Recognition: unknown
CIMple: Standard-cell SRAM-based CIM with LUT-based split softmax for attention acceleration
Pith reviewed 2026-05-10 07:53 UTC · model grok-4.3
The pith
A dual-banked SRAM-based CIM accelerator with LUT split softmax reaches 26.1 TOPS/W for transformer self-attention in 28nm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CIMple is a fully digital standard-cell SRAM-based CIM architecture for self-attention that overcomes the static-MAC limitation of prior CIM designs. It employs a novel dual-banked structure with 8-bit parallel weight feeding together with a LUT-based fixed-point implementation of split softmax. The 32 kb accelerator fabricated in 28 nm achieves 26.1 TOPS/W at 0.85 V and 2.31 TOPS/mm² at 1.2 V while preserving accuracy across various transformer models.
What carries the argument
Dual-banked fully digital CIM architecture using 8-bit parallel weight feeding and LUT-based fixed-point split softmax to handle both linear and nonlinear attention operations inside the same SRAM array.
If this is right
- Self-attention can be executed with far less off-array data movement than conventional digital accelerators.
- Nonlinear functions such as softmax become practical inside CIM arrays when realized as small fixed-point LUTs.
- The same hardware template can be reused across multiple transformer variants without analog redesign.
- INT8 precision at these efficiency levels becomes viable for battery-powered edge inference of large models.
Where Pith is reading between the lines
- The same dual-banking and LUT approach could be extended to other attention variants such as multi-query or grouped-query attention.
- Full end-to-end transformer layers might be built by tiling multiple CIMple blocks for feed-forward and embedding stages.
- The fixed-point LUT technique for nonlinearities could be reused for activation functions in other neural-network accelerators.
Load-bearing premise
The LUT-based fixed-point implementation reduces latency with minimal accuracy degradation while supporting various transformer models through the dual-banked fully digital architecture.
What would settle it
Silicon measurements on the 28 nm chip showing either energy efficiency below 20 TOPS/W at 0.85 V or more than 2 percent accuracy loss on standard transformer benchmarks such as GLUE.
Figures




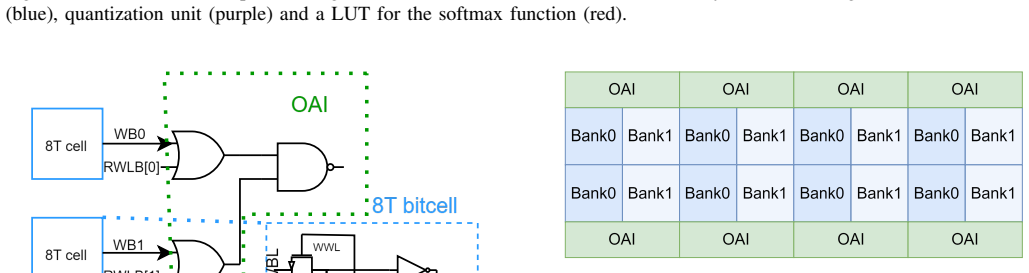

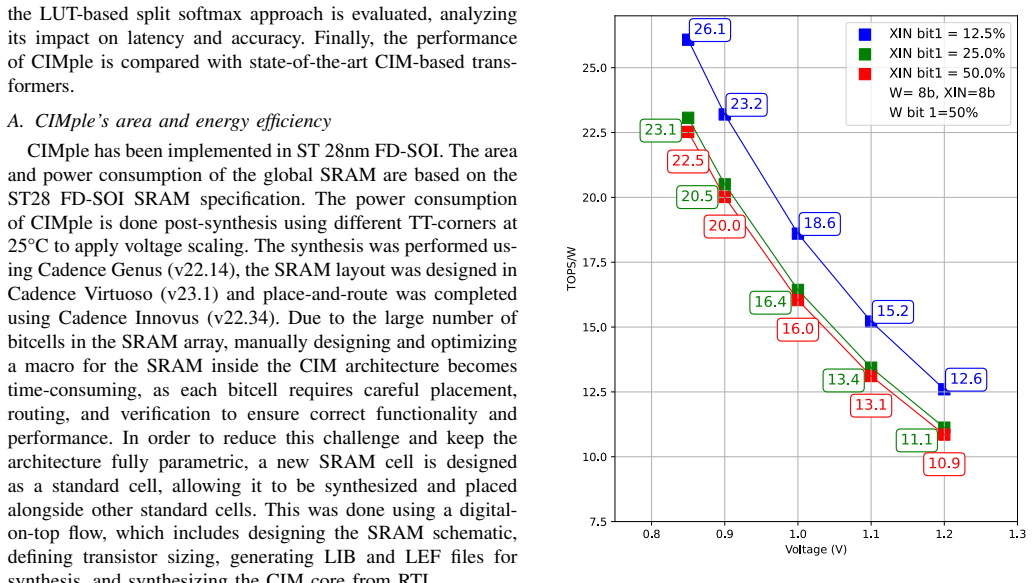
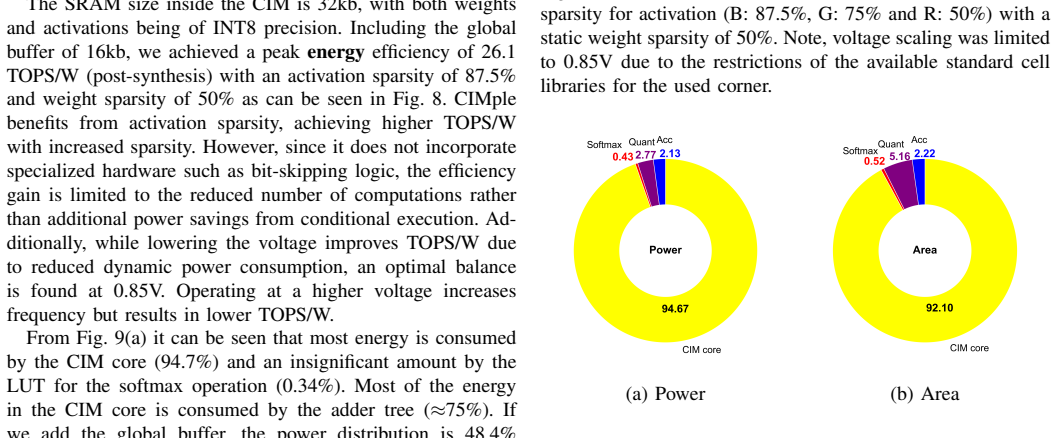

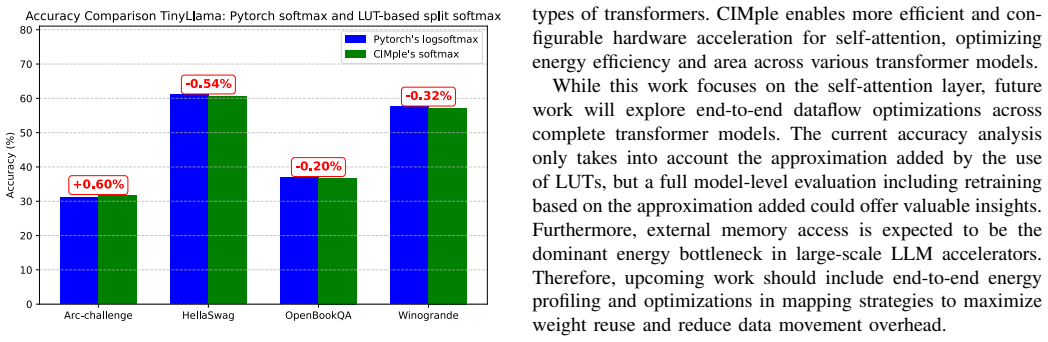
read the original abstract
Large Language Models (LLMs) such as LLaMA and DeepSeek, are built on transformer architectures, which have become a standard model for achieving state-of-the-art performance in natural language processing tasks. Recently, there has been growing interest in deploying LLMs on edge devices. Although smaller LLM models are being proposed, they often still contain billions of parameters. Since edge devices are limited in their resources this poses a significant challenge for edge deployment. Compute-in-memory (CIM) is a promising architecture that addresses this by reducing data movement through the integration of computational logic directly into memory. However, existing CIM architectures support only static Multiply-Accumulate (MAC) operations which limit their configurability in supporting nonlinear operations and various types of transformer models. This paper presents a fully digital standard-cell SRAM-based CIM architecture accelerator for self-attention, called CIMple, designed to overcome these limitations, inside transformer models. The key contributions of CIMple are: 1) A novel dual-banked CIM-based fully digital self-attention accelerator using 8-bit parallel weight feeding. 2) A look-up-table (LUT) based fixed-point implementation reducing latency with minimal accuracy degradation. 3) A performance evaluation of a 32kb CIM-based self-attention accelerator implemented in 28nm, which achieves 26.1 TOPS/W at 0.85V and 2.31 TOPS/mm$^2$ at 1.2V, both with INT8 precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CIMple, a fully digital standard-cell SRAM-based compute-in-memory (CIM) accelerator for self-attention in transformers. Key features include a dual-banked architecture with 8-bit parallel weight feeding and an LUT-based fixed-point split softmax to enable nonlinear operations while reducing latency. A 32 kb prototype fabricated in 28 nm CMOS is evaluated, reporting 26.1 TOPS/W at 0.85 V and 2.31 TOPS/mm² at 1.2 V, both at INT8 precision, with claims of supporting multiple transformer models and minimal accuracy degradation.
Significance. If the hardware measurements and accuracy claims hold under detailed scrutiny, the work would demonstrate a practical, configurable CIM solution for attention acceleration that overcomes the static-MAC limitation of prior CIM designs. The concrete 28 nm efficiency numbers and fully digital approach could inform edge LLM deployment, provided the LUT softmax and dual-banked design generalize across models.
major comments (3)
- [Abstract and Results] The abstract and results section report concrete TOPS/W and TOPS/mm² figures from a 28 nm implementation, yet the manuscript provides neither full circuit schematics nor an error analysis (e.g., bit-error rates or voltage scaling effects) that would substantiate these metrics as load-bearing evidence for the claimed efficiency advantage.
- [Architecture and LUT Softmax] The LUT-based fixed-point split softmax is asserted to reduce latency with only minimal accuracy degradation and to support various transformer models, but no quantitative accuracy tables (e.g., perplexity or attention-score MSE versus FP32 baselines) or ablation across sequence lengths/models appear; this directly underpins the weakest assumption and the generality claim.
- [Architecture Description] The dual-banked fully digital architecture with 8-bit parallel weight feeding is presented as novel, but the manuscript lacks a direct comparison table against prior SRAM-CIM or digital attention accelerators on the same 28 nm node or equivalent metrics, making it difficult to assess whether the reported numbers represent a genuine advance.
minor comments (2)
- [Abstract] The phrase 'inside transformer models' in the abstract is unclear; rephrase to indicate that the accelerator targets the self-attention computation within transformer blocks.
- [LUT-based Softmax] Notation for the LUT split-softmax (e.g., bit-width partitioning and fixed-point scaling factors) should be defined explicitly in the first use, preferably with a small equation or diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where they strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Abstract and Results] The abstract and results section report concrete TOPS/W and TOPS/mm² figures from a 28 nm implementation, yet the manuscript provides neither full circuit schematics nor an error analysis (e.g., bit-error rates or voltage scaling effects) that would substantiate these metrics as load-bearing evidence for the claimed efficiency advantage.
Authors: We agree that additional substantiation would improve the manuscript. In the revision we will add a dedicated error-analysis subsection in the results that reports measured bit-error rates across operating voltages and discusses voltage-scaling effects on both efficiency and functional correctness. The current manuscript already contains block-level diagrams of the dual-banked SRAM array and LUT softmax; we will expand these with more detailed sub-block schematics and will include the complete transistor-level schematics in the supplementary material. revision: partial
-
Referee: [Architecture and LUT Softmax] The LUT-based fixed-point split softmax is asserted to reduce latency with only minimal accuracy degradation and to support various transformer models, but no quantitative accuracy tables (e.g., perplexity or attention-score MSE versus FP32 baselines) or ablation across sequence lengths/models appear; this directly underpins the weakest assumption and the generality claim.
Authors: The referee correctly notes the absence of quantitative accuracy data. We will add a new evaluation subsection containing tables that report perplexity and attention-score MSE relative to FP32 baselines for representative transformer models (BERT, GPT-2, LLaMA-7B). We will also include ablation results across sequence lengths (128–2048) and multiple model scales to quantify the latency–accuracy trade-off of the LUT-based split softmax and to support the generality claim. revision: yes
-
Referee: [Architecture Description] The dual-banked fully digital architecture with 8-bit parallel weight feeding is presented as novel, but the manuscript lacks a direct comparison table against prior SRAM-CIM or digital attention accelerators on the same 28 nm node or equivalent metrics, making it difficult to assess whether the reported numbers represent a genuine advance.
Authors: We concur that a side-by-side comparison is necessary. The revised manuscript will contain a new comparison table that places CIMple against recent SRAM-CIM and digital attention accelerators. Where possible, metrics will be normalized to 28 nm; the table will list TOPS/W, TOPS/mm², precision, supported operations, and architectural features so that the advantages of the dual-banked 8-bit parallel design and LUT softmax can be directly evaluated. revision: yes
Circularity Check
No circularity: hardware metrics from physical implementation
full rationale
The paper presents an architectural design for a CIM-based self-attention accelerator and reports measured performance (TOPS/W, TOPS/mm²) from a 28nm physical implementation. No equations, derivations, fitted parameters, or self-citation chains are used to 'predict' results; claims rest on direct hardware measurements and standard design descriptions. This is self-contained with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard-cell SRAM cells can be reliably used for both storage and in-memory computation without custom analog circuits.
- domain assumption LUT approximation of softmax introduces only minimal accuracy loss for transformer attention.
Reference graph
Works this paper leans on
-
[1]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Songet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[Online]. Available: https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Information Processing Systems, 2017
2017
-
[4]
Conversational agents in ther- apeutic interventions for neurodevelopmental disorders: a survey,
F. Catania, M. Spitale, and F. Garzotto, “Conversational agents in ther- apeutic interventions for neurodevelopmental disorders: a survey,”ACM Computing Surveys, vol. 55, no. 10, pp. 1–34, 2023
2023
-
[5]
15.3 a 351tops/w and 372.4gops compute-in- memory sram macro in 7nm finfet cmos for machine-learning appli- cations,
Q. Dong, M. E. Sinangil, B. Erbagci, D. Sun, W.-S. Khwa, H.-J. Liao, Y . Wang, and J. Chang, “15.3 a 351tops/w and 372.4gops compute-in- memory sram macro in 7nm finfet cmos for machine-learning appli- cations,” in2020 IEEE International Solid-State Circuits Conference - (ISSCC), 2020, pp. 242–244
2020
-
[6]
A 32.2 tops/w sram compute-in-memory macro employing a linear 8-bit c-2c ladder for charge domain computation in 22nm for edge inference,
H. Wang, R. Liu, R. Dorrance, D. Dasalukunte, X. Liu, D. Lake, B. Carlton, and M. Wu, “A 32.2 tops/w sram compute-in-memory macro employing a linear 8-bit c-2c ladder for charge domain computation in 22nm for edge inference,” in2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, pp. 36–37
2022
-
[7]
A 5-nm 254-tops/w 221-tops/mm2 fully-digital computing-in-memory macro supporting wide-range dynamic-voltage- frequency scaling and simultaneous mac and write operations,
H. Fujiwara, H. Mori, W.-C. Zhao, M.-C. Chuang, R. Naous, C.-K. Chuang, T. Hashizume, D. Sun, C.-F. Lee, K. Akarvardar, S. Adham, T.-L. Chou, M. E. Sinangil, Y . Wang, Y .-D. Chih, Y .-H. Chen, H.-J. Liao, and T.-Y . J. Chang, “A 5-nm 254-tops/w 221-tops/mm2 fully-digital computing-in-memory macro supporting wide-range dynamic-voltage- frequency scaling a...
2022
-
[8]
A 4nm 6163-tops/w/b4790−tops/mm 2/bsram based digital-computing-in-memory macro supporting bit-width flexibility and simultaneous mac and weight update,
H. Mori, W.-C. Zhao, C.-E. Lee, C.-F. Lee, Y .-H. Hsu, C.-K. Chuang, T. Hashizume, H.-C. Tung, Y .-Y . Liu, S.-R. Wu, K. Akarvardar, T.-L. Chou, H. Fujiwara, Y . Wang, Y .-D. Chih, Y .-H. Chen, H.-J. Liao, and T.-Y . J. Chang, “A 4nm 6163-tops/w/b4790−tops/mm 2/bsram based digital-computing-in-memory macro supporting bit-width flexibility and simultaneous...
2023
-
[9]
34.4 a 3nm, 32.5tops/w, 55.0tops/mm2 and 3.78mb/mm2 fully-digital compute-in- memory macro supporting int12 × int12 with a parallel-mac architecture and foundry 6t-sram bit cell,
H. Fujiwara, H. Mori, W.-C. Zhao, K. Khare, C.-E. Lee, X. Peng, V . Joshi, C.-K. Chuang, S.-H. Hsu, T. Hashizume, T. Naganuma, C.-H. Tien, Y .-Y . Liu, Y .-C. Lai, C.-F. Lee, T.-L. Chou, K. Akarvardar, S. Adham, Y . Wang, Y .-D. Chih, Y .-H. Chen, H.-J. Liao, and T.-Y . J. Chang, “34.4 a 3nm, 32.5tops/w, 55.0tops/mm2 and 3.78mb/mm2 fully-digital compute-i...
2024
-
[10]
A 12nm 121-tops/w 41.6- tops/mm2 all digital full precision sram-based compute-in-memory with configurable bit-width for ai edge applications,
C.-F. Lee, C.-H. Lu, C.-E. Lee, H. Mori, H. Fujiwara, Y .-C. Shih, T.- L. Chou, Y .-D. Chih, and T.-Y . J. Chang, “A 12nm 121-tops/w 41.6- tops/mm2 all digital full precision sram-based compute-in-memory with configurable bit-width for ai edge applications,” in2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, pp. 24–25
2022
-
[11]
Trancim: Full-digital bitline-transpose cim-based sparse transformer accelerator with pipeline/parallel reconfigurable modes,
F. Tu, Z. Wu, Y . Wang, L. Liang, L. Liu, Y . Ding, L. Liu, S. Wei, Y . Xie, and S. Yin, “Trancim: Full-digital bitline-transpose cim-based sparse transformer accelerator with pipeline/parallel reconfigurable modes,” IEEE Journal of Solid-State Circuits, vol. 58, no. 6, pp. 1798–1809, 2023
2023
-
[12]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:160025533
2019
-
[14]
M. Lewis, “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,”arXiv preprint arXiv:1910.13461, 2019
work page internal anchor Pith review arXiv 1910
-
[15]
Full stack optimization of transformer inference: a survey,
S. Kim, C. Hooper, T. Wattanawong, M. Kang, R. Yan, H. Genc, G. Dinh, Q. Huang, K. Keutzer, M. W. Mahoneyet al., “Full stack optimization of transformer inference: a survey,”arXiv preprint arXiv:2302.14017, 2023
-
[16]
Online normalizer calculation for softmax,
M. Milakov and N. Gimelshein, “Online normalizer calculation for softmax,”arXiv preprint arXiv:1805.02867, 2018
-
[17]
A 28-nm 28.8- tops/w attention-based nn processor with correlative cim ring architecture and dataflow-reshaped digital-assisted cim array,
R. Guo, Z. Yue, Y . Wang, H. Li, T. Hu, Y . Wang, H. Sun, J.-L. Hsu, Y . Zhang, B. Yan, L. Liu, R. Huang, S. Wei, and S. Yin, “A 28-nm 28.8- tops/w attention-based nn processor with correlative cim ring architecture and dataflow-reshaped digital-assisted cim array,”IEEE Journal of Solid- State Circuits, pp. 1–15, 2024
2024
-
[18]
An energy-efficient transformer processor exploiting dynamic weak relevances in global attention,
Y . Wang, Y . Qin, D. Deng, J. Wei, Y . Zhou, Y . Fan, T. Chen, H. Sun, L. Liu, S. Wei, and S. Yin, “An energy-efficient transformer processor exploiting dynamic weak relevances in global attention,”IEEE Journal of Solid-State Circuits, vol. 58, no. 1, pp. 227–242, 2023
2023
-
[19]
Ita: An energy-efficient attention and softmax accelerator for quantized transformers,
G. Islamoglu, M. Scherer, G. Paulin, T. Fischer, V . J. Jung, A. Garofalo, and L. Benini, “Ita: An energy-efficient attention and softmax accelerator for quantized transformers,” in2023 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), 2023, pp. 1–6
2023
-
[20]
Hardware implementation of softmax function based on piecewise lut,
X. Dong, X. Zhu, and D. Ma, “Hardware implementation of softmax function based on piecewise lut,” in2019 IEEE International Workshop on Future Computing (IWOFC, 2019, pp. 1–3
2019
-
[21]
Efficient softmax approximation for deep neural networks with attention mechanism,
I. Vasyltsov and W. Chang, “Efficient softmax approximation for deep neural networks with attention mechanism,” 2021. [Online]. Available: https://arxiv.org/abs/2111.10770
-
[22]
Multcim: Digital computing-in-memory-based multimodal transformer accelerator with attention-token-bit hybrid sparsity,
F. Tu, Z. Wu, Y . Wang, W. Wu, L. Liu, Y . Hu, S. Wei, and S. Yin, “Multcim: Digital computing-in-memory-based multimodal transformer accelerator with attention-token-bit hybrid sparsity,”IEEE Journal of Solid-State Circuits, vol. 59, no. 1, pp. 90–101, 2024
2024
-
[23]
Cimformer: A systolic cim-array-based transformer accelerator with token-pruning-aware attention reformulating and principal possibility gathering,
R. Guo, X. Chen, L. Wang, Y . Wang, H. Sun, J. Wei, H. Han, L. Liu, S. Wei, Y . Hu, and S. Yin, “Cimformer: A systolic cim-array-based transformer accelerator with token-pruning-aware attention reformulating and principal possibility gathering,”IEEE Journal of Solid-State Circuits, pp. 1–13, 2024
2024
-
[24]
I-bert: Integer-only bert quantization,
S. Kim, A. Gholami, Z. Yao, M. W. Mahoney, and K. Keutzer, “I-bert: Integer-only bert quantization,” inInternational conference on machine learning. PMLR, 2021, pp. 5506–5518
2021
-
[25]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[26]
23.8 an 88.36tops/w bit-level-weight-compressed large-language- model accelerator with cluster-aligned int-fp-gemm and bi-dimensional workflow reformulation,
Y . Qin, Y . Wang, J. Wang, Z. Lin, Y . Zhao, S. Wei, Y . Hu, and S. Yin, “23.8 an 88.36tops/w bit-level-weight-compressed large-language- model accelerator with cluster-aligned int-fp-gemm and bi-dimensional workflow reformulation,” in2025 IEEE International Solid-State Circuits Conference (ISSCC), vol. 68, 2025, pp. 420–422
2025
-
[27]
Tinyllama: An open-source small language model,
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,” 2024
2024
-
[28]
A framework for few-shot language model evaluation,
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “A framework for few-shot language model evaluation,” 07
-
[29]
The language model evaluation harness, 07 2024.https://zenodo.org/records/12608602
[Online]. Available: https://zenodo.org/records/12608602
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.