Recognition: unknown
Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification
Pith reviewed 2026-05-10 07:57 UTC · model grok-4.3
The pith
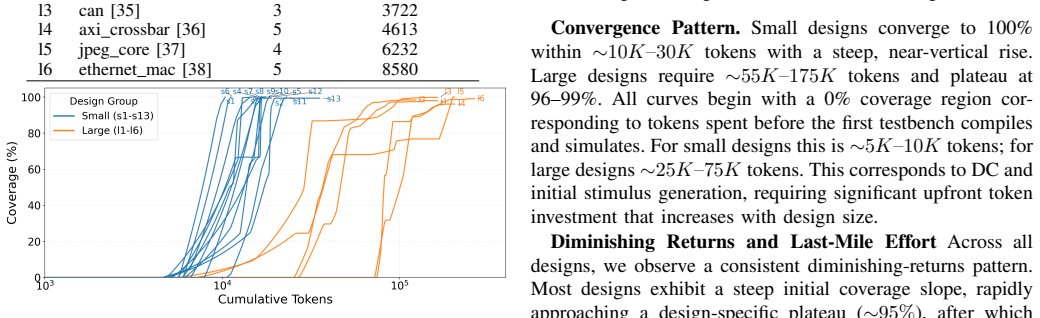
Domain-specialized agentic systems close hardware coverage holes with 4-13x fewer tokens than general baselines while reaching 95-99% coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A two-tier agentic framework demonstrates that domain specialization redirects token allocation toward coverage-directed reasoning and error recovery, yielding comparable or higher coverage levels of 95-99 percent with 4-13 times fewer tokens and 2-4 times faster convergence to targets than a general-purpose baseline across tested designs.
What carries the argument
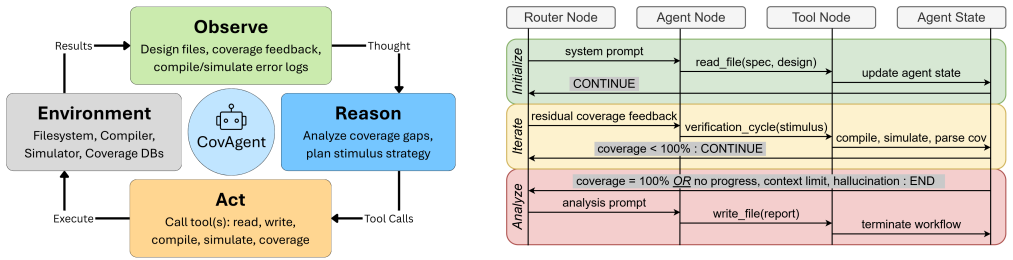
Taxonomy of coverage holes that separates methodology-bound ceilings such as tied-off hardware and dead code from reasoning frontiers such as protocol sequencing and narrow timing conditions, supported by six-category token tracking instrumentation.
Load-bearing premise
The efficiency gains and coverage hole taxonomy observed with the tested designs and agents extend to other hardware verification scenarios without confounding effects from prompt variations or unmeasured token tracking factors.
What would settle it
Re-running the comparison on an independent set of large designs and finding that the enhanced system achieves less than 4x token reduction or that coverage holes fall outside the proposed taxonomy categories.
Figures





read the original abstract
Coverage closure is the most time-consuming phase of hardware verification, and recent large language model (LLM)-based coding agents offer a promising approach to automated stimulus generation. However, prior LLM-based flows do not systematically analyze which coverage holes remain difficult to close or how inference-time computation is allocated during agentic verification. As a result, the efficiency limits and failure modes of LLM-based coverage closure remain poorly understood, particularly for large designs. We present an empirical study using a two-tier agentic framework comprising a base Codex agent and an enhanced domain-specialized LangGraph system. Our framework enables a taxonomy of coverage holes: methodology-bound ceilings (integration tied-off hardware, infeasible boundaries, dead code) and reasoning frontiers (protocol sequencing, multi-module pipeline warm-up, narrow timing conditions), exposing fundamental limits of purely LLM-driven approaches. We further instrument the system to track token usage across six categories, including system prompt, design comprehension, stimulus generation, coverage feedback, error recovery, and agentic overhead. We show that domain specialization shifts token allocation toward coverage-directed reasoning and improves efficiency. Across designs, the enhanced system achieves comparable or higher coverage (95-99%) while using 4-13x fewer tokens and converging to coverage targets 2-4x faster than a general-purpose baseline. Our results characterize the limits of LLM-based coverage closure, inform benchmark design and human escalation strategies, and guide profile-driven agent design for hardware verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study of LLM-based agents for hardware verification coverage closure. It introduces a two-tier agentic framework consisting of a base Codex agent and an enhanced domain-specialized LangGraph system, along with a taxonomy classifying coverage holes into methodology-bound ceilings (e.g., integration tied-off hardware, dead code) and reasoning frontiers (e.g., protocol sequencing, narrow timing conditions). The work instruments token usage across six categories (system prompt, design comprehension, stimulus generation, coverage feedback, error recovery, agentic overhead) and reports that the enhanced system achieves 95-99% coverage while using 4-13x fewer tokens and converging 2-4x faster than a general-purpose baseline across designs.
Significance. If the results hold after addressing experimental controls, the work would be significant for characterizing the practical limits of purely LLM-driven coverage closure in hardware verification. The taxonomy and token-category instrumentation provide concrete guidance on when agentic approaches hit fundamental ceilings versus where additional reasoning or human escalation is needed, and the efficiency metrics could inform profile-driven agent design and benchmark construction in the field.
major comments (2)
- [Abstract] Abstract: The central quantitative claims (4-13x token reduction, 2-4x faster convergence, 95-99% coverage) are reported without any details on the number of designs tested, statistical methods, error bars, data exclusion rules, or instrumentation of the six token categories. This absence makes the reliability and reproducibility of the efficiency results difficult to assess and is load-bearing for the paper's main contribution.
- [Abstract] Abstract and experimental description: The enhanced system is described as 'domain-specialized' and incorporating additional design-specific context and refined prompts, yet the comparison to the 'general-purpose baseline' provides no evidence that the baseline received equivalent prompt engineering or context. Without an ablation isolating the two-tier LangGraph architecture from specialization effects, the attribution of the 4-13x token savings and 2-4x speedup to the agentic framework (rather than prompt/domain differences) cannot be supported.
minor comments (1)
- The taxonomy of coverage holes is conceptually useful but would benefit from one or two concrete examples per category drawn from the tested designs to clarify the distinction between methodology-bound ceilings and reasoning frontiers.
Simulated Author's Rebuttal
We appreciate the referee's feedback, which highlights important aspects for improving the presentation of our empirical study on LLM-based agents for hardware verification. We provide point-by-point responses to the major comments and commit to revisions that enhance the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (4-13x token reduction, 2-4x faster convergence, 95-99% coverage) are reported without any details on the number of designs tested, statistical methods, error bars, data exclusion rules, or instrumentation of the six token categories. This absence makes the reliability and reproducibility of the efficiency results difficult to assess and is load-bearing for the paper's main contribution.
Authors: We agree that the abstract should provide more context on the experimental parameters to support the key claims. The full paper specifies the designs evaluated, details the six token categories and their instrumentation in the methods section, and presents results from multiple runs. We will revise the abstract to include the number of designs, a summary of the statistical approach (repeated independent trials with reported ranges), and a reference to the token usage tracking. This will improve reproducibility without exceeding length limits. revision: yes
-
Referee: [Abstract] Abstract and experimental description: The enhanced system is described as 'domain-specialized' and incorporating additional design-specific context and refined prompts, yet the comparison to the 'general-purpose baseline' provides no evidence that the baseline received equivalent prompt engineering or context. Without an ablation isolating the two-tier LangGraph architecture from specialization effects, the attribution of the 4-13x token savings and 2-4x speedup to the agentic framework (rather than prompt/domain differences) cannot be supported.
Authors: The baseline is explicitly the general-purpose Codex agent without domain specialization or the LangGraph two-tier structure, while the enhanced system combines both as our proposed approach. This reflects the practical deployment of domain-specialized agentic systems. We recognize the value of isolating the architecture's contribution and will add an ablation study in the revised version, comparing the base agent, prompt-specialized base agent, and full enhanced system. We will also update the abstract and experimental description to better clarify the baseline setup and the integrated nature of the enhancements. revision: yes
Circularity Check
No significant circularity: empirical measurements only
full rationale
The paper is an empirical study that reports measured outcomes (coverage percentages, token counts, convergence times) from running a two-tier agentic framework on specific hardware designs. No equations, derivations, fitted parameters, or predictions appear in the provided text. Claims rest on direct experimental comparisons rather than any self-referential definitions or self-citation chains that reduce the result to its inputs by construction. The central efficiency numbers are presented as observed deltas, not as outputs forced by prior author work or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coverage metrics in hardware verification are well-defined, objective, and can be reliably measured by standard tools.
invented entities (1)
-
Taxonomy of coverage holes (methodology-bound ceilings and reasoning frontiers)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Why First-Silicon Success Is Getting Harder for System Companies,
H. Foster, “Why First-Silicon Success Is Getting Harder for System Companies,” Sep. 2025
2025
-
[2]
Chip-Chat: Chal- lenges and Opportunities in Conversational Hardware Design,
J. Blocklove, S. Garg, R. Karri, and H. Pearce, “Chip-Chat: Chal- lenges and Opportunities in Conversational Hardware Design,” in2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD), Sep. 2023, pp. 1–6
2023
-
[3]
RTL-Repo: A Benchmark for Evaluating LLMs on Large-Scale RTL Design Projects,
A. Allam and M. Shalan, “RTL-Repo: A Benchmark for Evaluating LLMs on Large-Scale RTL Design Projects,” May 2024
2024
-
[4]
CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation,
M. DeLorenzo, V . Gohil, and J. Rajendran, “CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation,” Apr. 2024
2024
-
[5]
RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique,
S. Liu, W. Fang, Y . Lu, J. Wang, Q. Zhang, H. Zhang, and Z. Xie, “RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique,” Oct. 2024
2024
-
[6]
VerilogEval: Evaluating Large Language Models for Verilog Code Generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “VerilogEval: Evaluating Large Language Models for Verilog Code Generation,” Dec. 2023
2023
-
[7]
RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), Jan. 2024, pp. 722–727
2024
-
[8]
AutoChip: Automating HDL Generation Using LLM Feedback,
S. Thakur, J. Blocklove, H. Pearce, B. Tan, S. Garg, and R. Karri, “AutoChip: Automating HDL Generation Using LLM Feedback,” Jun. 2024
2024
-
[9]
VeriGen: A Large Language Model for Verilog Code Generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “VeriGen: A Large Language Model for Verilog Code Generation,”ACM Transactions on Design Automation of Electronic Systems, p. 3643681, Feb. 2024
2024
-
[10]
ChatCPU: An Agile CPU Design and Verification Platform with LLM,
X. Wang, G.-W. Wan, S.-Z. Wong, L. Zhang, T. Liu, Q. Tian, and J. Ye, “ChatCPU: An Agile CPU Design and Verification Platform with LLM,” inProceedings of the 61st ACM/IEEE Design Automation Conference, ser. DAC ’24. New York, NY , USA: Association for Computing Machinery, Nov. 2024, pp. 1–6
2024
-
[11]
MG-Verilog: Multi- grained Dataset Towards Enhanced LLM-assisted Verilog Generation,
Y . Zhang, Z. Yu, Y . Fu, C. Wan, and Y . C. Lin, “MG-Verilog: Multi- grained Dataset Towards Enhanced LLM-assisted Verilog Generation,” Jul. 2024
2024
-
[12]
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models,
Y . Fu, Y . Zhang, Z. Yu, S. Li, Z. Ye, C. Li, C. Wan, and Y . C. Lin, “GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models,” 2025. [Online]. Available: https://arxiv.org/abs/2309.10730
-
[13]
UVLLM: An automated universal rtl verification framework using LLMs,
Y . Hu, J. Ye, K. Xu, J. Sun, S. Zhang, X. Jiao, D. Pan, J. Zhou, N. Wang, W. Shan, X. Fang, X. Wang, N. Guan, and Z. Jiang, “UVLLM: An Automated Universal RTL Verification Framework using LLMs,” 2024. [Online]. Available: https://arxiv.org/abs/2411.16238
-
[14]
ChIRAAG: ChatGPT Informed Rapid and Automated Assertion Gen- eration,
B. Mali, K. Maddala, V . Gupta, S. Reddy, C. Karfa, and R. Karri, “ChIRAAG: ChatGPT Informed Rapid and Automated Assertion Gen- eration,” in2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). Knoxville, TN, USA: IEEE, Jul. 2024, pp. 680–683
2024
-
[15]
AssertLLM: Generating Hardware Verification Assertions from Design Specifications via Multi-LLMs,
W. Fang, M. Li, M. Li, Z. Yan, S. Liu, H. Zhang, and Z. Xie, “AssertLLM: Generating Hardware Verification Assertions from Design Specifications via Multi-LLMs,” in2024 IEEE LLM Aided Design Workshop (LAD), Jun. 2024, pp. 1–1
2024
-
[16]
Au- toBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design,
R. Qiu, G. L. Zhang, R. Drechsler, U. Schlichtmann, and B. Li, “Au- toBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design,” inProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, ser. MLCAD ’24. New York, NY , USA: Association for Computing Machinery, Sep. 2024, pp. 1–10
2024
-
[17]
LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation,
Z. Zhang, G. Chadwick, H. McNally, Y . Zhao, and R. Mullins, “LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation,” Oct. 2023
2023
-
[18]
VerilogReader: LLM-Aided Hardware Test Generation,
R. Ma, Y . Yang, Z. Liu, J. Zhang, M. Li, J. Huang, and G. Luo, “VerilogReader: LLM-Aided Hardware Test Generation,” in2024 IEEE LLM Aided Design Workshop (LAD), Jun. 2024, pp. 1–5
2024
-
[19]
Prompt. Verify. Repeat. LLMs in the Hardware Verification Cycle,
M. Hassan, M. Nadeem, K. Qayyum, C. K. Jha, and R. Drechsler, “Prompt. Verify. Repeat. LLMs in the Hardware Verification Cycle,” in 2025 IEEE International Conference on Omni-layer Intelligent Systems (COINS), 2025, pp. 1–6
2025
-
[20]
From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification
J. Ye, Y . Hu, K. Xu, D. Pan, Q. Chen, J. Zhou, S. Zhao, X. Fang, X. Wang, N. Guan, and Z. Jiang, “From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification,” 2025. [Online]. Available: https://arxiv.org/abs/2504.19959
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
J. Wang and Z. Duan, “Agent AI with LangGraph: A Modular Framework for Enhancing Machine Translation Using Large Language Models,” 2024. [Online]. Available: https://arxiv.org/abs/2412.03801
-
[23]
CovAgent GitHub,
Blinded, “CovAgent GitHub,” mar 2026. [Online]. Available: blinded
2026
-
[24]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters,” 2024. [Online]. Available: https://arxiv.org/abs/2408.03314
work page Pith review arXiv 2024
-
[25]
Y . Wu, Z. Sun, S. Li, S. Welleck, and Y . Yang, “Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models,” 2025. [Online]. Available: https://arxiv.org/abs/2408.00724
-
[26]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
N. Pinckney, C. Deng, C.-T. Ho, Y .-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Evaluating Large Language Models and Agents on RTL Design and Verification,” 2025. [Online]. Available: https://arxiv.org/abs/2506.14074
-
[28]
DSP Slice: Floating Point Units,
S. Mehta, “DSP Slice: Floating Point Units,” https://github.com/samidhm/DSP Slice/tree/main/Floating Point Units, 2020
2020
-
[29]
tpu like design: TPU-like design with pooling unit,
V . Patel and UT-LCA, “tpu like design: TPU-like design with pooling unit,” https://github.com/UT- LCA/tpu like design/tree/master/design ws vedant, 2019
2019
-
[30]
uart: Verilog implementation of a simple UART core,
J. Str ¨ombergson, “uart: Verilog implementation of a simple UART core,” https://github.com/secworks/uart, 2014
2014
-
[31]
sha1: Verilog implementation of the SHA-1 hash function,
——, “sha1: Verilog implementation of the SHA-1 hash function,” https://github.com/secworks/sha1, 2014
2014
-
[32]
chacha: Verilog implementation of the ChaCha stream cipher,
——, “chacha: Verilog implementation of the ChaCha stream cipher,” https://github.com/secworks/chacha, 2014
2014
-
[33]
SD-card-controller: SD/SDHC card controller for Wish- bone bus,
M. Czerski, “SD-card-controller: SD/SDHC card controller for Wish- bone bus,” https://github.com/mczerski/SD-card-controller, 2013
2013
-
[34]
trng: True Random Number Generator core imple- mented in Verilog,
J. Str ¨ombergson, “trng: True Random Number Generator core imple- mented in Verilog,” https://github.com/secworks/trng, 2014
2014
-
[35]
FreeCores CAN,
I. Mohor, “FreeCores CAN,” mar 2006. [Online]. Available: https://github.com/freecores/can/tree/master
2006
-
[36]
AMBA AXI Crossbar,
D. Pretet, “AMBA AXI Crossbar,” sep 2025. [Online]. Available: https://github.com/dpretet/axi-crossbar/tree/main
2025
-
[37]
High throughput JPEG decoder,
“High throughput JPEG decoder,” October 2020. [Online]. Available: https://github.com/ultraembedded/core jpeg
2020
-
[38]
Ethernet MAC Design,
I. Mohor and O. Kindgren, “Ethernet MAC Design,” june 2010. [Online]. Available: https://github.com/freecores/ethmac
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.