in the evaluation to clarify their contribution.
- [Framework Description] Notation for coverage metrics and simulator interfaces could be standardized with a table or diagram for clarity, especially when describing the feedback loop.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight important areas for improving the clarity, reproducibility, and substantiation of our claims regarding Spec2Cov's performance and autonomy. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central performance claim (100% coverage on simpler designs, up to 49% on complex ones across 26 designs) is stated without any quantitative details on the number of runs per design, variance across runs, failure modes, or the precise definition and measurement of coverage (e.g., line, branch, or functional). This omission prevents verification of the result's reliability and reproducibility.
Authors: We agree that the current presentation of results lacks sufficient methodological detail for full reproducibility. In the revised manuscript, we will expand the Evaluation section (and update the abstract accordingly) to report the number of independent runs per design, any observed variance in coverage outcomes, a discussion of failure modes (e.g., persistent gaps in complex designs due to state-space challenges), and the exact coverage definition used (line and branch coverage as reported by the simulator). These additions will directly address the concerns about reliability assessment. revision: yes
-
Referee: [Evaluation] Evaluation section: The autonomy claim—that stimulus is generated and refined using only LLM + simulator feedback, error messages, and coverage reports with no human repair or selective discarding of tests—is load-bearing for the paper's contribution but unsupported by data on intervention rates, raw LLM output success fraction, or post-generation editing. Without this, the weakest assumption (off-the-shelf LLM sufficiency without domain-specific tuning or human fixes) cannot be assessed.
Authors: We acknowledge the need for quantitative support of the autonomy claim. The Spec2Cov framework is engineered for fully automated operation, with all test generation, error handling, and refinement driven by LLM-simulator interactions and no human repair or test selection in our experiments. In the revised Evaluation section, we will include supporting data such as raw LLM output success rates (e.g., compilable tests on initial generation), iteration counts, and explicit confirmation of zero post-generation editing, drawn from our experimental logs. This will provide the requested evidence for the off-the-shelf LLM approach. revision: yes
Circularity Check
No circularity: purely empirical agentic framework
full rationale
The paper describes an LLM-based agentic workflow for generating test stimulus and reports coverage results from running it on 26 external designs (including CVDP benchmarks) via a hardware simulator. No mathematical derivations, fitted parameters, predictions, or uniqueness theorems are present; all claims rest on observed simulator outputs rather than any internal self-referential definitions or self-citation chains that reduce the result to its inputs by construction. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate syntactically valid and functionally relevant test stimulus from design specifications when given coverage feedback.
Reference graph
Works this paper leans on
-
[1]
Chip-Chat: Chal- lenges and Opportunities in Conversational Hardware Design,
J. Blocklove, S. Garg, R. Karri, and H. Pearce, “Chip-Chat: Chal- lenges and Opportunities in Conversational Hardware Design,” in2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD), Sep. 2023, pp. 1–6
2023
-
[2]
VerilogReader: LLM-Aided Hardware Test Generation,
R. Ma, Y . Yang, Z. Liu, J. Zhang, M. Li, J. Huang, and G. Luo, “VerilogReader: LLM-Aided Hardware Test Generation,” in2024 IEEE LLM Aided Design Workshop (LAD), Jun. 2024, pp. 1–5
2024
-
[3]
Au- toBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design,
R. Qiu, G. L. Zhang, R. Drechsler, U. Schlichtmann, and B. Li, “Au- toBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design,” inProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, ser. MLCAD ’24. New York, NY , USA: Association for Computing Machinery, Sep. 2024, pp. 1–10
2024
-
[4]
LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation,
Z. Zhang, G. Chadwick, H. McNally, Y . Zhao, and R. Mullins, “LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation,” Oct. 2023
2023
-
[5]
ChIRAAG: ChatGPT Informed Rapid and Automated Assertion Gen- eration,
B. Mali, K. Maddala, V . Gupta, S. Reddy, C. Karfa, and R. Karri, “ChIRAAG: ChatGPT Informed Rapid and Automated Assertion Gen- eration,” in2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). Knoxville, TN, USA: IEEE, Jul. 2024, pp. 680–683
2024
-
[6]
AssertLLM: Generating Hardware Verification Assertions from Design Specifications via Multi-LLMs,
W. Fang, M. Li, M. Li, Z. Yan, S. Liu, H. Zhang, and Z. Xie, “AssertLLM: Generating Hardware Verification Assertions from Design Specifications via Multi-LLMs,” in2024 IEEE LLM Aided Design Workshop (LAD), Jun. 2024, pp. 1–1
2024
-
[7]
Illm4dv: Using large language models for hardware test stimuli gener- ation
“Illm4dv: Using large language models for hardware test stimuli gener- ation.”
-
[8]
Prompt. Verify. Repeat. LLMs in the Hardware Verification Cycle,
M. Hassan, M. Nadeem, K. Qayyum, C. K. Jha, and R. Drechsler, “Prompt. Verify. Repeat. LLMs in the Hardware Verification Cycle,” in 2025 IEEE International Conference on Omni-layer Intelligent Systems (COINS), 2025, pp. 1–6
2025
-
[9]
From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification
J. Ye, Y . Hu, K. Xu, D. Pan, Q. Chen, J. Zhou, S. Zhao, X. Fang, X. Wang, N. Guan, and Z. Jiang, “From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification,” 2025. [Online]. Available: https://arxiv.org/abs/2504.19959
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
N. Pinckney, C. Deng, C.-T. Ho, Y .-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Evaluating Large Language Models and Agents on RTL Design and Verification,” 2025. [Online]. Available: https://arxiv.org/abs/2506.14074
-
[11]
Spec2Cov,
Anonymous, “Spec2Cov,” 2025, https://anonymous.4open.science/r/spec2cov
2025
-
[12]
VeriGen: A Large Language Model for Verilog Code Generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “VeriGen: A Large Language Model for Verilog Code Generation,”ACM Transactions on Design Automation of Electronic Systems, p. 3643681, Feb. 2024
2024
-
[13]
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models,
Y . Fu, Y . Zhang, Z. Yu, S. Li, Z. Ye, C. Li, C. Wan, and Y . C. Lin, “GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models,” 2025. [Online]. Available: https://arxiv.org/abs/2309.10730
-
[14]
Calzada, Zahin Ibnat, Mark Tehranipoor, and Farimah Farahmandi
P. E. Calzada, Z. Ibnat, T. Rahman, K. Kandula, D. Lu, S. K. Saha, F. Farahmandi, and M. Tehranipoor, “VerilogDB: The Largest, Highest- Quality Dataset with a Preprocessing Framework for LLM-based RTL Generation,” 2025. [Online]. Available: https://arxiv.org/abs/2507.13369
-
[15]
K. Xu, J. Sun, Y . Hu, X. Fang, W. Shan, X. Wang, and Z. Jiang,MEIC: Re-thinking RTL Debug Automation using LLMs. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi-org.ezproxy1.lib.asu.edu/10.1145/3676536.3676801
-
[16]
UVLLM: An automated universal rtl verification framework using LLMs,
Y . Hu, J. Ye, K. Xu, J. Sun, S. Zhang, X. Jiao, D. Pan, J. Zhou, N. Wang, W. Shan, X. Fang, X. Wang, N. Guan, and Z. Jiang, “UVLLM: An Automated Universal RTL Verification Framework using LLMs,” 2024. [Online]. Available: https://arxiv.org/abs/2411.16238
-
[17]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[18]
vndecorrelator: Verilog implementation of a von Neu- mann decorrelator,
J. Str ¨ombergson, “vndecorrelator: Verilog implementation of a von Neu- mann decorrelator,” https://github.com/secworks/vndecorrelator, 2016
2016
-
[19]
FIFO SystemVerilog Assertion: Syn- chronous FIFO with SystemVerilog Assertions,
A. Vashist, “FIFO SystemVerilog Assertion: Syn- chronous FIFO with SystemVerilog Assertions,” https://github.com/avashist003/FIFO SystemVerilog Assertion, 2020
2020
-
[20]
uart: Verilog implementation of a simple UART core,
J. Str ¨ombergson, “uart: Verilog implementation of a simple UART core,” https://github.com/secworks/uart, 2014
2014
-
[21]
sha1: Verilog implementation of the SHA-1 hash function,
J. Str ¨ombergson, “sha1: Verilog implementation of the SHA-1 hash function,” https://github.com/secworks/sha1, 2014
2014
-
[22]
chacha: Verilog implementation of the ChaCha stream cipher,
J. Str ¨ombergson, “chacha: Verilog implementation of the ChaCha stream cipher,” https://github.com/secworks/chacha, 2014
2014
-
[23]
trng: True Random Number Generator core imple- mented in Verilog,
J. Str ¨ombergson, “trng: True Random Number Generator core imple- mented in Verilog,” https://github.com/secworks/trng, 2014
2014
-
[24]
SD-card-controller: SD/SDHC card controller for Wish- bone bus,
M. Czerski, “SD-card-controller: SD/SDHC card controller for Wish- bone bus,” https://github.com/mczerski/SD-card-controller, 2013
2013
-
[25]
DSP Slice: Floating Point Units,
S. Mehta, “DSP Slice: Floating Point Units,” https://github.com/samidhm/DSP Slice/tree/main/Floating Point Units, 2020
2020
-
[26]
tpu like design: TPU-like design with pooling unit,
V . Patel and UT-LCA, “tpu like design: TPU-like design with pooling unit,” https://github.com/UT- LCA/tpu like design/tree/master/design ws vedant, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.