Recognition: unknown
When Do Early-Exit Networks Generalize? A PAC-Bayesian Theory of Adaptive Depth
Pith reviewed 2026-05-10 09:24 UTC · model grok-4.3
The pith
Early-exit networks generalize with bounds depending on expected depth and exit entropy rather than maximum depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
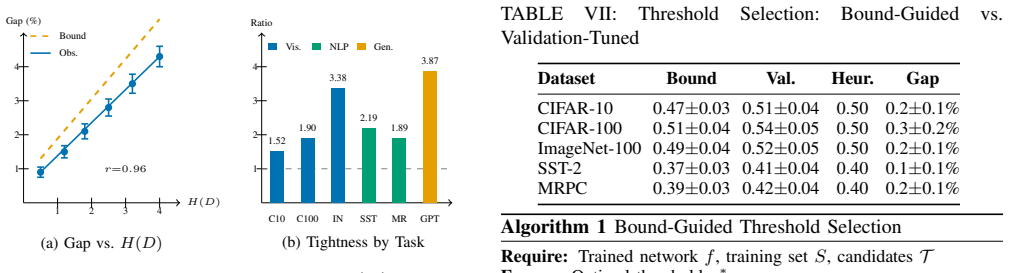
We prove the first generalization bounds for adaptive-depth networks depending on exit-depth entropy H(D) and expected depth E[D] rather than maximum depth K, with sample complexity O((E[D] · d + H(D))/ε²). The analysis supplies the leading coefficient √(2 ln 2) ≈ 1.177 with full derivation, establishes sufficient conditions for adaptive networks to outperform fixed-depth counterparts, relaxes the label-independence assumption to ε-approximate policies, and validates the bounds empirically across 6 architectures and 7 benchmarks with tightness ratios of 1.52–3.87×.
What carries the argument
The random variable D representing exit depth, whose entropy H(D) and expectation E[D] enter the PAC-Bayesian bound in place of the fixed maximum depth K.
If this is right
- Sample complexity scales linearly with average depth E[D] instead of the maximum depth K.
- Adaptive-depth networks can provably achieve strictly better generalization than fixed-depth networks under conditions on the exit policy.
- Bound-guided choice of exit thresholds can match the performance of validation-tuned thresholds within 0.1–0.3% accuracy.
- The framework extends directly to learned routing policies once the ε-approximate label independence holds.
Where Pith is reading between the lines
- The same entropy-plus-expectation structure could be used to analyze other adaptive-computation schemes such as mixture-of-experts or dynamic routing.
- Training objectives that penalize high exit-depth entropy might yield models with both faster inference and stronger generalization guarantees.
- The explicit leading constant √(2 ln 2) suggests the bound can be tightened further by optimizing the PAC-Bayesian prior over depth distributions.
Load-bearing premise
The exit policy's choice of depth is independent of the true label (or approximately so for learned policies).
What would settle it
Train an early-exit network, measure its empirical generalization gap on a held-out set, and check whether the gap exceeds the bound constructed from the observed E[D] and H(D) by more than the reported tightness factor of roughly 3.87×.
Figures
read the original abstract
Early-exit neural networks enable adaptive computation by allowing confident predictions to exit at intermediate layers, achieving 2-8$\times$ inference speedup. Despite widespread deployment, their generalization properties lack theoretical understanding -- a gap explicitly identified in recent surveys. This paper establishes a unified PAC-Bayesian framework for adaptive-depth networks. (1) Novel Entropy-Based Bounds: We prove the first generalization bounds depending on exit-depth entropy $H(D)$ and expected depth $\mathbb{E}[D]$ rather than maximum depth $K$, with sample complexity $\mathcal{O}((\mathbb{E}[D] \cdot d + H(D))/\epsilon^2)$. (2) Explicit Constructive Constants: Our analysis yields the leading coefficient $\sqrt{2\ln 2} \approx 1.177$ with complete derivation. (3) Provable Early-Exit Advantages: We establish sufficient conditions under which adaptive-depth networks strictly outperform fixed-depth counterparts. (4) Extension to Approximate Label Independence: We relax the label-independence assumption to $\epsilon$-approximate policies, broadening applicability to learned routing. (5) Comprehensive Validation: Experiments across 6 architectures on 7 benchmarks demonstrate tightness ratios of 1.52-3.87$\times$ (all $p < 0.001$) versus $>$100$\times$ for classical bounds. Bound-guided threshold selection matches validation-tuned performance within 0.1-0.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper develops a PAC-Bayesian framework for early-exit neural networks. It derives the first generalization bounds that depend on the entropy H(D) of the random exit depth D and its expectation E[D] (rather than maximum depth K), yielding sample complexity O((E[D] · d + H(D))/ε²). The analysis supplies explicit leading constants (√(2 ln 2) ≈ 1.177), sufficient conditions under which adaptive-depth networks outperform fixed-depth ones, a relaxation of the label-independence assumption to ε-approximate independence for learned routers, and experiments on 6 architectures across 7 benchmarks reporting tightness ratios of 1.52–3.87× (p < 0.001) versus >100× for classical bounds, plus bound-guided threshold selection matching validation performance within 0.1–0.3%.
Significance. If the central claims hold, the work would address an explicitly noted gap in the theoretical understanding of early-exit networks. The shift from maximum-depth to entropy- and expectation-based quantities is a substantive advance for adaptive computation, and the explicit constants together with the experimental tightness ratios constitute clear strengths. The framework could guide practical router design. The paper supplies complete derivations and reports results across multiple architectures and benchmarks.
major comments (2)
- [§3] §3 (main PAC-Bayesian theorem): the derivation of the O((E[D] · d + H(D))/ε²) sample complexity obtains the stated dependence on E[D] and H(D) only after invoking that the random exit depth D is independent of the label Y (or ε-close in total variation). The ε-relaxation is introduced, yet the resulting additive penalty term linear in ε (or in the KL between joint and product measures) is not quantified in the reported tightness ratios.
- [Experiments] Experiments section (and Table reporting tightness): the claimed 1.52–3.87× tightness ratios (all p < 0.001) are presented without measured ε values for the learned exit policies on the 7 benchmarks. Without these values it is impossible to verify whether the extra term from the ε-approximate independence remains negligible relative to the H(D) term or whether the claimed scaling still governs the observed bounds.
minor comments (2)
- [Abstract] The abstract states that the leading coefficient √(2 ln 2) is obtained with a complete derivation; this derivation should be cross-referenced explicitly in the main text when the bound is first stated.
- [§2] Notation for the exit-depth random variable D and its distribution is introduced without an early dedicated paragraph clarifying the support and measurability assumptions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight important points regarding the independence assumption and its empirical quantification. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and measurements.
read point-by-point responses
-
Referee: [§3] §3 (main PAC-Bayesian theorem): the derivation of the O((E[D] · d + H(D))/ε²) sample complexity obtains the stated dependence on E[D] and H(D) only after invoking that the random exit depth D is independent of the label Y (or ε-close in total variation). The ε-relaxation is introduced, yet the resulting additive penalty term linear in ε (or in the KL between joint and product measures) is not quantified in the reported tightness ratios.
Authors: We agree that the main PAC-Bayesian theorem in §3 derives the stated dependence on E[D] and H(D) under the (approximate) independence of D and Y. The paper introduces the ε-approximate independence relaxation to accommodate learned routers, but the referee correctly notes that the resulting additive penalty term was not quantified in the reported tightness ratios. In the revised manuscript we will explicitly compute and report the measured ε values (total variation distance between the joint P(D,Y) and the product measure) for each of the 7 benchmarks, together with the corresponding additive penalty terms in the bounds. This will permit direct verification of the penalty's magnitude relative to the H(D) term. revision: yes
-
Referee: [Experiments] Experiments section (and Table reporting tightness): the claimed 1.52–3.87× tightness ratios (all p < 0.001) are presented without measured ε values for the learned exit policies on the 7 benchmarks. Without these values it is impossible to verify whether the extra term from the ε-approximate independence remains negligible relative to the H(D) term or whether the claimed scaling still governs the observed bounds.
Authors: We concur that the absence of measured ε values prevents a complete empirical assessment of the approximate-independence relaxation. As indicated in our response to the §3 comment, the revised experiments section will include the computed ε values for all benchmarks and architectures, along with an updated analysis of the tightness ratios that accounts for the penalty terms. These additions will allow readers to confirm whether the observed scaling remains governed by the E[D]·d + H(D) expression. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from stated assumptions.
full rationale
The paper derives PAC-Bayesian generalization bounds for early-exit networks that depend on exit-depth entropy H(D) and expected depth E[D]. The central steps invoke standard PAC-Bayesian prior/posterior constructions plus a label-independence assumption on the exit policy (relaxed to ε-approximate independence). These are explicit modeling choices, not self-definitions or fitted quantities renamed as predictions. No equation reduces the claimed O((E[D]·d + H(D))/ε²) sample complexity to an input by construction, and no load-bearing step collapses to a self-citation chain. The framework applies known PAC-Bayesian machinery to a new adaptive-depth setting without tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Branchynet: Fast inference via early exiting from deep neural networks,
S. Teerapittayanon, B. McDanel, and H. T. Kung, “Branchynet: Fast in- ference via early exiting from deep neural networks,”arXiv:1709.01686, vol. abs/1709.01686, 2017
-
[2]
Multi-scale dense networks for resource efficient image classification,
G. Huang, D. Chen, T. Li, F. Wu, L. van der Maaten, and K. Q. Weinberger, “Multi-scale dense networks for resource efficient image classification,” inICLR 2018. OpenReview.net, 2018
2018
-
[3]
Dynamic neural networks: A survey,
Y . Han, G. Huang, S. Song, L. Yang, H. Wang, and Y . Wang, “Dynamic neural networks: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 11, pp. 7436–7456, 2022
2022
-
[4]
Confident adaptive language modeling,
T. Schuster, A. Fisch, J. Gupta, M. Dehghani, D. Bahri, V . Tran, Y . Tay, and D. Metzler, “Confident adaptive language modeling,” inNeurIPS 2022, 2022
2022
-
[5]
Dynamic neural networks: advantages and challenges,
G. Huang, “Dynamic neural networks: advantages and challenges,” National Science Review, vol. 11, 2024
2024
-
[6]
Early-exit deep neural network - A comprehensive survey,
H. R. P, V . Srivastava, K. Chaurasia, R. G. Pacheco, and R. S. Couto, “Early-exit deep neural network - A comprehensive survey,”ACM Comput. Surv., vol. 57, no. 3, pp. 75:1–75:37, 2025
2025
-
[7]
On the uniform convergence of relative frequencies of events to their probabilities,
V . N. Vapnik and A. Y . Chervonenkis, “On the uniform convergence of relative frequencies of events to their probabilities,”Theory of Probability & Its Applications, vol. 16, 1971
1971
-
[8]
Rademacher and gaussian complexi- ties: Risk bounds and structural results,
P. L. Bartlett and S. Mendelson, “Rademacher and gaussian complexi- ties: Risk bounds and structural results,”J. Mach. Learn. Res., vol. 3, pp. 463–482, 2002
2002
-
[9]
Some pac-bayesian theorems,
D. A. McAllester, “Some pac-bayesian theorems,”Mach. Learn., vol. 37, no. 3, pp. 355–363, 1999
1999
-
[10]
A pac-bayesian approach to spectrally-normalized margin bounds for neural networks,
B. Neyshabur, S. Bhojanapalli, and N. Srebro, “A pac-bayesian approach to spectrally-normalized margin bounds for neural networks,” inICLR
-
[11]
OpenReview.net, 2018
2018
-
[12]
Understand- ing deep learning requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understand- ing deep learning requires rethinking generalization,” inICLR 2017. OpenReview.net, 2017
2017
-
[13]
Fast yet safe: Early-exiting with risk control,
M. Jazbec, A. Timans, T. H. Veljkovic, K. Sakmann, D. Zhang, C. A. Naesseth, and E. T. Nalisnick, “Fast yet safe: Early-exiting with risk control,” inNeurIPS 2024, 2024
2024
-
[14]
Depth-adaptive transformer,
M. Elbayad, J. Gu, E. Grave, and M. Auli, “Depth-adaptive transformer,” inICLR 2020. OpenReview.net, 2020
2020
-
[15]
BERT loses patience: Fast and robust inference with early exit,
W. Zhou, C. Xu, T. Ge, J. J. McAuley, K. Xu, and F. Wei, “BERT loses patience: Fast and robust inference with early exit,” inNeurIPS 2020, 2020
2020
-
[16]
Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference,
L. D. Corro, A. D. Giorno, S. Agarwal, B. Yu, A. Awadallah, and S. Mukherjee, “Skipdecode: Autoregressive skip decoding with batch- ing and caching for efficient LLM inference,”arXiv:2307.02628, vol. abs/2307.02628, 2023
-
[17]
Layerskip: Enabling early exit inference and self-speculative decoding,
M. Elhoushi, A. Shrivastava, D. Liskovich, B. Hosmer, B. Wasti, L. Lai, A. Mahmoud, B. Acun, S. Agarwal, A. Roman, A. A. Aly, B. Chen, and C. Wu, “Layerskip: Enabling early exit inference and self-speculative decoding,” inACL 2024. Association for Computational Linguistics, 2024, pp. 12 622–12 642
2024
-
[18]
The sample complexity of pattern classification with neural networks: The size of the weights is more important than the size of the network,
P. L. Bartlett, “The sample complexity of pattern classification with neural networks: The size of the weights is more important than the size of the network,”IEEE Trans. Inf. Theory, vol. 44, no. 2, pp. 525– 536, 1998
1998
-
[19]
Information-theoretic analysis of general- ization capability of learning algorithms,
A. Xu and M. Raginsky, “Information-theoretic analysis of general- ization capability of learning algorithms,” inNeurIPS 2017, 2017, pp. 2524–2533
2017
-
[20]
Reasoning about generalization via conditional mutual information,
T. Steinke and L. Zakynthinou, “Reasoning about generalization via conditional mutual information,” inCOLT 2020, ser. Proceedings of Machine Learning Research, vol. 125. PMLR, 2020, pp. 3437–3452
2020
-
[21]
Contrastive multiview coding,
Y . Tian, D. Krishnan, and P. Isola, “Contrastive multiview coding,” inECCV 2020, ser. Lecture Notes in Computer Science, vol. 12356. Springer, 2020, pp. 776–794
2020
-
[22]
Shallow-deep networks: Under- standing and mitigating network overthinking,
Y . Kaya, S. Hong, and T. Dumitras, “Shallow-deep networks: Under- standing and mitigating network overthinking,” inICML 2019, ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 2019, pp. 3301–3310
2019
-
[23]
Deebert: Dynamic early exiting for accelerating BERT inference,
J. Xin, R. Tang, J. Lee, Y . Yu, and J. Lin, “Deebert: Dynamic early exiting for accelerating BERT inference,” inACL 2020. Association for Computational Linguistics, 2020
2020
-
[24]
Fastbert: a self-distilling BERT with adaptive inference time,
W. Liu, P. Zhou, Z. Wang, Z. Zhao, H. Deng, and Q. Ju, “Fastbert: a self-distilling BERT with adaptive inference time,” inACL 2020. Association for Computational Linguistics, 2020, pp. 6035–6044
2020
-
[25]
Fast and robust early-exiting frame- work for autoregressive language models with synchronized parallel decoding,
S. Bae, J. Ko, H. Song, and S. Yun, “Fast and robust early-exiting frame- work for autoregressive language models with synchronized parallel decoding,” inEMNLP 2023. Association for Computational Linguistics, 2023, pp. 5910–5924
2023
-
[26]
EDANAS: adaptive neural architecture search for early exit neural networks,
M. Gambella and M. Roveri, “EDANAS: adaptive neural architecture search for early exit neural networks,” inIJCNN 2023. IEEE, 2023, pp. 1–8
2023
-
[27]
E2cm: Early exit via class means for efficient supervised and unsupervised learning,
A. G ¨ormez, V . R. Dasari, and E. Koyuncu, “E2cm: Early exit via class means for efficient supervised and unsupervised learning,” inIJCNN
-
[28]
Spectrally-normalized margin bounds for neural networks,
P. L. Bartlett, D. J. Foster, and M. Telgarsky, “Spectrally-normalized margin bounds for neural networks,” inNeurIPS 2017, 2017, pp. 6240– 6249
2017
-
[29]
Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data,
G. K. Dziugaite and D. M. Roy, “Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data,” inUAI 2017. AUAI Press, 2017
2017
-
[30]
Pac-bayes bounds for supervised classification,
O. Catoni, “Pac-bayes bounds for supervised classification,” inMeasures of Complexity: Festschrift for Alexey Chervonenkis. Springer, 2015
2015
-
[31]
Stronger generalization bounds for deep nets via a compression approach,
S. Arora, R. Ge, B. Neyshabur, and Y . Zhang, “Stronger generalization bounds for deep nets via a compression approach,” inICML 2018, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 2018, pp. 254–263
2018
-
[32]
Why should we add early exits to neural networks?
S. Scardapane, M. Scarpiniti, E. Baccarelli, and A. Uncini, “Why should we add early exits to neural networks?”Cogn. Comput., vol. 12, no. 5, pp. 954–966, 2020
2020
-
[33]
Tighter information-theoretic generalization bounds from supersamples,
Z. Wang and Y . Mao, “Tighter information-theoretic generalization bounds from supersamples,” inICML 2023, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 36 111–36 137
2023
-
[34]
Information-theoretic generalization bounds for deep neural networks,
H. He and Z. Goldfeld, “Information-theoretic generalization bounds for deep neural networks,”IEEE Trans. Inf. Theory, vol. 71, no. 8, pp. 6227–6247, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.