Recognition: unknown
Adapting in the Dark: Efficient and Stable Test-Time Adaptation for Black-Box Models
Pith reviewed 2026-05-10 08:50 UTC · model grok-4.3
The pith
BETA adapts black-box models at test time using a local steering model and regularization techniques to achieve accuracy improvements without additional API queries or high latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
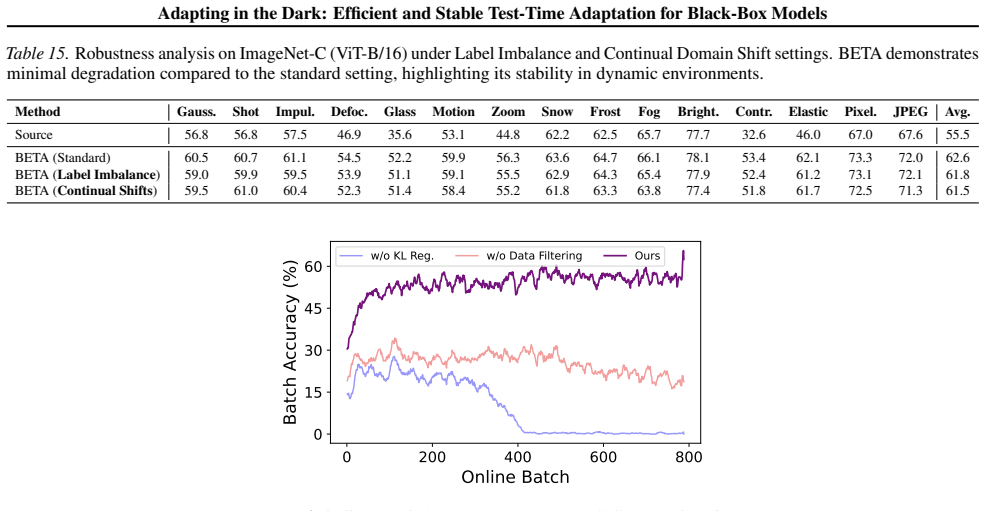
BETA achieves a +7.1% accuracy gain on ViT-B/16 and +3.4% on CLIP on ImageNet-C, surpassing strong white-box and gray-box methods including TENT and TPT; on a commercial API it achieves comparable performance to ZOO at 250x lower cost while maintaining real-time inference speed.
Load-bearing premise
The lightweight local white-box steering model combined with prediction harmonization, consistency regularization, and prompt learning-oriented filtering creates a tractable and stable gradient pathway for unsupervised black-box TTA without requiring additional API calls.
Figures





read the original abstract
Test-Time Adaptation (TTA) for black-box models accessible only via APIs remains a largely unexplored challenge. Existing approaches such as post-hoc output refinement offer limited adaptive capacity, while Zeroth-Order Optimization (ZOO) enables input-space adaptation but faces high query costs and optimization challenges in the unsupervised TTA setting. We introduce BETA (Black-box Efficient Test-time Adaptation), a framework that addresses these limitations by employing a lightweight, local white-box steering model to create a tractable gradient pathway. Through a prediction harmonization technique combined with consistency regularization and prompt learning-oriented filtering, BETA enables stable adaptation with no additional API calls and negligible latency beyond standard inference. On ImageNet-C, BETA achieves a +7.1% accuracy gain on ViT-B/16 and +3.4% on CLIP, surpassing strong white-box and gray-box methods including TENT and TPT. On a commercial API, BETA achieves comparable performance to ZOO at 250x lower cost while maintaining real-time inference speed, establishing it as a practical and efficient solution for real-world black-box TTA.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity detected
full rationale
The BETA framework introduces independent components—a lightweight local white-box steering model, prediction harmonization, consistency regularization, and prompt-oriented filtering—to enable black-box TTA without extra API calls. These are not shown to reduce by construction to prior fitted quantities, self-referential equations, or load-bearing self-citations; the central claim rests on the new gradient pathway and is supported by external empirical benchmarks (ImageNet-C gains, commercial API comparison) rather than tautological renaming or ansatz smuggling. The derivation chain remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
URL https://api.semanticscholar. org/CorpusID:246015836. Chen, G., Niu, S., Chen, D., Yang, J., Zhang, Z., Tan, M., Wu, P., and Shen, Z. Zerosiam: An efficient asymmetry for test-time entropy optimization without collapse. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=x6jHZYhnhL. Dosovit...
work page internal anchor Pith review arXiv 2026
-
[2]
cc/paper_files/paper/2021/file/ 1415fe9fea0fa1e45dddcff5682239a0-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 1415fe9fea0fa1e45dddcff5682239a0-Paper. pdf. Karmanov, A., Guan, D., Lu, S., El Saddik, A., and Xing, E. Efficient test-time adaptation of vision-language mod- els.The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. Kawahara, J., Daneshvar, S., Argenziano, G., and Hamar...
2021
-
[3]
URL https://openreview.net/forum? id=V3zobHnS61. Liu, S., Kailkhura, B., Chen, P.-Y ., Ting, P., Chang, S., and Amini, L. Zeroth-order stochastic variance reduction for nonconvex optimization.Advances in neural information processing systems, 31, 2018. Liu, S., Chen, P.-Y ., Kailkhura, B., Zhang, G., Hero III, A. O., and Varshney, P. K. A primer on zeroth...
-
[4]
Gemini: A Family of Highly Capable Multimodal Models
URL https://openreview.net/forum? id=qz1Vx1v9iK. Oh, C., Hwang, H., Lee, H.-y., Lim, Y ., Jung, G., Jung, J., Choi, H., and Song, K. Blackvip: Black-box visual prompting for robust transfer learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pp. 24224–24235, June 2023. Ouali, Y ., Bulat, A., Martinez, B....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
URL https://openreview.net/forum? id=UwtXDttgsE. Xiao, Z., Yan, S., Hong, J., Cai, J., Jiang, X., Hu, Y ., Shen, J., Wang, Q., and Snoek, C. G. Dynaprompt: Dynamic test-time prompt tuning. InThe Thirteenth International Conference on Learning Representations, 2025. Zhang, C., Stepputtis, S., Sycara, K. P., and Xie, Y . Dual prototype evolving for test-tim...
work page internal anchor Pith review arXiv 2025
-
[6]
Zhou, L., Ye, M., Li, S., Li, N., Zhu, X., Deng, L., Liu, H., and Lei, Z
URL https://openreview.net/forum? id=kIP0duasBb. Zhou, L., Ye, M., Li, S., Li, N., Zhu, X., Deng, L., Liu, H., and Lei, Z. Bayesian test-time adaptation for vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 29999–30009, 2025. 13 Adapting in the Dark: Efficient and Stable Test-Time Adaptation for Black-Bo...
2025
-
[7]
Raw Logits ( z):The pre-activation output vector z∈R C, where values are unbounded ( −∞< z i <∞ ) and unnormalized
-
[8]
Softmax Probability Vector (p):The normalized output distribution obtained via the softmax function σ(·), such that p=σ(z)∈[0,1] C withP i pi = 1
-
[9]
dark knowledge
Top-1 Hard Prediction ( ˆy):A single scalar value representing the class index with the highest confidence, ˆy= arg maxi pi, often accompanied by a single confidence score. Real-World API Protocols.To determine the most realistic setting for black-box adaptation, we analyze standard commercial Machine Learning APIs (e.g., OpenAI (Hurst et al., 2024), Clar...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.