Recognition: unknown
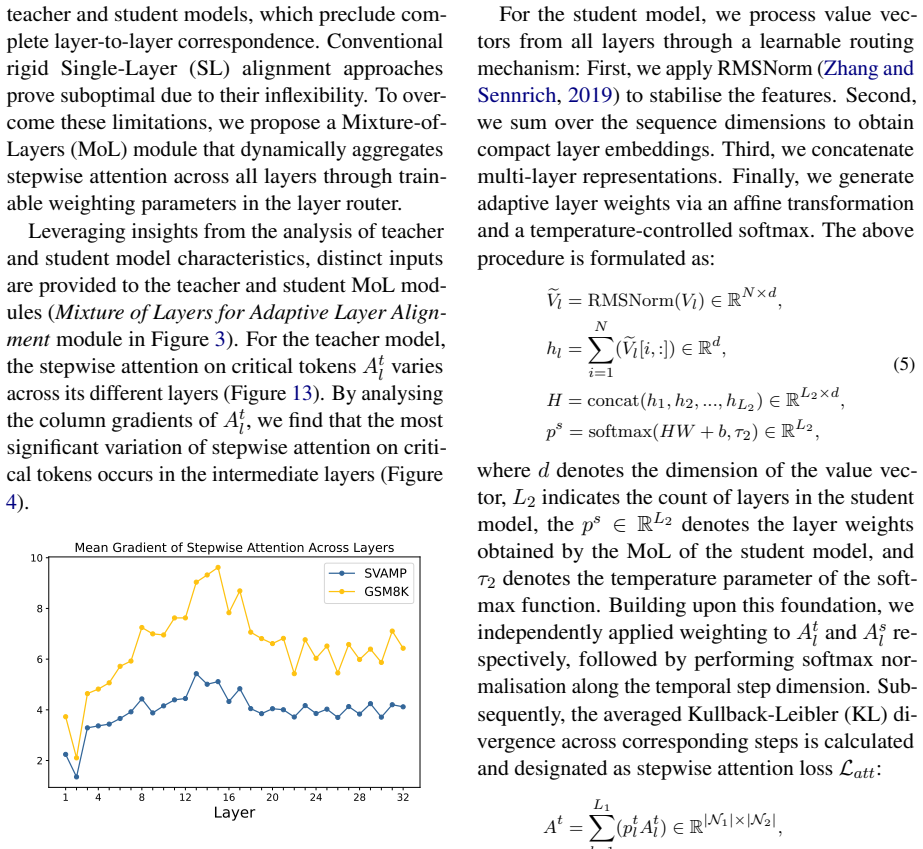
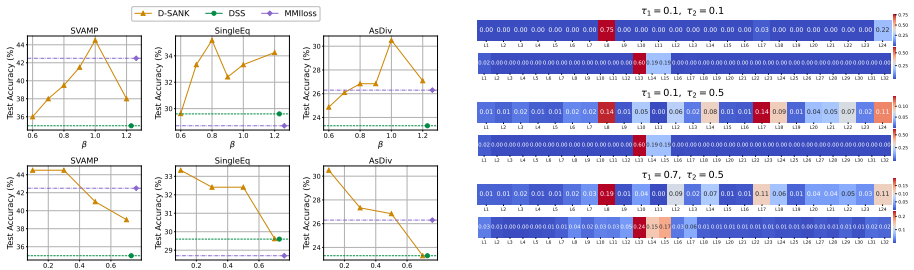
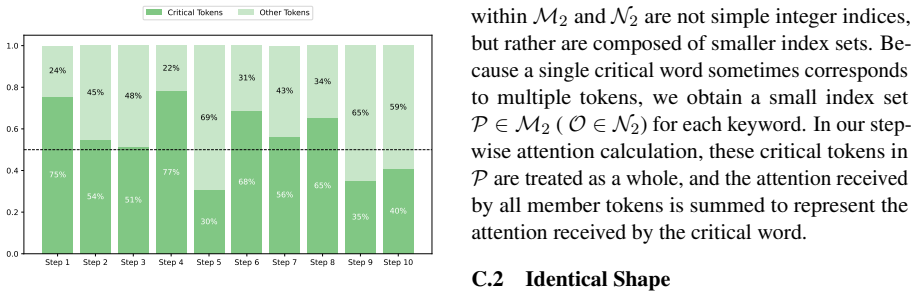
Improving Reasoning Capabilities in Small Models through Mixture-of-Layers Distillation with Stepwise Attention on Key Information
Pith reviewed 2026-05-10 08:52 UTC · model grok-4.3
The pith
A CoT distillation framework transfers stepwise teacher attention on key information via a Mixture-of-Layers module to improve reasoning in small language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a novel CoT distillation framework that transfers the teacher's stepwise attention on key information to the student model. ... Our method achieves consistent performance improvements across multiple mathematical and commonsense reasoning datasets. To our knowledge, it is the first method to leverage stepwise attention within CoT distillation to improve small model reasoning.
Load-bearing premise
The assumption that the observed progressive attention shifts toward key information are causally important for correct reasoning and can be effectively transferred to guide a student model's internal focus, combined with the premise that the Mixture-of-Layers module can dynamically align layers without introducing misalignment artifacts.
Figures









read the original abstract
The significant computational demands of large language models have increased interest in distilling reasoning abilities into smaller models via Chain-of-Thought (CoT) distillation. Current CoT distillation methods mainly focus on transferring teacher-generated rationales for complex reasoning to student models. However, they do not adequately explore teachers' dynamic attention toward critical information during reasoning. We find that language models exhibit progressive attention shifts towards key information during reasoning, which implies essential clues for drawing conclusions. Building on this observation and analysis, we introduce a novel CoT distillation framework that transfers the teacher's stepwise attention on key information to the student model. This establishes structured guidance for the student's progressive concentration on key information during reasoning. More importantly, we develop a Mixture of Layers module enabling dynamic alignment that adapts to different layers between the teacher and student. Our method achieves consistent performance improvements across multiple mathematical and commonsense reasoning datasets. To our knowledge, it is the first method to leverage stepwise attention within CoT distillation to improve small model reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models exhibit progressive attention shifts towards key information during reasoning.
invented entities (1)
-
Mixture of Layers module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hojae Lee, Junho Kim, and SangKeun Lee
Parsing algebraic word problems into equa- tions.Transactions of the Association for Computa- tional Linguistics, 3:585–597. Hojae Lee, Junho Kim, and SangKeun Lee. 2024. Mentor-kd: Making small language models better multi-step reasoners. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 17643–17658. Liunia...
2024
-
[2]
From System 1 to System 2: A Survey of Reasoning Large Language Models
From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419. Yantao Liu, Zhao Zhang, Zijun Yao, Shulin Cao, Lei Hou, and Juanzi Li. 2024. Aligning teacher with stu- dent preferences for tailored training data generation. arXiv preprint arXiv:2406.19227. Meta. 2024. Introducing meta llama 3: The most ca- pable ope...
work page internal anchor Pith review arXiv 2024
-
[3]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal
A diverse corpus for evaluating and developing english math word problem solvers.arXiv preprint arXiv:2106.15772. Arkil Patel, Satwik Bhattamishra, and Navin Goyal
-
[4]
Multi-Step Reasoning with Large Language Models, a Survey,
Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online. Association for Computational Linguistics. Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thom...
-
[5]
He used 10 tickets to buy toys
treats CoT distillation as a multitask learn- ing problem, assigning two labels per query: the final answer and the rationale generated by the teacher model. Following this, several studies in- corporate an auxiliary loss to further enhance the complex reasoning capabilities of small language models. Mentor-KD (Lee et al., 2024) introduces a mentor model ...
2024
-
[10]
Q: {Question} (a) Generating CoT when given the question
The (expression) should not contain any commas and should be the raw combined formula. Q: {Question} (a) Generating CoT when given the question. Assume you are one of the greatest AI scientists, logicians, and mathematicians. Please answer the questions according to the following examples and requirementsystem content user content [Examples] Q: {Question}...
-
[11]
Let's think through the problem step by step and provide the answer strictly in the R format as shown in the above example
-
[12]
For percentages, to allow the eval() function to compute, express them as a division by
-
[13]
For example, “40%” should be written as (40 / 100)
-
[14]
The answer is (expression)
Please ensure that the final answer ends with “The answer is (expression)”, where (expression) is enclosed in parentheses
-
[15]
Q: {Question} GT: The final answer to this question is {Ground Truth}
The (expression) should not contain any commas and should be the raw combined formula. Q: {Question} GT: The final answer to this question is {Ground Truth}. Based on this answer, please work through the problem step by step to deduce the question. (b) Generating CoT when given the question and ground truth. Figure 9: Prompt template for generating CoT of...
-
[16]
(c) (S1) Sarah has 9 books and Joseph had twice the number of Sarah's books, but he lost 2 of them
(S4) The difference in the amount spent between the basketball coach and the baseball coach is 63 - 112 = 19. (c) (S1) Sarah has 9 books and Joseph had twice the number of Sarah's books, but he lost 2 of them. How many books does Joseph currently have? Question GPT2-Medium (MMIloss) (S2) Sarah has 9 books. (S3) Joseph had twice the number of Sarah's books...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.