Recognition: unknown
Watching Movies Like a Human: Egocentric Emotion Understanding for Embodied Companions
Pith reviewed 2026-05-10 08:47 UTC · model grok-4.3
The pith
Creates the first egocentric screen-view movie emotion benchmark and demonstrates that cinematic models drop sharply in Macro-F1 on realistic robot-like viewing conditions while domain-specific training improves robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-domain experiments reveal a severe domain gap: models trained on cinematic footage drop from 27.99 to 16.69 Macro-F1 when evaluated on realistic egocentric screen-view observations. Training on ESE substantially improves robustness under realistic viewing conditions.
Load-bearing premise
The controlled egocentric screen-view capture conditions used for the 224 trailers accurately represent the viewpoint distortions, scale changes, illumination, and interference that real embodied agents would encounter in uncontrolled environments.
Figures








read the original abstract
Embodied robotic agents often perceive movies through an egocentric screen-view interface rather than native cinematic footage, introducing domain shifts such as viewpoint distortion, scale variation, illumination changes, and environmental interference. However, existing research on movie emotion understanding is almost exclusively conducted on cinematic footage, limiting cross-domain generalization to real-world viewing scenarios. To bridge this gap, we introduce EgoScreen-Emotion (ESE), the first benchmark dataset for egocentric screen-view movie emotion understanding. ESE contains 224 movie trailers captured under controlled egocentric screen-view conditions, producing 28,667 temporally aligned key-frames annotated by multiple raters with a confidence-aware multi-label protocol to address emotional ambiguity. We further build a multimodal long-context emotion reasoning framework that models temporal visual evidence, narrative summaries, compressed historical context, and audio cues. Cross-domain experiments reveal a severe domain gap: models trained on cinematic footage drop from 27.99 to 16.69 Macro-F1 when evaluated on realistic egocentric screen-view observations. Training on ESE substantially improves robustness under realistic viewing conditions. Our approach achieves competitive performance compared with strong closed-source multimodal models, highlighting the importance of domain-specific data and long-context multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity
full rationale
The paper introduces a new dataset (ESE with 224 trailers and 28,667 annotated frames) and reports empirical cross-domain results (e.g., Macro-F1 drop from 27.99 to 16.69). No equations, derivations, or parameter-fitting steps are described that could reduce claims to self-definitional or fitted-input patterns. No self-citations or uniqueness theorems are invoked as load-bearing premises. The central claims rest on new data collection and standard evaluation protocols, which are externally falsifiable and independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-rater annotations collected with a confidence-aware multi-label protocol sufficiently resolve emotional ambiguity in movie frames.
Reference graph
Works this paper leans on
-
[1]
In: NeurIPS (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., Ring, R., El-Nouby, A., Tingedah, Z., Zhao, Z., Samangoeei, S., Monteiro, M., Menick, J., Borgeaud, S., Brock, A., Dehghani, M., Kabi, S., Shirzad, S., Mikolov, T., Binkowski, M., Barreira, R., Vinyals, O., Zisser- man, A., Simonyan, K...
2022
-
[2]
Bevbert: Multimodal map pre-training for language-guided navigation,
An, D., Qi, Y., Li, Y., Huang, Y., Wang, L., Tan, T., Shao, J.: Bevbert: Multimodal map pre-training for language-guided navigation. arXiv preprint arXiv:2212.04385 (2022)
-
[3]
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Wu, C., Tan, H., Li, C., Yang, J., Yu, J., Wang, X., Qin, B., Wang, Y., Yan, Z., Feng, Z., Liu, Z., Li, B., Deng, J.: Llava-onevision-1.5: Fully open framework for democratized multimodal training (2025)
2025
-
[4]
Ataallah, K., Gou, C., Abdelrahman, E., Pahwa, K., Ding, J., Elhoseiny, M.: In- finibench: A comprehensive benchmark for large multimodal models in very long video understanding (2024)
2024
-
[5]
In: Conf
Ataallah, K., Bakr, E.M., Ahmed, M., Gou, C., Pahwa, K., Ding, J., Elhoseiny, M.: Infinibench: A benchmark for large multi-modal models in long-form movies and tv shows. In: Conf. Empir. Methods Nat. Lang. Process. (2025)
2025
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X.H., Cheng, Z., Deng, L., Ding, W., Fang, R., Gao, C., et al.: Qwen3-vl technical report (2025)
2025
-
[7]
In: CVPR (2024)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Muya, Z., Zhang, Q., Zhu, X., Lu, L., Li, B., Luo, P., Lu, T., Qiao, Y., Dai, J.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR (2024)
2024
-
[8]
Videgothink: Assessing egocentric video understanding capabilities for embodied ai,
Cheng, S., Fang, K., Yu, Y., Zhou, S., Li, B., Tian, Y., Li, T., Han, L., Liu, Y.: Videgothink: Assessing egocentric video understanding capabilities for embodied ai. arXiv (2024), arXiv:2410.11623
-
[9]
Advances in Neural Information Processing Systems37, 110805– 110853 (2024)
Cheng, Z., Cheng, Z.Q., He, J.Y., Wang, K., Lin, Y., Lian, Z., Peng, X., Haupt- mann, A.: Emotion-llama: Multimodal emotion recognition and reasoning with in- struction tuning. Advances in Neural Information Processing Systems37, 110805– 110853 (2024)
2024
-
[10]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., Bing, L.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv (2024), arXiv:2406.07476
work page internal anchor Pith review arXiv 2024
-
[11]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities (2025)
2025
-
[12]
In: ECCV (2018)
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The EPIC-KITCHENS dataset. In: ECCV (2018)
2018
-
[13]
In: ECCV
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The EPIC-KITCHENS dataset. In: ECCV. pp. 720–736 (2018)
2018
-
[14]
In: Advances in Neural Information Processing Systems (2022) Egocentric Emotion Understanding 17
Dao, T., Fu, D.Y., Ermon, S., Rudra, A., Re, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. In: Advances in Neural Information Processing Systems (2022) Egocentric Emotion Understanding 17
2022
-
[15]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review arXiv 2023
-
[16]
IEEE Trans
Duan, J., Yu, S., Li, T., Zhu, H., Tan, C.: A survey of embodied ai: From simulators to research tasks. IEEE Trans. Emerg. Topics Comput. Intell. (2021)
2021
-
[17]
Cognition & Emotion6(3-4), 169–200 (1992)
Ekman, P.: An argument for basic emotions. Cognition & Emotion6(3-4), 169–200 (1992)
1992
-
[18]
In: ICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP)
Fan, W., Xu, X., Xing, X., Chen, W., Huang, D.: Lssed: a large-scale dataset and benchmark for speech emotion recognition. In: ICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 641–645. IEEE (2021)
2021
-
[19]
In: CVPR (2022)
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, X., Martin, M., Nagarajan, T., Radosavovic, I., Ramakr- ishnan, S.K., Ryan, F., Sharma, J., Wray, M., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: CVPR (2022)
2022
-
[20]
In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., et al.: Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning. In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5021–5028. IEEE (2024)
2024
-
[21]
In: International Conference on Learning Representations (ICLR) (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Chen, W.: Lora: Low-rank adaptation of large language models. In: International Conference on Learning Representations (ICLR) (2022)
2022
-
[22]
In: European Conference on Computer Vision (ECCV) (2020)
Huang, Q., Xiong, Y., Rao, A., Wang, J., Lin, D.: Movienet: A holistic dataset for movie understanding. In: European Conference on Computer Vision (ECCV) (2020)
2020
-
[23]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., Fei-Fei, L.: Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973 (2023)
work page internal anchor Pith review arXiv 2023
-
[24]
Journal of network and computer applications 147, 102423 (2019)
Imani, M., Montazer, G.A.: A survey of emotion recognition methods with em- phasis on e-learning environments. Journal of network and computer applications 147, 102423 (2019)
2019
-
[25]
In: Pro- ceedings of the 28th ACM international conference on multimedia
Jiang, X., Zong, Y., Zheng, W., Tang, C., Xia, W., Lu, C., Liu, J.: Dfew: A large- scale database for recognizing dynamic facial expressions in the wild. In: Pro- ceedings of the 28th ACM international conference on multimedia. pp. 2881–2889 (2020)
2020
-
[26]
IEEE Transactions on Affective Computing3(1), 18–31 (2012)
Koelstra, S., Mühl, C., Soleymani, M., Lee, J.S., Yazdani, A., Ebrahimi, T., Pun, T.,Nijholt,A.,Patras,I.:Deap:Adatabaseforemotionanalysisusingphysiological signals. IEEE Transactions on Affective Computing3(1), 18–31 (2012)
2012
-
[27]
Image and Vision Computing65, 23–36 (2017)
Kossaifi, J., Tzimiropoulos, G., Todorovic, S., Pantic, M.: AFEW-VA database for valence and arousal estimation in-the-wild. Image and Vision Computing65, 23–36 (2017)
2017
-
[28]
Kossaifi,J.,Walecki,R.,Panagakis,Y.,Shen,J.,Schmitt,M.,Ringeval,F.,Han,J., Pandit, V., Schuller, B., Star, K., Hjelm, E., Pantic, M.: Sewa db: A rich database for audio-visual emotion and sentiment research in the wild. IEEE Transactions on Pattern Analysis and Machine Intelligence43(3), 1022–1040 (2019).https: //doi.org/10.1109/TPAMI.2019.2944808
-
[29]
In: CVPRW (2017) 18 Z.Dong et al
Kosti, R., Álvarez, J., Recasens, A., Lapedriza, A.: Emotic: Emotions in context dataset. In: CVPRW (2017) 18 Z.Dong et al
2017
-
[30]
Lei, S., Dong, G., Wang, X., Wang, K., Qiao, R., Wang, S.: Instructerc: Reform- ing emotion recognition in conversation with multi-task retrieval-augmented large language models. arXiv preprint arXiv:2309.11911 (2023)
-
[31]
In: IEEE Int
Li, P., Cao, L., Wu, X.M., Yu, X., Yang, R.: Ugotme: An embodied system for affective human-robot interaction. In: IEEE Int. Conf. Robot. Autom. (2025)
2025
-
[32]
In: NeurIPS (2024)
Lin, W., Feng, Y., Han, W., Jin, T., Zhao, Z., Wu, F., Yao, C., Chen, J.: E3: Exploring embodied emotion through a large-scale egocentric video dataset. In: NeurIPS (2024)
2024
-
[33]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone
Lin, X., Li, S., Li, B., Yan, B., Yan, R., Shen, Z., Wu, C., Miao, Y., Yuan, Y., Shi, Y., He, J., Huang, C., Chen, B., Cai, K.: Physbrain: Human egocentric data as a bridge from vision language models to physical intelligence. arXiv (2026), arXiv:2512.16793
-
[34]
In: CVPR (2024)
Liu, H., Li, C., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR (2024)
2024
-
[35]
Advances in Neural Information Processing Systems36, 46212–46244 (2023)
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems36, 46212–46244 (2023)
2023
-
[36]
IEEE TPAMI43(11), 4009– 4025 (2021)
Martín-Martín, R., Patel, M., Rezatofighi, H., Shenoy, A., Gwak, J., Frankel, E., Sadeghian, A., Savarese, S.: Jrdb: A dataset and benchmark of egocentric robot visual perception of humans in built environments. IEEE TPAMI43(11), 4009– 4025 (2021)
2021
-
[37]
In: Conf
Mathur, L., Liang, P.P., Morency, L.P.: Advancing social intelligence in ai agents: Technical challenges and open questions. In: Conf. Empir. Methods Nat. Lang. Process. (2024)
2024
-
[38]
de Melo, C.M., Gratch, J., Marsella, S., Pelachaud, C.: Social functions of machine emotional expressions. Proc. IEEE111(10), 1353–1372 (2023)
2023
-
[39]
Paiva, A., Leite, I., Boukricha, H., Wachsmuth, I.: Empathy in virtual agents and robots:Asurvey.ACMTrans.Interact.Intell.Syst.7(3),11:1–11:40(2017).https: //doi.org/10.1145/2912150
-
[40]
Emotion-llamav2 and mmeverse: A new framework and benchmark for multimodal emotion understanding,
Peng, X., Chen, J., Cheng, Z., Peng, B., Wu, F., Dong, Y., Tu, S., Hu, Q., Huang, H., Lin, Y., et al.: Emotion-llamav2 and mmeverse: A new framework and bench- mark for multimodal emotion understanding. arXiv preprint arXiv:2601.16449 (2026)
-
[41]
In: Annu
Poria, S., Hazarika, D., Majumder, N., Naik, G., Cambria, E., Mihalcea, R.: Meld: A multimodal multi-party dataset for emotion recognition in conversations. In: Annu. Meet. Assoc. Comput. Linguistics. pp. 527–536 (2018)
2018
-
[42]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[43]
In: ACM Symposium on User Interface Soft- ware and Technology (UIST) (2024)
Rao, A., Chou, J.P., Agrawala, M.: Scriptviz: A visualization tool to aid scriptwrit- ing based on a large movie database. In: ACM Symposium on User Interface Soft- ware and Technology (UIST) (2024)
2024
-
[44]
Rawal, R., Saifullah, K., Basri, R., Jacobs, D., Somepalli, G., Goldstein, T.: Cinepile: A long video question answering dataset and benchmark (2024)
2024
-
[45]
In: CVPR (2018)
Sigurdsson, G.A., Gupta, A., Schmid, C., Farhadi, A., Alahari, K.: Actor and observer: Joint modeling of first and third-person videos. In: CVPR (2018)
2018
-
[46]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025) Egocentric Emotion Understanding 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[48]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Wang, X., Xu, S., Shan, X., Zhang, Y., Diao, M., Duan, X., Huang, Y., Liang, K., Ma, Z.: Cinetechbench: A benchmark for cinematographic technique understanding and generation (2025)
2025
-
[50]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report. arXiv (2025), arXiv:2503.20215
work page internal anchor Pith review arXiv 2025
-
[51]
IEEE Transactions on Pattern Analysis and Machine Intelligence 47(3), 1877–1893 (2024)
Xu, P., Shao, W., Zhang, K., Gao, P., Liu, S., Lei, M., Meng, F., Huang, S., Qiao, Y., Luo, P.: Lvlm-ehub: A comprehensive evaluation benchmark for large vision- language models. IEEE Transactions on Pattern Analysis and Machine Intelligence 47(3), 1877–1893 (2024)
2024
-
[52]
In: CVPR
Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., Wang, P., Zhou, Z., Xie, B., Wang, Z., Ouyang, B., Lin, Z., Cominelli, M., Cai, Z., Li, B., Zhang, Y., Zhang, P., Hong, F., Widmer, J., Gringoli, F., Yang, L., Liu, Z.: Egolife: Towards egocentric life assistant. In: CVPR. pp. 28885–28900 (2025)
2025
-
[53]
In: ICCV (2023)
Yang, J., Huang, Q., Ding, T., Lischinski, D., Cohen-Or, D., Huang, H.: Emoset: A large-scale visual emotion dataset with rich attributes. In: ICCV (2023)
2023
-
[54]
arXiv preprint arXiv:2501.09502 (2025)
Yang, Q., Bai, D., Peng, Y.X., Wei, X.: Omni-emotion: Extending video mllm with detailed face and audio modeling for multimodal emotion analysis. arXiv preprint arXiv:2501.09502 (2025)
-
[55]
In: Proceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers)
Zadeh, A.B., Liang, P.P., Poria, S., Cambria, E., Morency, L.P.: Multimodal lan- guage analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In: Proceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers). pp. 2236–2246 (2018)
2018
-
[56]
arXiv preprint arXiv:2501.15111 , year=
Zhao, J., Yang, Q., Peng, Y., Bai, D., Yao, S., Sun, B., Chen, X., Fu, S., Wei, X., Bo, L., et al.: Humanomni: A large vision-speech language model for human-centric video understanding. arXiv preprint arXiv:2501.15111 (2025)
-
[57]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhou, G., Hong, Y., Wu, Q.: Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 7641–7649 (2024)
2024
-
[58]
a wheelchair user appears in a crowded bar ...soldiers prepare for military action ...blue-skinned aliens stand on a bat- tlefield while soldiers panic in a control room
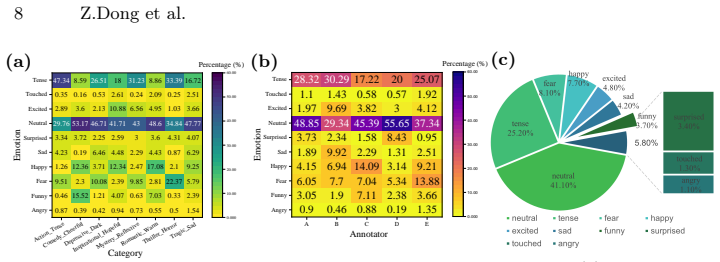
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 20 Z.Dong et al. Supplementary Material A Additional Dataset Statistics To further analyze the annotation ...
2023
-
[59]
For Qwen2.5-Omni-7B, we use the Egocentric Emotion Understanding 27 SDPA attention [47] implementation, while for Qwen3-VL-8B, we use FlashAt- tention [14]
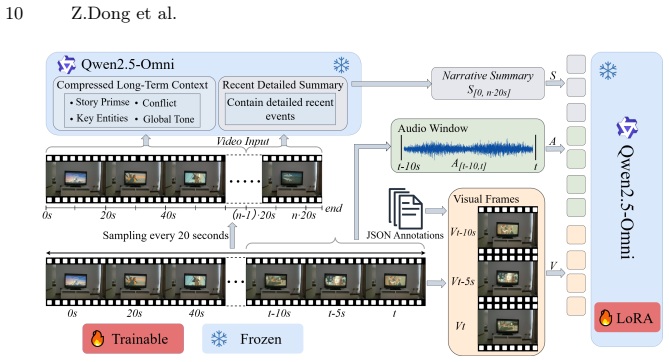
We adopt bfloat16 mixed-precision training and enable gradient checkpoint- ing to reduce GPU memory consumption. For Qwen2.5-Omni-7B, we use the Egocentric Emotion Understanding 27 SDPA attention [47] implementation, while for Qwen3-VL-8B, we use FlashAt- tention [14]. Model checkpoints are evaluated and saved at the end of each epoch. All experiments are...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.