0
Writer monads automate MCMC kernel composition
gemlib.mcmc: composable kernels for Metropolis-within-Gibbs sampling schemes
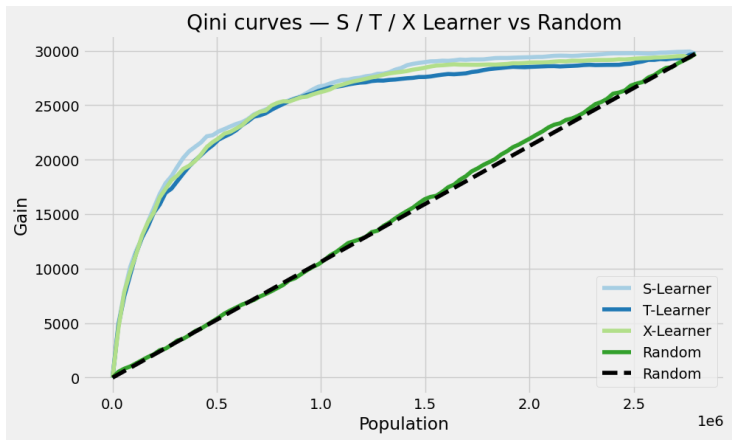
Researchers chain parameter-estimation and data-augmentation steps for epidemic models with less manual coding while keeping statistical rig
 full image
full image
abstract click to expand
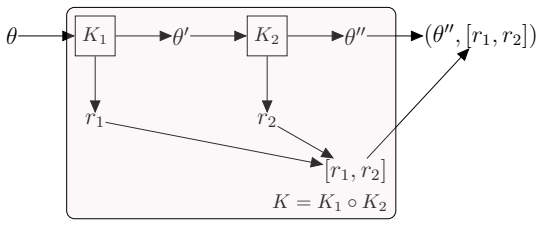
State-transition models are essential across epidemiology and ecology, but statistical inference remains challenging owing to high-dimensional latent state spaces, temporal dependence, and intractable likelihood functions. Bayesian inference via Markov Chain Monte Carlo (MCMC) enables joint estimation of model parameters and missing event times through data augmentation, but Metropolis-within-Gibbs (MWG) schemes that combine multiple specialised kernels are notoriously difficult to implement. Current probabilistic programming frameworks face a trade-off: automation sacrifices extensibility, whilst flexibility demands substantial implementation overhead. This divide has created a software landscape characterised by tightly coupled, model-specific implementations that resist reuse and extension. We introduce gemlib.mcmc, an MCMC module designed to bridge methodological and applied communities through principled, composable kernel abstractions. The framework employs writer monads from category theory to formalise kernel composition, enabling seamless integration of parameter-estimation and data-augmentation kernels without manual state management. Built on JAX and TensorFlow Probability for high-performance computation, gemlib.mcmc provides an ergonomic interface -- leveraging Python's right-shift operator for intuitive kernel chaining -- whilst maintaining statistical rigour and transparency. Developers can extend the library by implementing only two methods; composition and hardware acceleration are automated. We demonstrate the framework through parameter inference on partially observed epidemic models, showing how complex inference algorithms can be expressed concisely and reused across applications. By reducing implementation burden we provide access to sophisticated MCMC methods and enable applied researchers to employ state-of-the-art algorithms without reimplementation overhead.