Causal Bootstrapped Alignment for Unsupervised Video-Based Visible-Infrared Person Re-Identification
Pith reviewed 2026-05-10 08:26 UTC · model grok-4.3
The pith
Causal Bootstrapped Alignment learns reliable identity features from unlabeled video tracklets for visible-infrared re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
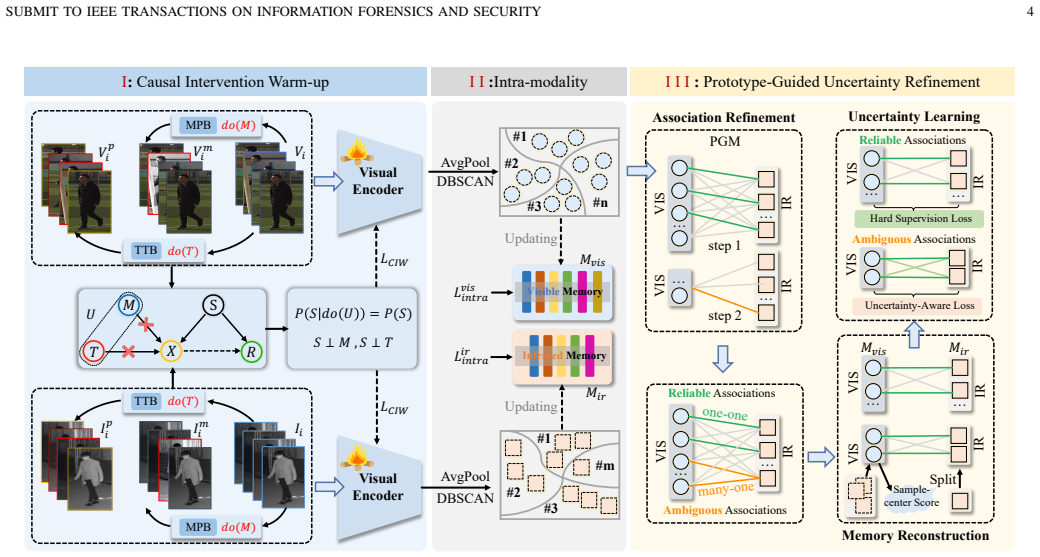
The Causal Bootstrapped Alignment framework exploits inherent video priors through two stages. Causal Intervention Warm-up performs sequence-level causal interventions that leverage temporal identity consistency and cross-modality identity consistency to suppress modality- and motion-induced spurious correlations while preserving identity-relevant semantics. Prototype-Guided Uncertainty Refinement then follows a coarse-to-fine strategy that resolves cross-modality granularity mismatch by reorganizing under-clustered infrared representations under the guidance of reliable visible prototypes with uncertainty-aware supervision. Together these steps yield cleaner representations that improve the
What carries the argument
Causal Bootstrapped Alignment framework, whose core mechanisms are sequence-level causal interventions that clean representations using video consistency priors and prototype-guided uncertainty refinement that aligns modalities despite initial clustering imbalance.
If this is right
- Unsupervised video-based visible-infrared re-identification becomes feasible without cross-modality annotations.
- Pseudo-label reliability rises because intra-modality identity confusion and granularity imbalance are reduced.
- Cross-modality alignment succeeds even when initial clusters are imbalanced between visible and infrared modalities.
- All-day surveillance systems can scale to new camera networks without incurring expensive labeling costs.
- The same sequence-level priors can be reused for other video multi-modal unsupervised tasks.
Where Pith is reading between the lines
- The same causal-intervention step could be tested on single-modality video re-identification to isolate how much the cross-modality consistency term contributes.
- If the visible prototypes prove more reliable than infrared ones, the framework may naturally favor one modality as the anchor in future extensions.
- Applying the uncertainty-aware supervision to other granularity-mismatch problems, such as day-night object detection, would test whether the refinement stage generalizes beyond person re-identification.
Load-bearing premise
That temporal identity consistency and cross-modality identity consistency in unlabeled video tracklets are strong enough to guide causal interventions that reliably separate identity semantics from modality and motion biases.
What would settle it
Running CBA on the HITSZ-VCM benchmark and finding no meaningful gain in re-identification accuracy or reduction in visible-infrared clustering imbalance compared with directly extended image-based unsupervised baselines would show the interventions failed to remove the spurious correlations.
Figures







read the original abstract
VVI-ReID is a critical technique for all-day surveillance, where temporal information provides additional cues beyond static images. However, existing approaches rely heavily on fully supervised learning with expensive cross-modality annotations, limiting scalability. To address this issue, we investigate Unsupervised Learning for VVI-ReID (USL-VVI-ReID), which learns identity-discriminative representations directly from unlabeled video tracklets. Directly extending image-based USL-VI-ReID methods to this setting with generic pretrained encoders leads to suboptimal performance. Such encoders suffer from weak identity discrimination and strong modality bias, resulting in severe intra-modality identity confusion and pronounced clustering granularity imbalance between visible and infrared modalities. These issues jointly degrade pseudo-label reliability and hinder effective cross-modality alignment. To address these challenges, we propose a Causal Bootstrapped Alignment (CBA) framework that explicitly exploits inherent video priors. First, we introduce Causal Intervention Warm-up (CIW), which performs sequence-level causal interventions by leveraging temporal identity consistency and cross-modality identity consistency to suppress modality- and motion-induced spurious correlations while preserving identity-relevant semantics, yielding cleaner representations for unsupervised clustering. Second, we propose Prototype-Guided Uncertainty Refinement (PGUR), which employs a coarse-to-fine alignment strategy to resolve cross-modality granularity mismatch, reorganizing under-clustered infrared representations under the guidance of reliable visible prototypes with uncertainty-aware supervision. Extensive experiments on the HITSZ-VCM and BUPTCampus benchmarks demonstrate that CBA significantly outperforms existing USL-VI-ReID methods when extended to the USL-VVI-ReID setting.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal identity consistency and cross-modality identity consistency hold sufficiently in unlabeled video tracklets to enable causal interventions that remove spurious correlations.
Reference graph
Works this paper leans on
-
[1]
X. Lin, J. Li, Z. Ma, H. Li, S. Li, K. Xu, G. Lu, and D. Zhang, “Learning modal-invariant and temporal-memory for video-based visible-infrared person re-identification,” inCVPR, 2022, pp. 20 973–20 982. SUBMIT TO IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY 13
work page 2022
-
[2]
Video-level language-driven video-based visible-infrared person re-identification,
S. Li, J. Leng, C. Kuang, M. Tan, and X. Gao, “Video-level language-driven video-based visible-infrared person re-identification,” IEEE Trans. Inf. Forensics Security, 2025
work page 2025
-
[3]
H. Li, M. Liu, Z. Hu, F. Nie, and Z. Yu, “Intermediary-guided bidi- rectional spatial-temporal aggregation network for video-based visible- infrared person re-identification,”IEEE Trans. Circuits Syst. Video Technol., 2023
work page 2023
-
[4]
Video-based visible- infrared person re-identification with auxiliary samples,
Y . Du, C. Lei, Z. Zhao, Y . Dong, and F. Su, “Video-based visible- infrared person re-identification with auxiliary samples,”IEEE Trans. Inf. Forensics Security, vol. 19, pp. 1313–1325, 2023
work page 2023
-
[5]
Y . Yang, S. Li, J. Ye, N. Dong, F. Li, and H. Li, “Dinov2-driven gait representation learning for video-based visible–infrared person re- identification,” inACM MM, 2025, pp. 8283–8292
work page 2025
-
[6]
Dual-space video person re-identification,
J. Leng, C. Kuang, S. Li, J. Gan, H. Chen, and X. Gao, “Dual-space video person re-identification,”Int. J. Comput. Vis., vol. 133, no. 6, pp. 3667–3688, 2025
work page 2025
-
[7]
S. Li, F. Li, J. Li, H. Li, B. Zhang, D. Tao, and X. Gao, “Logical relation inference and multiview information interaction for domain adaptation person re-identification,”IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 10, pp. 14 770–14 782, 2023
work page 2023
-
[8]
Hierarchical prompt learning for image- and text-based person re-identification,
L. Zhou, S. Li, N. Dong, Y . Tai, Y . Zhang, and H. Li, “Hierarchical prompt learning for image- and text-based person re-identification,” in AAAI, 2026, accepted
work page 2026
-
[9]
Y . Wang, G. Qi, S. Li, Y . Chai, and H. Li, “Body part-level domain alignment for domain-adaptive person re-identification with transformer framework,”IEEE Trans. Inf. Forensics Security, vol. 17, pp. 3321–3334, 2022
work page 2022
-
[10]
B. Yang, M. Ye, J. Chen, and Z. Wu, “Augmented dual-contrastive aggregation learning for unsupervised visible-infrared person re- identification,” inACM MM, 2022, pp. 2843–2851
work page 2022
-
[11]
Z. Wu and M. Ye, “Unsupervised visible-infrared person re-identification via progressive graph matching and alternate learning,” inCVPR, 2023, pp. 9548–9558
work page 2023
-
[12]
B. Yang, J. Chen, and M. Ye, “Towards grand unified representation learning for unsupervised visible-infrared person re-identification,” in ICCV, 2023, pp. 11 069–11 079
work page 2023
-
[13]
D. Cheng, X. Huang, N. Wang, L. He, Z. Li, and X. Gao, “Unsupervised visible-infrared person reid by collaborative learning with neighbor- guided label refinement,” inACM MM, 2023, pp. 7085–7093
work page 2023
-
[14]
X. Teng, L. Lan, D. Chen, K. Xu, and N. Yin, “Relieving universal label noise for unsupervised visible-infrared person re-identification by inferring from neighbors,” inAAAI, vol. 39, no. 7, 2025, pp. 7356–7364
work page 2025
-
[15]
X. Yin, J. Shi, Y . Zhang, Y . Lu, Z. Zhang, Y . Xie, and Y . Qu, “Robust pseudo-label learning with neighbor relation for unsupervised visible- infrared person re-identification,” inACM MM, 2024, pp. 2242–2251
work page 2024
-
[16]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML. PMLR, 2021, pp. 8748–8763
work page 2021
-
[17]
Clip-driven fine-grained text- image person re-identification,
S. Yan, N. Dong, L. Zhang, and J. Tang, “Clip-driven fine-grained text- image person re-identification,”IEEE Trans. Image Process., vol. 32, pp. 6032–6046, 2023
work page 2023
-
[18]
Clip-driven semantic discovery network for visible-infrared person re-identification,
X. Yu, N. Dong, L. Zhu, H. Peng, and D. Tao, “Clip-driven semantic discovery network for visible-infrared person re-identification,”IEEE Trans. Multimedia, 2025
work page 2025
-
[19]
N. Dong, S. Yan, L. Zhang, and J. Tang, “Diverse semantics- guided feature alignment and decoupling for visible-infrared person re- identification,”IEEE Trans. Inf. Forensics Security, vol. 20, pp. 12 245– 12 259, 2025
work page 2025
-
[20]
Boosting temporal sentence grounding via causal inference,
K. Tang, L. He, J. Dang, and X. Gao, “Boosting temporal sentence grounding via causal inference,” inACM MM, 2025, pp. 8701–8710
work page 2025
-
[21]
Causality-inspired invariant representation learning for text-based person retrieval,
Y . Liu, G. Qin, H. Chen, Z. Cheng, and X. Yang, “Causality-inspired invariant representation learning for text-based person retrieval,” in AAAI, vol. 38, no. 12, 2024, pp. 14 052–14 060
work page 2024
-
[22]
Causality inspired representation learning for domain generalization,
F. Lv, J. Liang, S. Li, B. Zang, C. H. Liu, Z. Wang, and D. Liu, “Causality inspired representation learning for domain generalization,” inCVPR, 2022, pp. 8046–8056
work page 2022
-
[23]
Deep learning for person re-identification: A survey and outlook,
M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. H. Hoi, “Deep learning for person re-identification: A survey and outlook,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 6, pp. 2872–2893, 2021
work page 2021
-
[24]
Dynamic dual-attentive aggregation learning for visible-infrared person re- identification,
M. Ye, J. Shen, D. J. Crandall, L. Shao, and J. Luo, “Dynamic dual-attentive aggregation learning for visible-infrared person re- identification,” inECCV, 2020, pp. 229–247
work page 2020
-
[25]
Discover cross-modality nuances for visible-infrared person re- identification,
Q. Wu, P. Dai, J. Chen, C.-W. Lin, Y . Wu, F. Huang, B. Zhong, and R. Ji, “Discover cross-modality nuances for visible-infrared person re- identification,” inCVPR, 2021, pp. 4330–4339
work page 2021
-
[26]
Shape-centered repre- sentation learning for visible-infrared person re-identification,
S. Li, J. Leng, J. Gan, M. Mo, and X. Gao, “Shape-centered repre- sentation learning for visible-infrared person re-identification,”Pattern Recognition, p. 111756, 2025
work page 2025
-
[27]
Y . Feng, F. Chen, J. Yu, Y . Ji, F. Wu, T. Liu, S. Liu, X.-Y . Jing, and J. Luo, “Cross-modality spatial-temporal transformer for video-based visible-infrared person re-identification,”IEEE Trans. Multimedia, 2024
work page 2024
-
[28]
C. Zhou, J. Li, H. Li, G. Lu, Y . Xu, and M. Zhang, “Video-based visible- infrared person re-identification via style disturbance defense and dual interaction,” inACM MM, 2023, pp. 46–55
work page 2023
-
[29]
C. Zhou, Y . Zhou, T. Ren, H. Li, J. Li, and G. Lu, “Hierarchical disturbance and group inference for video-based visible-infrared person re-identification,”Information Fusion, vol. 117, p. 102882, 2025
work page 2025
-
[30]
C. Yu, X. Liu, P. Zhang, and H. Lu, “X-reid: Multi-granularity informa- tion interaction for video-based visible-infrared person re-identification,” inAAAI, 2025
work page 2025
-
[31]
Stepwise metric promotion for unsuper- vised video person re-identification,
Z. Liu, D. Wang, and H. Lu, “Stepwise metric promotion for unsuper- vised video person re-identification,” inICCV, 2017, pp. 2429–2438
work page 2017
-
[32]
Robust anchor embedding for unsupervised video person re-identification in the wild,
M. Ye, X. Lan, and P. C. Yuen, “Robust anchor embedding for unsupervised video person re-identification in the wild,” inECCV, 2018, pp. 170–186
work page 2018
-
[33]
Dynamic graph co- matching for unsupervised video-based person re-identification,
M. Ye, J. Li, A. J. Ma, L. Zheng, and P. C. Yuen, “Dynamic graph co- matching for unsupervised video-based person re-identification,”IEEE Trans. Image Process., vol. 28, no. 6, pp. 2976–2990, 2019
work page 2019
-
[34]
Exploiting global camera network constraints for unsupervised video person re-identification,
X. Wang, R. Panda, M. Liu, Y . Wang, and A. K. Roy-Chowdhury, “Exploiting global camera network constraints for unsupervised video person re-identification,”IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 10, pp. 4020–4030, 2020
work page 2020
-
[35]
Unsupervised person re-identification by deep learning tracklet association,
M. Li, X. Zhu, and S. Gong, “Unsupervised person re-identification by deep learning tracklet association,” inECCV, 2018, pp. 737–753
work page 2018
-
[36]
Unsupervised tracklet person re- identification,
M. Li, X. Zhu, and S. Gong, “Unsupervised tracklet person re- identification,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 7, pp. 1770–1782, 2019
work page 2019
-
[37]
Person re-identification by unsupervised video matching,
X. Ma, X. Zhu, S. Gong, X. Xie, J. Hu, K.-M. Lam, and Y . Zhong, “Person re-identification by unsupervised video matching,”Pattern Recognition, vol. 65, pp. 197–210, 2017
work page 2017
-
[38]
P. Xie, X. Xu, Z. Wang, and T. Yamasaki, “Sampling and re- weighting: Towards diverse frame-aware unsupervised video person re- identification,”IEEE Trans. Multimedia, vol. 24, pp. 4250–4261, 2022
work page 2022
-
[39]
Anchor association learning for unsupervised video person re-identification,
S. Zeng, X. Wang, M. Liu, Q. Liu, and Y . Wang, “Anchor association learning for unsupervised video person re-identification,”IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 1, pp. 1013–1024, 2022
work page 2022
-
[40]
Unsupervised person re- identification: Clustering and fine-tuning,
H. Fan, L. Zheng, C. Yan, and Y . Yang, “Unsupervised person re- identification: Clustering and fine-tuning,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 14, no. 4, pp. 1–18, 2018
work page 2018
-
[41]
Robust duality learning for unsupervised visible-infrared person re-identification,
Y . Li, Y . Sun, Y . Qin, D. Peng, X. Peng, and P. Hu, “Robust duality learning for unsupervised visible-infrared person re-identification,”IEEE Trans. Inf. Forensics Security, 2025
work page 2025
-
[42]
Multi-memory matching for unsupervised visible-infrared person re- identification,
J. Shi, X. Yin, Y . Chen, Y . Zhang, Z. Zhang, Y . Xie, and Y . Qu, “Multi-memory matching for unsupervised visible-infrared person re- identification,” inECCV. Springer, 2024, pp. 456–474
work page 2024
-
[43]
R. Xi, Z. Fu, N. Huang, X. Zhao, Q. Zhang, and J. Han, “Csanet: Cross-modality self-paced association network for unsupervised visible- infrared person re-identification,”IEEE Trans. Inf. Forensics Security, 2025
work page 2025
-
[44]
M. Ye, Z. Wu, and B. Du, “Dual-level matching with outlier filtering for unsupervised visible-infrared person re-identification,”IEEE Trans. Pattern Anal. Mach. Intell., 2025
work page 2025
-
[45]
Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification,
B. Yang, J. Chen, and M. Ye, “Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification,” inCVPR, 2024, pp. 16 870–16 879
work page 2024
-
[46]
Unveiling the power of clip in unsupervised visible-infrared person re-identification,
Z. Chen, Z. Zhang, X. Tan, Y . Qu, and Y . Xie, “Unveiling the power of clip in unsupervised visible-infrared person re-identification,” inACM MM, 2023, pp. 3667–3675
work page 2023
- [47]
-
[48]
On causal and anticausal learning,
B. Sch ¨olkopf, D. Janzing, J. Peters, E. Sgouritsa, K. Zhang, and J. Mooij, “On causal and anticausal learning,”ICML, 2012
work page 2012
-
[49]
Arbitrary style transfer in real-time with adaptive instance normalization,
X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” inICCV, 2017, pp. 1501–1510
work page 2017
-
[50]
Channel augmented joint learning for visible-infrared recognition,
M. Ye, W. Ruan, B. Du, and M. Z. Shou, “Channel augmented joint learning for visible-infrared recognition,” inICCV, 2021, pp. 13 567– 13 576
work page 2021
-
[51]
Fa-net: A feature alignment network for video-based visible-infrared person re- identification,
X. Yang, W. Dong, X. Wang, D. Cheng, and N. Wang, “Fa-net: A feature alignment network for video-based visible-infrared person re- identification,”IEEE Trans. Image Process., 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.