Recognition: unknown
Skill-RAG: Failure-State-Aware Retrieval Augmentation via Hidden-State Probing and Skill Routing
Pith reviewed 2026-05-10 08:25 UTC · model grok-4.3
The pith
Skill-RAG detects query-evidence misalignment via hidden-state probing and routes to one of four targeted skills to fix persistent RAG failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
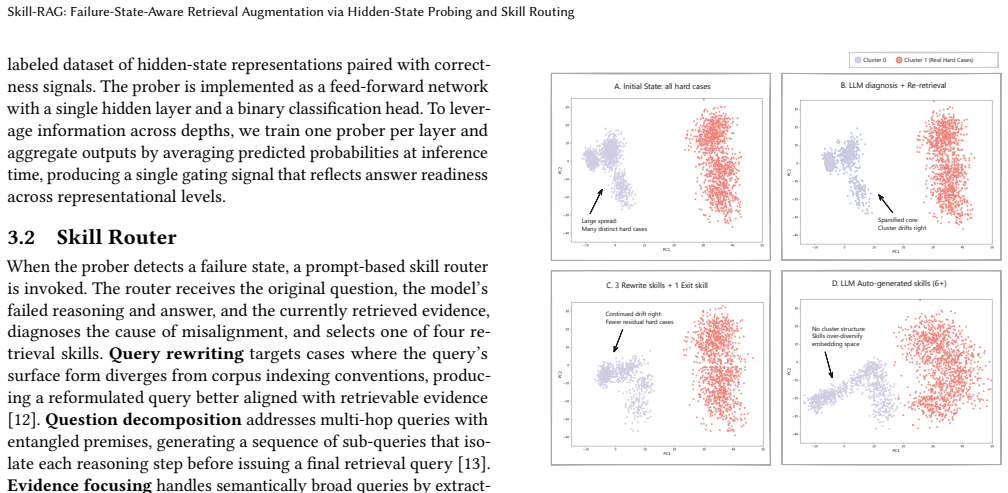
Skill-RAG establishes that query-evidence misalignment forms a typed rather than monolithic failure space that can be read from hidden states; a lightweight prober gates the pipeline and triggers a skill router that selects among query rewriting, question decomposition, evidence focusing, and exit to realign the query and evidence before regeneration, producing measurable accuracy gains on hard cases that survive multi-turn retrieval and especially on out-of-distribution benchmarks.
What carries the argument
The hidden-state prober that monitors model activations at retrieval and generation stages to detect misalignment states, coupled with the prompt-based skill router that maps those states to one of four corrective retrieval skills.
If this is right
- Accuracy rises on questions that remain unsolved after conventional multi-turn retrieval.
- Gains are larger on out-of-distribution datasets than on in-distribution ones.
- Representation analyses show the four skills map to distinct, structured regions in the failure-state space.
- Persistent failures can be treated as correctable typed misalignments instead of generic signals to retry retrieval.
Where Pith is reading between the lines
- Early diagnosis could shorten retrieval loops and lower token cost by skipping unnecessary iterations on hopeless cases.
- The typed-failure view may extend to other LLM grounding methods where internal activations reveal similar misalignment patterns.
- Modular skill libraries could grow beyond four actions, allowing task-specific routers for code generation or multi-hop reasoning.
Load-bearing premise
A lightweight hidden-state prober can reliably identify distinct query-evidence misalignment states and that these states occupy separable regions so the router can choose the matching skill.
What would settle it
An ablation in which the prober is replaced by random skill selection or removed entirely produces accuracy gains comparable to the full Skill-RAG system on the same hard-case and out-of-distribution benchmarks.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) has emerged as a foundational paradigm for grounding large language models in external knowledge. While adaptive retrieval mechanisms have improved retrieval efficiency, existing approaches treat post-retrieval failure as a signal to retry rather than to diagnose -- leaving the structural causes of query-evidence misalignment unaddressed. We observe that a significant portion of persistent retrieval failures stem not from the absence of relevant evidence but from an alignment gap between the query and the evidence space. We propose Skill-RAG, a failure-aware RAG framework that couples a lightweight hidden-state prober with a prompt-based skill router. The prober gates retrieval at two pipeline stages; upon detecting a failure state, the skill router diagnoses the underlying cause and selects among four retrieval skills -- query rewriting, question decomposition, evidence focusing, and an exit skill for truly irreducible cases -- to correct misalignment before the next generation attempt. Experiments across multiple open-domain QA and complex reasoning benchmarks show that Skill-RAG substantially improves accuracy on hard cases persisting after multi-turn retrieval, with particularly strong gains on out-of-distribution datasets. Representation-space analyses further reveal that the proposed skills occupy structured, separable regions of the failure state space, supporting the view that query-evidence misalignment is a typed rather than monolithic phenomenon.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper describes an engineering framework (hidden-state prober + prompt-based skill router selecting among four skills) validated by benchmark experiments. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on empirical accuracy gains rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a purely empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations
2024
-
[2]
Ingeol Baek, Hwan Chang, Byeongjeong Kim, Jimin Lee, and Hwanhee Lee
-
[3]
InFindings of the Association for Computational Linguistics: NAACL
Probing-rag: Self-probing to guide language models in selective document retrieval. InFindings of the Association for Computational Linguistics: NAACL
-
[4]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Gen- eration for Large Language Models: A Survey.arXiv preprint arXiv:2312.10997 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reason- ing steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
2020
-
[6]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park
-
[7]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Mexico City, Mexico, 7036–7050. doi:10.18...
-
[8]
Active retrieval augmented generation
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi- Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. InProceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics, Singapore, 7969–7992. doi:10.18653/v1/2023.emnlp-main.495
-
[9]
Mingyu Jin, Weidi Luo, Sitao Cheng, Xinyi Wang, Wenyue Hua, Ruixiang Tang, William Yang Wang, and Yongfeng Zhang. 2025. Disentangling memory and reasoning ability in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1681–1701
2025
-
[10]
Mingyu Jin, Qinkai Yu, Jingyuan Huang, Qingcheng Zeng, Zhenting Wang, Wenyue Hua, Haiyan Zhao, Kai Mei, Yanda Meng, Kaize Ding, et al. 2025. Ex- ploring concept depth: How large language models acquire knowledge and concept at different layers?. InProceedings of the 31st international conference on computational linguistics. 558–573
2025
-
[11]
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1601–1611
2017
-
[12]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[13]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. Curran Associates, Inc., 9459–9474
2020
-
[14]
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query Rewriting for Retrieval-Augmented Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 5303–5315. doi:10.18653/v1/2023. emnlp-main.322
-
[15]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, Singapore, 5687–5711. doi:10.18653/v1/2023.findings-emnlp.378
-
[16]
2009.The probabilistic relevance frame- work: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance frame- work: BM25 and beyond. Vol. 4. Now Publishers Inc
2009
-
[17]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. InFindings of the Association for Computational Linguistics: EMNLP 2023. 9248–9274
2023
-
[18]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. 2024. DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Asso...
- [19]
-
[21]
Transactions of the Association for Computational Linguistics10 (2022), 539–554
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[23]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 10014–10037. doi:10....
-
[24]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[25]
InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers)
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 10014–10037
-
[26]
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. 2024. Corrective Retrieval Augmented Generation.arXiv preprint arXiv:2401.15884(2024)
work page internal anchor Pith review arXiv 2024
-
[27]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.