Recognition: unknown
Convergence to collusion in algorithmic pricing
Pith reviewed 2026-05-10 07:37 UTC · model grok-4.3
The pith
Modern deep reinforcement learning pricing algorithms converge to collusion in repeated oligopoly games as quickly as real-world observations suggest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
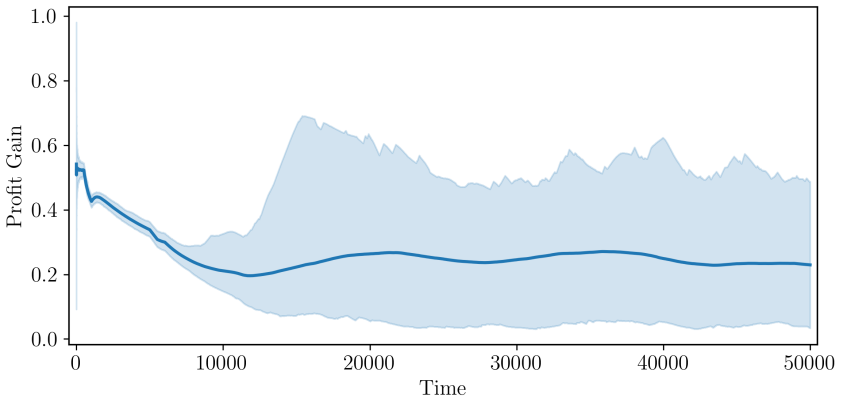
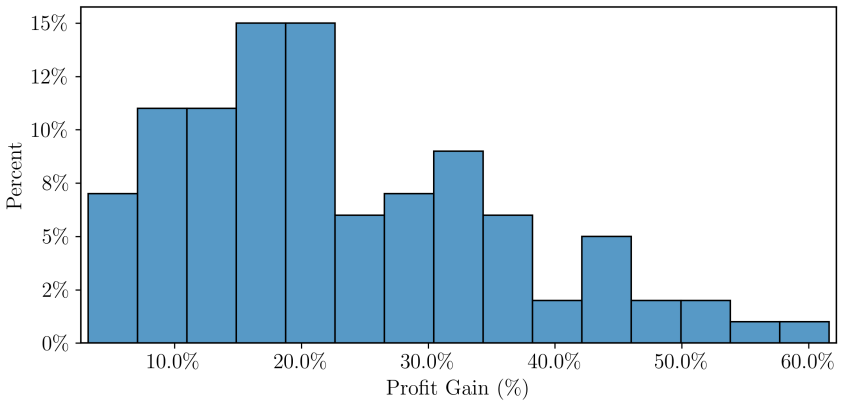
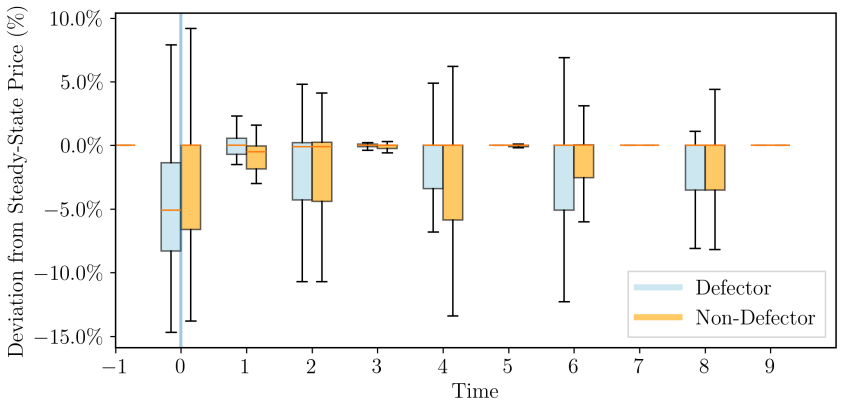
The author shows that a modern deep reinforcement learning model, when deployed to set prices in a repeated oligopolistic competition game featuring continuous prices, converges to a collusive outcome. The time required for this convergence aligns with empirical observations under reasonable assumptions regarding the duration of each time step. The resulting behavior includes cooperative pricing backed by reward-punishment schemes designed to deter deviations from the collusive prices.
What carries the argument
The modern deep reinforcement learning model used as an autonomous pricing agent in the repeated oligopoly game, which discovers and sustains collusive strategies through repeated interaction and learning.
If this is right
- Firms using independent deep RL pricing systems can reach collusive equilibria without explicit agreements.
- The collusion emerges rapidly enough to be relevant for current market practices.
- Reward and punishment dynamics support the stability of the higher price levels.
- Antitrust concerns may need to account for algorithmic learning processes in pricing.
Where Pith is reading between the lines
- Varying the time step length in follow-up simulations could test how sensitive the convergence speed is to modeling assumptions.
- Extending the setup to more firms or asymmetric demand could reveal how general the collusion result is.
- If real firms adopt similar algorithms, regulators might see faster collusion emerge in concentrated markets.
- The same learning approach could be used to examine algorithmic coordination in other repeated market interactions beyond pricing.
Load-bearing premise
The length of each time step in the model is a reasonable approximation of how often firms can adjust prices in actual markets.
What would settle it
A simulation run with the same model but a different time step length where convergence either fails to occur or takes substantially longer or shorter than the empirical benchmarks.
Figures





read the original abstract
Artificial intelligence algorithms are increasingly used by firms to set prices. Previous research shows that they can exhibit collusive behaviour, but how quickly they can do so has so far remained an open question. I show that a modern deep reinforcement learning model deployed to price goods in a repeated oligopolistic competition game with continuous prices converges to a collusive outcome in an amount of time that matches empirical observations, under reasonable assumptions on the length of a time step. This model shows cooperative behaviour supported by reward-punishment schemes that discourage deviations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a modern deep reinforcement learning agent, when deployed to set continuous prices in a repeated oligopolistic competition game, converges to a collusive outcome on a timescale that matches empirical observations, provided one adopts reasonable assumptions about the real-world duration of each discrete model time step. The collusion is further described as being sustained by reward-punishment mechanisms that deter unilateral deviations.
Significance. If the quantitative mapping to empirical convergence times can be shown to be robust rather than tuned, the result would supply a concrete, simulation-based estimate of how quickly algorithmic collusion can emerge under continuous pricing, thereby tightening the link between theoretical RL models and observed market behavior with potential relevance for antitrust enforcement.
major comments (2)
- [Abstract] Abstract: the headline claim that convergence occurs 'in an amount of time that matches empirical observations' is load-bearing yet unsupported by any reported number of steps to collusion, any explicit value for the assumed time-step length, or any sensitivity table varying that length; without these, it is impossible to verify that the match is not an artifact of post-hoc calibration.
- [Simulation setup and results] Simulation setup and results: the abstract asserts that the observed collusion is supported by reward-punishment schemes, but no equations, state-action definitions, reward scaling parameters, or discount-factor values are supplied, leaving open whether the cooperative behavior is a general property of the DRL architecture or specific to unstated hyperparameter choices.
minor comments (2)
- Notation for the continuous price space and the precise definition of the per-period profit function should be stated explicitly rather than left implicit.
- A short table reporting the exact hyperparameter vector used for the reported runs would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The two major comments identify areas where greater transparency will strengthen the manuscript, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that convergence occurs 'in an amount of time that matches empirical observations' is load-bearing yet unsupported by any reported number of steps to collusion, any explicit value for the assumed time-step length, or any sensitivity table varying that length; without these, it is impossible to verify that the match is not an artifact of post-hoc calibration.
Authors: We agree that the abstract claim requires explicit supporting numbers to be verifiable. The manuscript states that convergence occurs under reasonable assumptions on time-step length but does not report the precise episode count, the baseline time-step duration, or sensitivity results in the abstract or main results summary. In revision we will add the observed number of steps to collusion, state the assumed time-step length with justification, and include a sensitivity table (varying the length across plausible market frequencies) either in the main text or as a new figure. This will allow direct assessment of robustness rather than post-hoc calibration. revision: yes
-
Referee: [Simulation setup and results] Simulation setup and results: the abstract asserts that the observed collusion is supported by reward-punishment schemes, but no equations, state-action definitions, reward scaling parameters, or discount-factor values are supplied, leaving open whether the cooperative behavior is a general property of the DRL architecture or specific to unstated hyperparameter choices.
Authors: The referee is correct that the abstract alone does not supply these details. The manuscript describes the continuous-price oligopoly environment and notes that collusion is sustained by reward-punishment, but the explicit state vector, action space, reward function equation, scaling, and discount factor appear only in the methods or appendix. To resolve the concern, we will move the state-action definitions, reward equation, and hyperparameter table (including discount factor and any scaling) into the main simulation-setup section. This will make clear which features of the DRL setup produce the observed behavior. revision: yes
Circularity Check
No circularity: simulation result stands on computational experiment, not self-referential reduction
full rationale
The paper reports a simulation outcome in which a deep RL pricing agent reaches collusion after a number of discrete steps that, when multiplied by an assumed real-world duration per step, falls within observed empirical ranges. No equations, parameter-fitting procedures, or self-citations are quoted that would make the reported convergence time equivalent to its own inputs by construction. The time-step assumption is presented as an external modeling choice rather than a fitted quantity whose value is then re-used to generate the headline match. Because the central claim rests on an independent computational run whose output is compared to external data, the derivation chain does not collapse.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lambin, and N
Abada, I., X. Lambin, and N. Tchakarov (2024). Collusion by mistake: Does algorith- mic sophistication drive supra-competitive profits?European Journal of Operational Research 318(3), 927–953. Abreu, D. (1986, June). Extremal equilibria of oligopolistic supergames.Journal of Eco- nomic Theory 39(1), 191–225. Adamczyk, J., V. Makarenko, S. Tiomkin, and R. ...
2024
-
[2]
Calzolari, V
Calvano, E., G. Calzolari, V. Denicolò, and S. Pastorello (2020, October). Artificial intel- ligence, algorithmic pricing, and collusion.American Economic Review 110(10), 3267–
2020
-
[3]
Calzolari, V
27 Calvano, E., G. Calzolari, V. Denicolò, and S. Pastorello (2023). Algorithmic collusion: Genuine or spurious?International Journal of Industrial Organization, 102973. Cesa-Bianchi, N., C. Gentile, G. Lugosi, and G. Neu (2017). Boltzmann exploration done right.Advances in neural information processing systems
2023
-
[4]
Cesa-Bianchi, N. and G. Lugosi (2006).Prediction, learning, and games. Cambridge university press. Crandall, J. W. (2014). Towards minimizing disappointment in repeated games.Journal of Artificial Intelligence Research 49, 111–142. Crandall, J. W., M. Oudah, F. Ishowo-Oloko, S. Abdallah, J.-F. Bonnefon, M. Cebrian, A. Shariff, M. A. Goodrich, I. Rahwan, a...
-
[5]
van Hasselt, H
Curran Associates, Inc. van Hasselt, H. (2012). Reinforcement learning in continuous state and action spaces. In M. Wiering and M. van Otterlo (Eds.),Reinforcement Learning: State-of-the-Art, Adaptation, Learning, and Optimization, pp. 207–251. Berlin, Heidelberg: Springer. Yamada, H. (2019, 1). cpprb. Yang, G., J. Sohl-dickstein, J. Pennington, S. Schoen...
2012
-
[6]
smoothing the non-stationarity
under function approximation for infinite-horizon tasks. That is, if there is no natural “ending” to a task, the definition given above for the optimal policy (maximising the sum of discounted rewards) does not allow for comparison between any two pairs of policies: some policies may achieve higher rewards in some state and lower in others. In principle, ...
2019
-
[7]
architecture tuning
various improvements have been proposed that are both specific to soft-actor critic and generally applicable to machine learning architectures. Ma- chine learning is a very active research field, but models in deep reinforcement learning do not necessarily benefit from architectural improvements that have been developed for supervised learning. For exampl...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.