Recognition: unknown
Markov embedding of ranked unlabelled evolutionary trees and its applications
Pith reviewed 2026-05-10 07:30 UTC · model grok-4.3
The pith
A Markov chain embedding of ranked unlabelled trees reduces the state space enough to compute all Fréchet means exactly and to obtain arbitrary-order moments of F-matrices under any bifurcating coalescent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Markov chain embedding of ranked unlabelled trees preserves topology, ranking and the probability measure of any time-homogeneous bifurcating coalescent, thereby allowing Fréchet means to be recovered from the reduced chain, joint laws of balance indices to be read off from absorption probabilities of a discrete phase-type process, and all moments of the F-matrix to be obtained in closed form for arbitrary order.
What carries the argument
The Markov chain embedding, which compresses each ranked unlabelled tree into a sequence of states that record only the necessary coalescence information while keeping the original topology and ranking recoverable.
If this is right
- All Fréchet means of any sample become computable by standard algorithms on the reduced chain rather than by exhaustive search or mixed-integer programming.
- The joint distribution of any finite collection of tree balance indices is given explicitly by the absorption probabilities of the associated phase-type process.
- Moments of every order of every entry of the F-matrix follow in closed form for every time-homogeneous bifurcating coalescent model.
- Three new tests for neutrality can be evaluated exactly and exhibit higher power than earlier moment-based tests on simulated data.
Where Pith is reading between the lines
- Because the embedding is defined for any time-homogeneous bifurcating coalescent, the same machinery could be applied to compare observed trees against any fixed neutral model without resimulating the full tree space.
- The reduced state space may make it feasible to compute other summary statistics that previously required Monte Carlo, provided those statistics can be expressed as functions of the embedded process.
- The phase-type representation separates the combinatorial structure from the waiting-time distribution, so extensions to models with time-inhomogeneous or selection-driven rates would require only a change in the intensity matrix while keeping the same embedding.
Load-bearing premise
The embedding must map trees to states in such a way that every topological, ranking and distributional property needed for Fréchet means and phase-type results is exactly preserved when the results are mapped back to the original trees.
What would settle it
For any small number of leaves, enumerate all ranked unlabelled trees, compute the Fréchet mean of a sample directly, and compare it with the mean obtained after running the embedded Markov chain algorithm; a mismatch on even one sample falsifies exact transfer of the means.
Figures

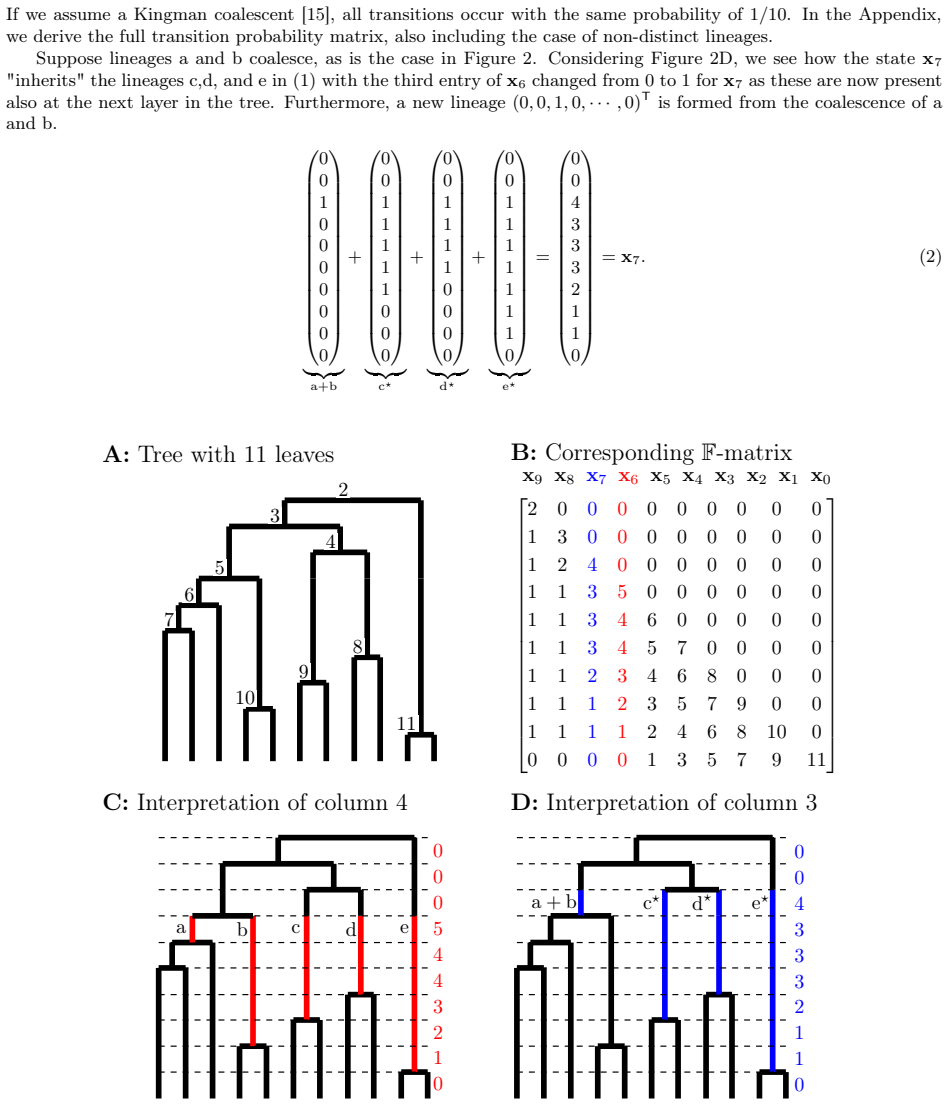



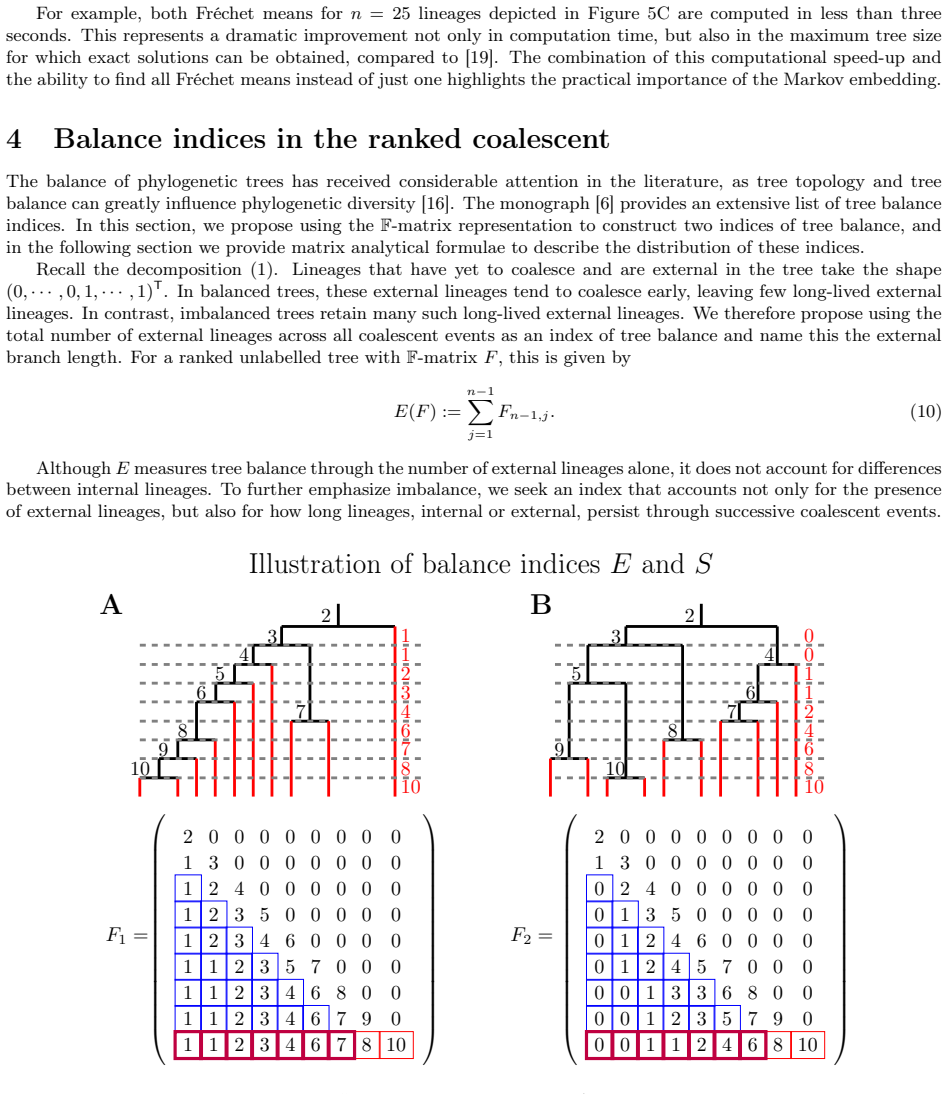


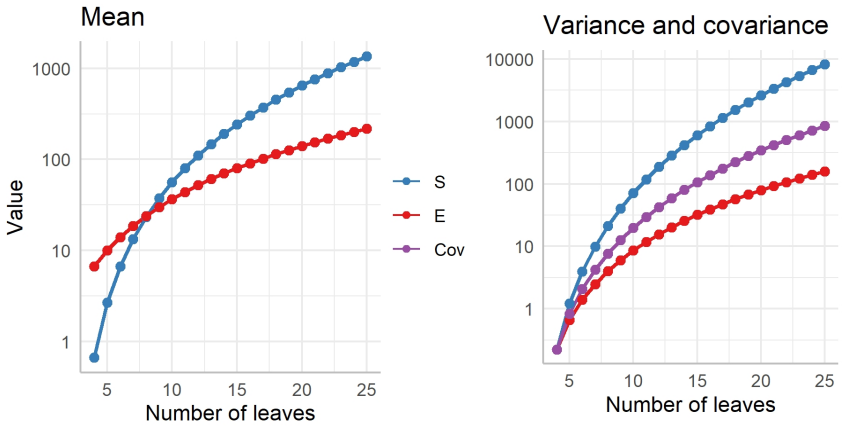



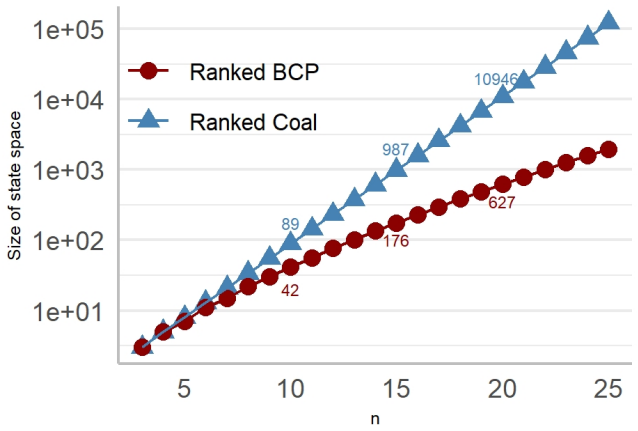

read the original abstract
Rooted bifurcating trees are mathematical objects used to model evolutionary relationships and arise naturally in both coalescent theory and phylogenetics. Recent numerical representations of tree topologies, known as F-matrices, allow for summarizing a sample of trees via Fr\'echet means and provide new measures of tree balance. However, the number of ranked unlabelled trees grows super-exponentially with the number of leaves. This makes computation intensive and current methods rely on mixed integer programming and simulation-based methods. Moreover, F-matrices are difficult to interpret, and their distribution is only described in terms of first- and second-order moments under neutral branching. In this paper, we introduce a Markov chain embedding of ranked and unlabelled trees that drastically decreases the size of the state space. Leveraging this embedding, we develop an algorithm that efficiently computes all Fr\'echet means and use discrete phase-type theory to obtain the joint distribution of tree balance indices. We also use discrete phase-type theory to generalize previous results regarding moments of F-matrices to arbitrary order for any time homogeneous and bifurcating coalescent model. Using this framework, we construct three tests for neutrality and demonstrate their improved power compared to previous methods on simulated data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Markov chain embedding of ranked unlabelled bifurcating trees that reduces the state space size. It uses this embedding to develop an algorithm for computing all Fréchet means of F-matrices, applies discrete phase-type theory to obtain the joint distribution of tree balance indices, generalizes moments of F-matrices to arbitrary order under any time-homogeneous bifurcating coalescent, and constructs three neutrality tests that show improved power on simulated data.
Significance. If the embedding is shown to be faithful (i.e., a structure-preserving lumpable aggregation that exactly reproduces the original distributions and statistics), the work would enable exact, scalable computations of Fréchet means and higher-order moments in a space whose size grows super-exponentially, replacing simulation or MIP approaches. The phase-type framework for balance indices and arbitrary-order F-matrix moments, together with the new neutrality tests, would constitute a substantive methodological advance for coalescent-based phylogenetics.
major comments (3)
- [Section describing the Markov embedding (likely §3)] The central claim that the embedding permits exact transfer of Fréchet means, joint balance-index distributions, and arbitrary-order F-matrix moments back to the original ranked-unlabelled tree space requires an explicit proof that the reduced chain is Markovian under any time-homogeneous bifurcating coalescent and that the map preserves the relevant topological, ranking, and distributional properties. This verification is load-bearing for all three main applications and is not supplied by the abstract alone.
- [Section on Fréchet means algorithm] The algorithm for computing all Fréchet means via the embedding must be accompanied by a demonstration that the reduced-state Fréchet mean coincides with the original-space mean; if distinct trees with different F-matrices map to the same embedded state, the computed means will be incorrect.
- [Section on phase-type moments of F-matrices] The generalization of F-matrix moments to arbitrary order via phase-type theory assumes the embedding induces the correct absorption-time distributions; a concrete check (e.g., recovery of known first- and second-order moments as special cases) is needed to confirm the arbitrary-order formulae are valid.
minor comments (2)
- Notation for the embedded states and the transition matrix should be introduced with a small illustrative example (n=4 or n=5) to make the reduction concrete.
- The three neutrality tests are described only at a high level; explicit definitions of the test statistics and their null distributions under the embedded chain would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the requirements for rigorous validation of the embedding. We address each major comment below and will revise the manuscript to incorporate the requested proofs and verifications.
read point-by-point responses
-
Referee: [Section describing the Markov embedding (likely §3)] The central claim that the embedding permits exact transfer of Fréchet means, joint balance-index distributions, and arbitrary-order F-matrix moments back to the original ranked-unlabelled tree space requires an explicit proof that the reduced chain is Markovian under any time-homogeneous bifurcating coalescent and that the map preserves the relevant topological, ranking, and distributional properties. This verification is load-bearing for all three main applications and is not supplied by the abstract alone.
Authors: We agree that an explicit, self-contained proof is necessary. Section 3 defines the embedding via equivalence classes on ranked unlabelled trees and states that the resulting chain is Markovian under time-homogeneous bifurcating coalescents, but the lumpability argument is only sketched. In the revision we will add a dedicated subsection containing a formal proof of lumpability (using the standard criterion on transition probabilities) together with verification that the embedding map preserves the relevant topological rankings, F-matrix values, and absorption-time distributions. revision: yes
-
Referee: [Section on Fréchet means algorithm] The algorithm for computing all Fréchet means via the embedding must be accompanied by a demonstration that the reduced-state Fréchet mean coincides with the original-space mean; if distinct trees with different F-matrices map to the same embedded state, the computed means will be incorrect.
Authors: The embedding is constructed so that states aggregate trees sharing identical F-matrices (or identical contributions to the Fréchet objective under the chosen metric). We will augment the algorithm section with a short lemma proving that the Fréchet mean computed on the embedded chain maps back to a valid Fréchet mean in the original space, by showing that the embedding is isometric with respect to the distance used in the Fréchet definition and that no two trees with distinct F-matrices are collapsed into the same state. revision: yes
-
Referee: [Section on phase-type moments of F-matrices] The generalization of F-matrix moments to arbitrary order via phase-type theory assumes the embedding induces the correct absorption-time distributions; a concrete check (e.g., recovery of known first- and second-order moments as special cases) is needed to confirm the arbitrary-order formulae are valid.
Authors: We will insert a verification subsection that recovers the known first- and second-order moments of the F-matrix entries as special cases of the general phase-type moment formula and compares them numerically and algebraically with the expressions previously derived in the literature. This check will be performed both for the Kingman coalescent and for a non-Kingman time-homogeneous bifurcating model to confirm correctness of the arbitrary-order extension. revision: yes
Circularity Check
No circularity: novel embedding construction applies established phase-type and Fréchet tools without reduction to inputs
full rationale
The paper defines a new Markov chain embedding of ranked unlabelled trees as an original combinatorial construction that reduces state space while preserving topology, ranking, and distributional properties. It then applies standard discrete phase-type theory to derive joint distributions of balance indices and arbitrary-order moments of F-matrices, plus an algorithm for Fréchet means. No derivation step equates a claimed result to a fitted parameter, self-citation, or ansatz by construction; the embedding is introduced independently and the transfer of results is asserted via structure preservation rather than tautological redefinition. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Markov chains can be embedded to represent ranked unlabelled tree topologies while preserving necessary properties
- standard math Discrete phase-type distributions apply to the embedded Markov process for deriving moments and joint distributions
invented entities (1)
-
Markov chain embedding of ranked unlabelled trees
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bladt, M. and Nielsen, B.F. Matrix-exponential distibutions in applied probability. Springer, 2017. https://doi.org/10.1007/978-1-4939-7049-0
-
[2]
Blum, M.G.B and François, O. Which Random Processes Describe the Tree of Life? A Large-Scale Study of Phylogenetic Tree Imbalance.Systematic Biology55.4 (2006), 685–691.https://doi.org/1 0.1080/10635150600889625
2006
-
[3]
Coljin, C. and Plazzotta, G. A Metric on Phylogentic Tree Shapes.Systematic Biology67.1 (2018), 113–126.https://doi.org/10.1093/sysbio/syx046
-
[4]
Disanto, F. and Wiehe, T. Exact enumeration of cherries and pitchforks in ranked trees under the coalescent model.Mathematical Biosciences242.2 (2013), 195–200.https://doi.org/10.1016/j.mb s.2013.01.010
-
[5]
Drummond, A.J. and Suchard, M.A. Fully Bayesian tests of neutrality using genealogical summary statistics.BMC Genet9.68 (2008).https://doi.org/10.1186/1471-2156-9-68. 25
-
[6]
Fishcer, M. et al. Tree Balance Indices - A Comprehensive Survey. Springer International Publishing, 2023.https://doi.org/10.1007/978-3-031-39800-1
-
[7]
Forney, G.D. The Viterbi Algorithm.Proceedings of IEEE61.3 (1973), 268–278.https://doi.org/1 0.1109/PROC.1973.9030
-
[8]
Les éléments aléatoires de nature quelconque dans un espace distancié
Fréchet, Maurice. Les éléments aléatoires de nature quelconque dans un espace distancié. fr.Annales de l’institut Henri Poincaré10.4(1948),215–310.https://www.numdam.org/item/AIHP_1948__10_4_215_0/
1948
-
[9]
Gurobi Optimization, LLC.Gurobi Optimizer Reference Manual. 2024. https://www.gurobi.com
2024
-
[10]
Hardy, G.H. and Ramanujan, S. Asymptotic formulae in combinatory analysis.Proc Lond Math Soc Second Seriess2-17 (1918), 75–115.https://doi.org/10.1112/plms/s2-17.1.75
-
[11]
Hobolth, A., Bladt, M., and Andersen, L.N. Multivariate phase-type theory for the site frequency spectrum.Journal of Mathematical Biology83.63 (2021).https://doi.org/10.1007/s00285-021-0 1689-w
-
[12]
Hobolth, A., Siri-Jégousse, A., and Bladt, M. Phase-type distributions in population genetics.Theo- retical Population Biology127 (2019), 16–32.https://doi.org/10.1016/j.tpb.2019.02.001
-
[13]
Kayondo, H.W., Ssekagiri, A., Nabakooza, G., et al. Employing phylogenetic tree shape statistics to resolve the underlying host population structure.BMC Bioinformatics22 (2021).https://doi.org /10.1186/s12859-021-04465-1
-
[14]
Distance metrics for ranked evolutionary trees.Proc
Kim, J., Rosenberg, N.A., and Palacios, J.A. Distance metrics for ranked evolutionary trees.Proc. Nat. Acad. Sci.117.46 (2020), 28876–86.https://doi.org/10.1073/pnas.1922851117
-
[15]
The Coalescent.Stochastic Processes and Their Applications13 (1982), 235–248
Kingman, J.F.C. The Coalescent.Stochastic Processes and Their Applications13 (1982), 235–248. https://doi.org/10.1016/0304-4149(82)90011-4
-
[16]
Maliet, O., Gascuel, M., and Lambert, A. Ranked Tree Shapes, Nonrandom Extinction, and the Loss of Phylogenetic Diversity.Systematic Biology67.6 (2018), 1025–1040.https://doi.org/10.1093/sy sbio/syy030
work page doi:10.1093/sy 2018
-
[17]
Order statistics and multivariate discrete phase-type distributions
Navarro, A.C. “Order statistics and multivariate discrete phase-type distributions”. PhD thesis. Tech- nical University of Denmark, 2019
2019
-
[18]
Rivas-González, I., Andersen, L.N., and Hobolth, A. PhaseTypeR: an R package for phase-type distri- butions in population genetics.Journal of Open Source Software8.82 (2023), 5054.https://doi.org /10.21105/joss.05054
-
[19]
Samyak, R and Palacios, J.A. Statistical summaries of unlabelled evolutionary trees.Biometrika111.1 (2024), 171–193.https://doi.org/10.1093/biomet/asad025
-
[20]
Sloane, N.J.A. The on-line encyclopedia of integer sequences.Notices American Mathematical Society (2003).https://doi.org/10.48550/arXiv.1805.10343
-
[21]
Soewongsono, A.C., Diao, J., Stark, T., et al. Matrix-analytic Methods for the Evolution of Species Trees, Gene Trees, and Their Reconciliation.Methodology and Computing in Applied Probability27.9 (2025).https://doi.org/10.1007/s11009-025-10135-z
-
[22]
Statistical method for testing the neutral mutation hypothesis by DNA polymorphism
Tajima, F. Statistical method for testing the neutral mutation hypothesis by DNA polymorphism. Genetics123.3 (1989), 585–95.https://doi.org/10.1093/genetics/123.3.585
-
[23]
R Foundation for Statistical Computing
Team, R Core.R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria, 2024. https://www.R-project.org/
2024
-
[24]
Wakeley,J.CoalescentTheory:AnIntroduction.GreenwoodVillage(Colorado):RobertsandCompany Publishers, 2008
2008
-
[25]
Hidden Markov Models for Time Series - An Intro- duction Using R
Zucchini, W., MacDonald, I.L., and Langrock, R. Hidden Markov Models for Time Series - An Intro- duction Using R. Taylor and Francis, 2016.https://doi.org/10.1201/9781420010893. 26
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.