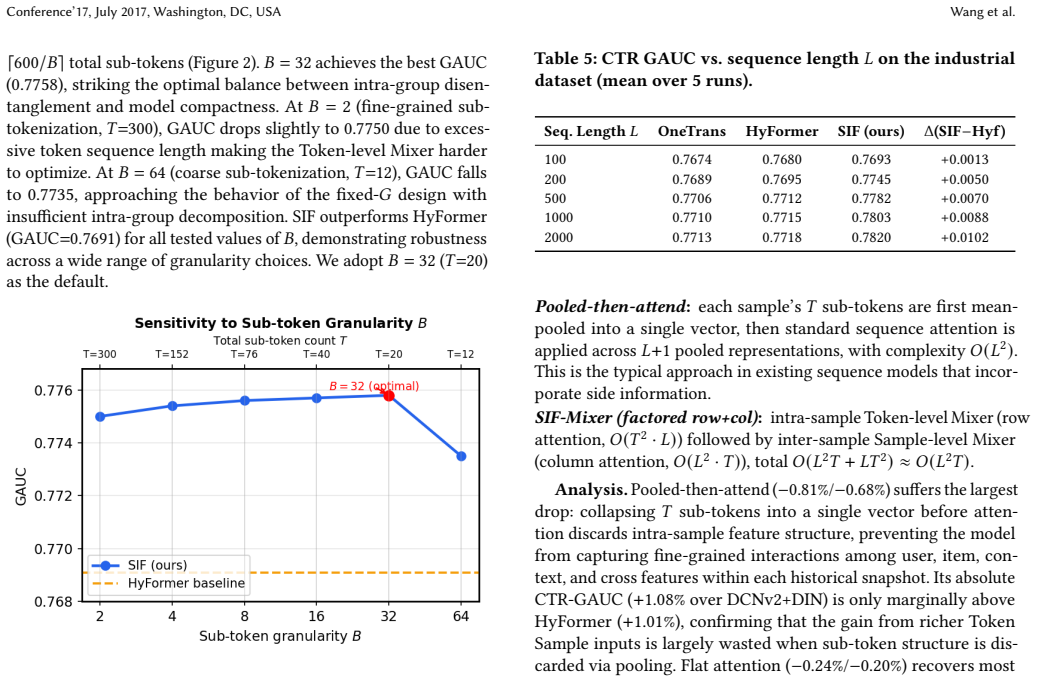
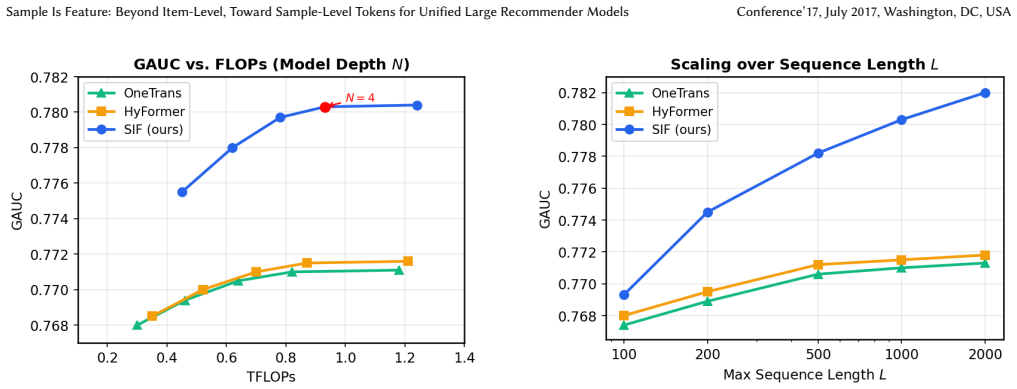
Recognition: unknown
Sample Is Feature: Beyond Item-Level, Toward Sample-Level Tokens for Unified Large Recommender Models
Pith reviewed 2026-05-10 08:12 UTC · model grok-4.3
The pith
Encoding each full historical sample as a token unifies sequence modeling and feature interaction in large recommenders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SIF encodes each historical Raw Sample directly into the sequence token, maximally preserving sample information while simultaneously resolving the heterogeneity between sequential and non-sequential features. The Sample Tokenizer applies hierarchical group-adaptive quantization to turn each raw sample into a Token Sample that carries full context. The SIF-Mixer then conducts deep feature interaction through token-level and sample-level mixing over these homogeneous representations.
What carries the argument
SIF with its Sample Tokenizer (using hierarchical group-adaptive quantization to compress raw samples into uniform tokens) and SIF-Mixer (performing token-level and sample-level mixing for homogeneous interactions).
If this is right
- Complete sample-level context, including time-varying features, becomes available inside the sequence without truncation.
- Sequential and non-sequential features can be processed together in one homogeneous representation, allowing the transformer to use its full capacity.
- Sample-information scaling and model-capacity scaling can be combined inside a single backbone rather than handled separately.
- The resulting architecture has been shown to deliver measurable gains on large-scale production data.
Where Pith is reading between the lines
- The same sample-to-token conversion could be tested in session-based or time-series recommendation tasks where full context per event matters.
- Reducing the need for separate feature pipelines might simplify model maintenance in production recommenders.
- Extending the mixing layers to include cross-sample dependencies across longer histories could be a direct next step.
Load-bearing premise
The hierarchical quantization step can shrink entire historical samples into tokens while retaining enough detail for the downstream model to outperform partial-encoding baselines.
What would settle it
Run an ablation on an industrial dataset that includes time-varying sample features: compare ranking metrics of SIF against an item-level token baseline, checking whether removing the full-sample quantization or the sample-level mixing step closes the reported performance gap.
Figures

read the original abstract
Scaling industrial recommender models has followed two parallel paradigms: \textbf{sample information scaling} -- enriching the information content of each training sample through deeper and longer behavior sequences -- and \textbf{model capacity scaling} -- unifying sequence modeling and feature interaction within a single Transformer backbone. However, these two paradigms still face two structural limitations. Firstly, sample information scaling methods encode only a subset of each historical interaction into the sequence token, leaving the majority of the original sample context unexploited and precluding the modeling of sample-level, time-varying features. Secondly, model capacity scaling methods are inherently constrained by the structural heterogeneity between sequential and non-sequential features, preventing the model from fully realizing its representational capacity. To address these issues, we propose \textbf{SIF} (\emph{Sample Is Feature}), which encodes each historical Raw Sample directly into the sequence token -- maximally preserving sample information while simultaneously resolving the heterogeneity between sequential and non-sequential features. SIF consists of two key components. The \textbf{Sample Tokenizer} quantizes each historical Raw Sample into a Token Sample via hierarchical group-adaptive quantization (HGAQ), enabling full sample-level context to be incorporated into the sequence efficiently. The \textbf{SIF-Mixer} then performs deep feature interaction over the homogeneous sample representations via token-level and sample-level mixing, fully unleashing the model's representational capacity. Extensive experiments on a large-scale industrial dataset validate SIF's effectiveness, and we have successfully deployed SIF on the Meituan food delivery platform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SIF (Sample Is Feature) to unify sample information scaling and model capacity scaling in large recommender systems. It introduces a Sample Tokenizer that uses hierarchical group-adaptive quantization (HGAQ) to encode each full historical raw sample directly into a sequence token, aiming to maximally preserve sample-level context including time-varying features, and a SIF-Mixer that performs token-level and sample-level mixing over the resulting homogeneous representations to resolve sequential/non-sequential heterogeneity. The authors claim this overcomes prior limitations where only subsets of samples were encoded and feature heterogeneity constrained Transformer capacity, with validation via extensive experiments on a large-scale industrial dataset and successful deployment on the Meituan food delivery platform.
Significance. If the empirical claims hold, SIF could meaningfully advance unified large recommender architectures by enabling fuller exploitation of per-sample context within a single backbone, potentially improving accuracy on industrial tasks with rich, time-varying user behavior data. The approach of treating entire samples as tokens rather than item-level subsets is a direct response to two parallel scaling paradigms and merits attention if supported by rigorous ablations and information-preservation analysis.
major comments (3)
- [Abstract] Abstract: The manuscript states that 'extensive experiments on a large-scale industrial dataset validate SIF's effectiveness' and reports a successful deployment, yet supplies no quantitative metrics, baselines, ablation results, implementation details, or statistical significance tests. This leaves the central empirical claims unsupported and prevents assessment of whether HGAQ and SIF-Mixer deliver the promised gains over item-level methods.
- [Sample Tokenizer / HGAQ] Sample Tokenizer and HGAQ description: The claim that HGAQ 'enables full sample-level context to be incorporated into the sequence efficiently' and 'maximally preserv[es] sample information' is load-bearing for the 'beyond item-level' advantage, but the text provides no reconstruction error, mutual information bounds, or ablation isolating quantization loss from the Mixer. Without such analysis, it is unclear whether time-varying non-sequential features survive quantization or whether the method collapses to existing item-level encodings.
- [SIF-Mixer] SIF-Mixer: The assertion that token-level and sample-level mixing 'fully unleashes the model's representational capacity' and resolves heterogeneity requires concrete comparisons (e.g., against standard feature-interaction modules or heterogeneous Transformers) and ablations showing incremental benefit; none are referenced or quantified in the provided text.
minor comments (1)
- [Abstract / Introduction] The title and abstract introduce 'Token Sample' and 'SIF-Mixer' without a concise definition or diagram reference on first use, which may hinder readability for readers unfamiliar with the architecture.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript and providing these valuable comments. We have carefully considered each point and provide our responses below. Where the comments identify areas for improvement, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states that 'extensive experiments on a large-scale industrial dataset validate SIF's effectiveness' and reports a successful deployment, yet supplies no quantitative metrics, baselines, ablation results, implementation details, or statistical significance tests. This leaves the central empirical claims unsupported and prevents assessment of whether HGAQ and SIF-Mixer deliver the promised gains over item-level methods.
Authors: We agree that the abstract, as a concise summary, omits specific numbers. The full manuscript includes a detailed experimental section with quantitative metrics, baseline comparisons, ablation studies, implementation details, and deployment results on the Meituan platform. We will revise the abstract to incorporate key performance metrics and statistical significance, and expand references to these results in the main text. revision: yes
-
Referee: [Sample Tokenizer / HGAQ] Sample Tokenizer and HGAQ description: The claim that HGAQ 'enables full sample-level context to be incorporated into the sequence efficiently' and 'maximally preserv[es] sample information' is load-bearing for the 'beyond item-level' advantage, but the text provides no reconstruction error, mutual information bounds, or ablation isolating quantization loss from the Mixer. Without such analysis, it is unclear whether time-varying non-sequential features survive quantization or whether the method collapses to existing item-level encodings.
Authors: We thank the referee for this observation on the need for direct evidence of information preservation. The current manuscript supports the HGAQ benefits via end-to-end performance. In revision, we will add reconstruction error metrics across feature types, mutual information analysis for original vs. tokenized samples, and an ablation isolating quantization effects from the Mixer to demonstrate preservation of time-varying features. revision: yes
-
Referee: [SIF-Mixer] SIF-Mixer: The assertion that token-level and sample-level mixing 'fully unleashes the model's representational capacity' and resolves heterogeneity requires concrete comparisons (e.g., against standard feature-interaction modules or heterogeneous Transformers) and ablations showing incremental benefit; none are referenced or quantified in the provided text.
Authors: We appreciate the call for targeted comparisons. The manuscript evaluates SIF-Mixer through its role in overall gains. We will revise to include explicit comparisons against standard feature-interaction modules and heterogeneous Transformers, plus ablations quantifying the incremental benefits of the token-level and sample-level mixing components. revision: yes
Circularity Check
No significant circularity; proposal introduces independent architectural components
full rationale
The paper proposes a new SIF architecture consisting of a Sample Tokenizer (using HGAQ quantization) and SIF-Mixer for handling sample-level tokens in recommenders. No derivation step reduces a claimed prediction or result to a fitted parameter, self-citation, or input by construction. Claims about preserving sample information and resolving heterogeneity are presented as design goals supported by new components and industrial experiments, without tautological equations or load-bearing self-citations. This is self-contained against external benchmarks as a standard novel architecture paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- Group sizes and quantization levels in HGAQ
axioms (1)
- domain assumption Hierarchical group-adaptive quantization preserves sufficient sample-level context for effective modeling
invented entities (2)
-
Token Sample
no independent evidence
-
SIF-Mixer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normaliza- tion. arXiv:1607.06450 [stat.ML]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[3]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. 2023. TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3785–3794
2023
-
[4]
Qiwei Chen, Changhua Pei, Shanshan Lv, Chao Li, Junfeng Ge, and Wenwu Ou
-
[5]
End-to-end user behavior retrieval in click-through rateprediction model. arXiv preprint arXiv:2108.04468(2021)
- [6]
-
[7]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[8]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learning vector-quantized item representation for transferable sequential recommenders. InProceedings of the ACM Web Conference 2023. 1162–1171
2023
- [9]
- [10]
-
[11]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. InProc. Int. Conf. on Learning Representations (ICLR)
2015
-
[12]
Xinchun Li, Ning Zhang, Qianqian Yang, Fei Teng, Wenlin Zhao, Huizhi Yang, Heng Shi, Linlan Chen, Yixin Wu, Zhen Wang, et al. 2026. IAT: Instance-As-Token Compression for Historical User Sequence Modeling in Industrial Recommender Systems.arXiv preprint arXiv:2604.08933(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Qijiong Liu, Hengchang Hu, Jiahao Wu, Jieming Zhu, Min-Yen Kan, and Xiao- Ming Wu. 2024. Discrete semantic tokenization for deep ctr prediction. InCom- panion Proceedings of the ACM Web Conference 2024. 919–922
2024
-
[14]
Yimin Lv, Shuli Wang, Beihong Jin, Yisong Yu, Yapeng Zhang, Jian Dong, Yongkang Wang, Xingxing Wang, and Dong Wang. 2023. Deep situation-aware interaction network for click-through rate prediction. InProceedings of the 17th ACM conference on recommender systems. 171–182
2023
-
[15]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[16]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[17]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[18]
Qiaoyu Tan, Jianwei Zhang, Jiangchao Yao, Ninghao Liu, Jingren Zhou, Hongxia Yang, and Xia Hu. 2021. Sparse-interest network for sequential recommendation. InProceedings of the 14th ACM international conference on web search and data mining. 598–606
2021
-
[19]
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural Discrete Representation Learning. InProc. Annual Conf. on Neural Information Processing Systems (NeurIPS). 6306–6315
2017
-
[20]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. InProc. Annual Conf. on Neural Information Processing Systems (NeurIPS). 5998–6008
2017
-
[21]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021. 1785–1797
2021
- [22]
-
[23]
Zhichen Zeng, Xiaolong Liu, Mengyue Hang, Xiaoyi Liu, Qinghai Zhou, Chaofei Yang, Yiqun Liu, Yichen Ruan, Laming Chen, Yuxin Chen, et al. 2025. InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6225–6233
2025
-
[24]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review arXiv 2024
- [25]
- [26]
- [27]
- [28]
-
[29]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[30]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[31]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.