Recognition: unknown
Making Image Editing Easier via Adaptive Task Reformulation with Agentic Executions
Pith reviewed 2026-05-10 08:19 UTC · model grok-4.3
The pith
Reformulating vague image editing instructions into adaptive operation sequences with an MLLM agent lifts performance without changing the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A large portion of image editing failures stem not from insufficient model capacity, but from poorly formulated editing tasks such as those involving small targets, implicit spatial relations, or under-specified instructions. The proposed adaptive task reformulation framework transforms the original image-instruction pair into a sequence of operations dynamically determined and executed by an MLLM agent through analysis, routing, reformulation, and feedback-driven refinement, producing consistent improvements without modifying the underlying editing model.
What carries the argument
The MLLM agent that performs analysis, routing, reformulation, and feedback-driven refinement to turn an original editing request into a tailored sequence of operations.
If this is right
- Editing performance can be raised by matching task formulation to the model's effective operating regime rather than by scaling model size.
- Gains appear without any retraining or architectural changes to the base editing models.
- The method produces especially large benefits on cases with small targets, implicit relations, or vague instructions.
- Task reformulation emerges as a critical but previously underexplored lever for reliable image editing.
Where Pith is reading between the lines
- The same reformulation approach could be tested on related generative tasks such as text-to-image synthesis or video editing where instruction clarity also matters.
- It implies that robustness to varied prompt styles may be more valuable than raw generative power for practical deployment.
- Hybrid systems might pair lightweight agents for formulation with specialized executors for pixel-level changes.
Load-bearing premise
That most editing failures are caused by how the task is stated rather than by limits inside the generative model itself.
What would settle it
Running the same benchmarks after applying the reformulation and observing no improvement, or finding that well-reformulated tasks still fail at rates comparable to the original instructions.
Figures











read the original abstract
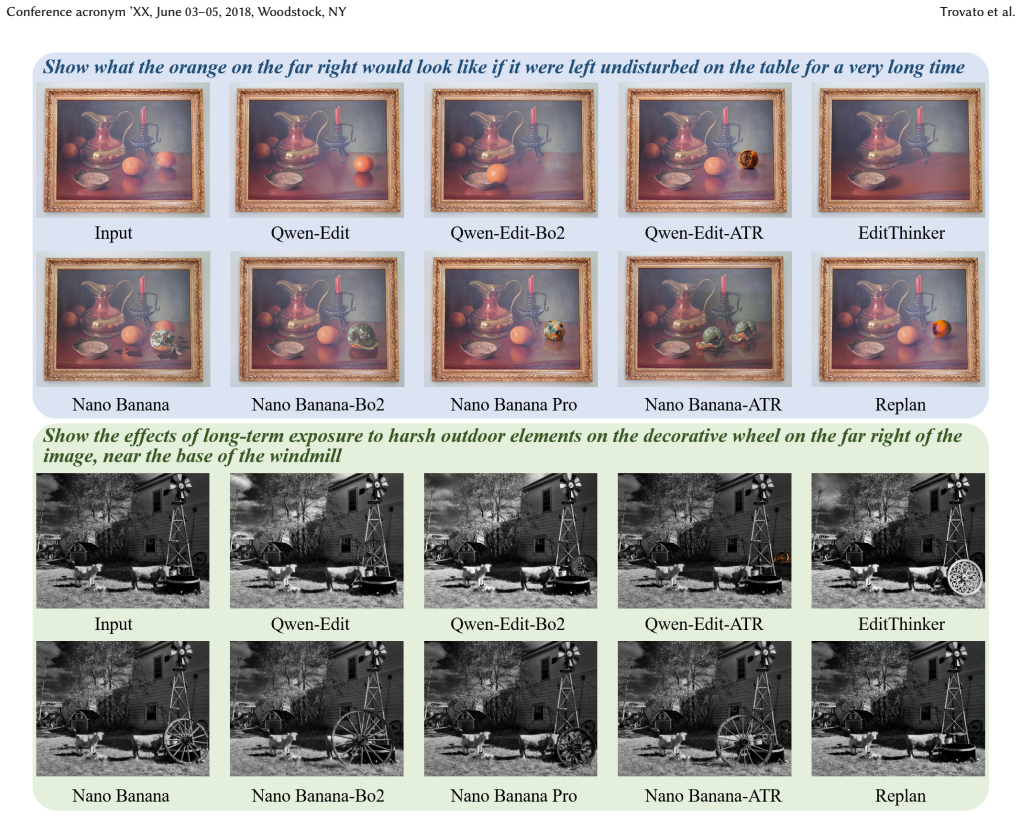
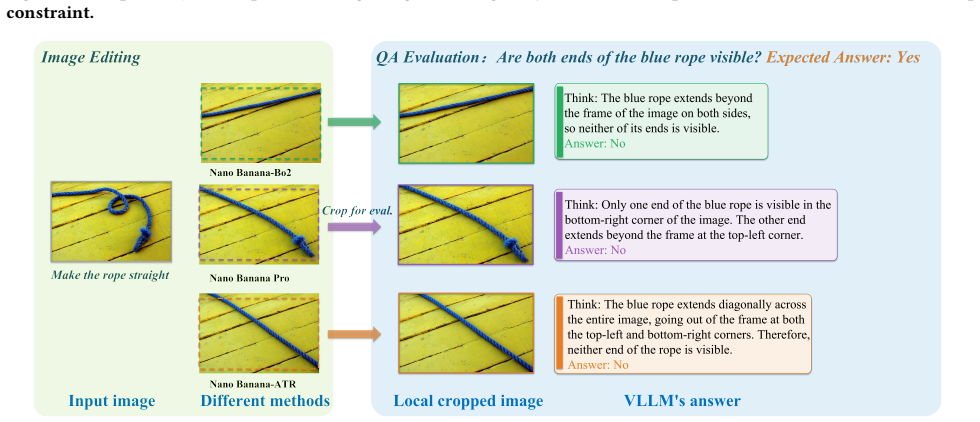
Instruction guided image editing has advanced substantially with recent generative models, yet it still fails to produce reliable results across many seemingly simple cases. We observe that a large portion of these failures stem not from insufficient model capacity, but from poorly formulated editing tasks, such as those involving small targets, implicit spatial relations, or under-specified instructions. In this work, we frame image editing failures as a task formulation problem and propose an adaptive task reformulation framework that improves editing performance without modifying the underlying model. Our key idea is to transform the original image-instruction pair into a sequence of operations that are dynamically determined and executed by a MLLM agent through analysis, routing, reformulation, and feedback-driven refinement. Experiments on multiple benchmarks, including ImgEdit, PICA, and RePlan, across diverse editing backbones such as Qwen Image Edit and Nano Banana, show consistent improvements, with especially large gains on challenging cases. These results suggest that task reformulation is a critical but underexplored factor, and that substantial gains can be achieved by better matching editing tasks to the effective operating regime of existing models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instruction-guided image editing failures often stem from poorly formulated tasks (e.g., small targets, implicit relations, under-specified instructions) rather than model capacity limits. It introduces an adaptive task reformulation framework in which an MLLM agent performs analysis, routing, reformulation, and feedback-driven refinement to convert the original image-instruction pair into a dynamic sequence of operations executed by a fixed editing backbone. Experiments across ImgEdit, PICA, and RePlan benchmarks with backbones including Qwen Image Edit and Nano Banana are reported to yield consistent improvements, with larger gains on hard cases.
Significance. If the reported gains are reproducible and properly controlled, the work is significant because it reframes editing performance as a task-formulation problem solvable by an additive agent layer rather than by retraining or scaling the base model. This agentic pipeline (analysis-routing-reformulation-feedback) is a concrete, model-agnostic contribution that could be applied to other generative tasks. The emphasis on matching tasks to the effective operating regime of existing models is a useful perspective, and the claim of larger gains on challenging cases, if substantiated, would strengthen the practical value.
major comments (2)
- [§4] §4 (Experiments): The central claim of 'consistent improvements' and 'especially large gains on challenging cases' across ImgEdit, PICA, RePlan and multiple backbones is asserted without any quantitative metrics, success rates, baseline tables, ablation results on individual agent components, or statistical controls. This absence prevents verification that the data support the claim that task reformulation, rather than other factors, drives the gains.
- [§3.3] §3.3 (Feedback-driven refinement): The description of the iterative refinement loop does not specify termination criteria, maximum iteration limits, or safeguards against non-convergence. Without these details the practical reliability of the agentic execution pipeline cannot be assessed, which is load-bearing for the claim that the method improves editing without modifying the backbone.
minor comments (2)
- The abstract and method sections use the term 'Nano Banana' for one of the editing backbones; a brief clarification of the model name or reference would improve readability.
- Figure captions and the pipeline diagram (presumably Figure 1 or 2) would benefit from explicit labeling of the four agent stages (analysis, routing, reformulation, refinement) to match the textual description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central claim of 'consistent improvements' and 'especially large gains on challenging cases' across ImgEdit, PICA, RePlan and multiple backbones is asserted without any quantitative metrics, success rates, baseline tables, ablation results on individual agent components, or statistical controls. This absence prevents verification that the data support the claim that task reformulation, rather than other factors, drives the gains.
Authors: We acknowledge that the current version of Section 4 summarizes the results without providing the full quantitative tables, success rates, baseline comparisons, component ablations, or statistical controls. In the revised manuscript we will expand this section to include success-rate tables for all benchmarks and backbones, ablation studies isolating the contributions of analysis, routing, reformulation, and feedback, and statistical significance tests. These additions will allow direct verification that the observed gains are attributable to task reformulation. revision: yes
-
Referee: [§3.3] §3.3 (Feedback-driven refinement): The description of the iterative refinement loop does not specify termination criteria, maximum iteration limits, or safeguards against non-convergence. Without these details the practical reliability of the agentic execution pipeline cannot be assessed, which is load-bearing for the claim that the method improves editing without modifying the backbone.
Authors: We agree that the description in Section 3.3 is incomplete regarding the iterative loop. The revised manuscript will specify termination criteria (e.g., feedback quality threshold or no further improvement), a maximum iteration limit of three, and safeguards such as fallback to the original task upon non-convergence. These explicit details will enable assessment of the pipeline's reliability while preserving the model-agnostic nature of the approach. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical agentic framework for adaptive task reformulation in image editing, supported by benchmark experiments across multiple backbones. No equations, derivations, or mathematical predictions are present. The central claims rest on observed performance gains from an additive MLLM-agent layer described as independent of base models, with no self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the argument to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLM agents can reliably analyze images, route decisions, reformulate instructions, and refine via feedback for editing tasks
Reference graph
Works this paper leans on
- [1]
-
[2]
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al . 2023. Improving im- age generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf2, 3 (2023), 8
2023
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A Efros. 2023. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18392–18402
2023
-
[4]
Tingfeng Cao, Chengyu Wang, Bingyan Liu, Ziheng Wu, Jinhui Zhu, and Jun Huang. 2023. Beautifulprompt: Towards automatic prompt engineering for text- to-image synthesis. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. 1–11
2023
- [5]
- [6]
-
[7]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first international conference on machine learning
2024
-
[8]
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan
- [9]
-
[10]
Zigang Geng, Binxin Yang, Tiankai Hang, Chen Li, Shuyang Gu, Ting Zhang, Jianmin Bao, Zheng Zhang, Houqiang Li, Han Hu, et al. 2024. Instructdiffusion: A generalist modeling interface for vision tasks. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 12709–12720
2024
-
[11]
Yaru Hao, Zewen Chi, Li Dong, and Furu Wei. 2023. Optimizing prompts for text-to-image generation.Advances in Neural Information Processing Systems36 (2023), 66923–66939
2023
-
[12]
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. 2023. T2i- compbench: A comprehensive benchmark for open-world compositional text-to- image generation.Advances in Neural Information Processing Systems36 (2023), 78723–78747
2023
-
[13]
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. 2024. Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8362–8371
2024
-
[14]
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. 2023. Imagic: Text-based real image editing with diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6007–6017
2023
- [15]
- [16]
-
[17]
Vivian Liu and Lydia B Chilton. 2022. Design guidelines for prompt engineering text-to-image generative models. InProceedings of the 2022 CHI conference on human factors in computing systems. 1–23
2022
-
[18]
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt. 2023. Drag your gan: Interactive point-based manip- ulation on the generative image manifold. InACM SIGGRAPH 2023 conference proceedings. 1–11
2023
-
[19]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review arXiv 2023
- [20]
- [21]
-
[22]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22500–22510
2023
-
[23]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems36 (2023), 38154–38180
2023
-
[24]
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. 2024. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8871–8879
2024
-
[25]
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. 2023. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1921–1930
2023
-
[26]
Haoran Wang, Bo Zhao, Jinghui Wang, Hanzhang Wang, Huan Yang, Wei Ji, Hao Liu, and Xinyan Xiao. 2025. Sega: A stepwise evolution paradigm for content-aware layout generation with design prior. InProceedings of the IEEE/CVF International Conference on Computer Vision. 19321–19330
2025
-
[27]
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. 2024. Genartist: Multimodal llm as an agent for unified image generation and editing.Advances in Neural Information Processing Systems37 (2024), 128374–128395
2024
-
[28]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al . 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025)
work page internal anchor Pith review arXiv 2025
-
[29]
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, and Bin Cui
-
[30]
InIcml, Vol
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs.. InIcml, Vol. 3. 7
-
[31]
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. 2025. Imgedit: A unified image editing dataset and benchmark. arXiv preprint arXiv:2505.20275(2025)
work page internal anchor Pith review arXiv 2025
-
[32]
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. 2023. Magicbrush: A manually annotated dataset for instruction-guided image editing. InAdvances in Neural Information Processing Systems, Vol. 36. 31428–31449
2023
-
[33]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional con- trol to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision. 3836–3847
2023
-
[34]
Zhixing Zhang, Ligong Han, Arnab Ghosh, Dimitris N Metaxas, and Jian Ren. 2023. Sine: Single image editing with text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6027–6037
2023
- [35]
-
[36]
Bo Zhao, Huan Yang, and Jianlong Fu. 2025. Learning position-aware implicit neural network for real-world face inpainting.Pattern Recognition165 (2025), 111598. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2025
-
[37]
perfect local edit
Jun Zhou, Jiahao Li, Zunnan Xu, Hanhui Li, Yiji Cheng, Fa-Ting Hong, Qin Lin, Qinglin Lu, and Xiaodan Liang. 2025. Fireedit: Fine-grained instruction-based image editing via region-aware vision language model. InProceedings of the Computer Vision and Pattern Recognition Conference. 13093–13103. Making Image Editing Easier via Adaptive Task Reformulation w...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.