Recognition: unknown
Stochasticity in Tokenisation Improves Robustness
Pith reviewed 2026-05-10 08:47 UTC · model grok-4.3
The pith
Pre-training and fine-tuning LLMs with uniformly sampled stochastic tokenisations improves robustness to random and adversarial perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that uniformly sampling stochastic tokenisations throughout pre-training and supervised fine-tuning produces models whose representations are less sensitive to tokenisation changes. This yields higher accuracy under both random perturbations and adversarial attacks on tokenisation compared with deterministic canonical training, while standard-task performance stays the same and inference speed is unchanged.
What carries the argument
Uniformly sampled stochastic tokenisation during training, which forces the model to process multiple possible token sequences for the same text and thereby builds tolerance to tokenisation variation.
If this is right
- Models trained with stochastic tokenisation resist adversarial attacks that alter input tokenisation.
- Accuracy on standard tasks remains comparable to deterministic training.
- Inference cost stays identical to baseline models.
- The robustness benefit appears in both pre-training and fine-tuning across varied architectures and datasets.
Where Pith is reading between the lines
- The method could be paired with other robustness techniques such as adversarial training to compound gains.
- It may also increase tolerance to non-tokenisation input variations like spelling changes or dialect shifts.
- Practical tests on larger models and noisy real-world data would show whether the robustness translates to deployment settings.
Load-bearing premise
That sampling different tokenisations during training does not introduce biases that impair learning of the core task and that testing on non-canonical tokenisations isolates robustness effects without confounding factors.
What would settle it
A replication in which stochastic training produces lower accuracy on clean canonical evaluations or shows no robustness gain on perturbed tokenisations compared with a canonically trained baseline would disprove the central claim.
Figures

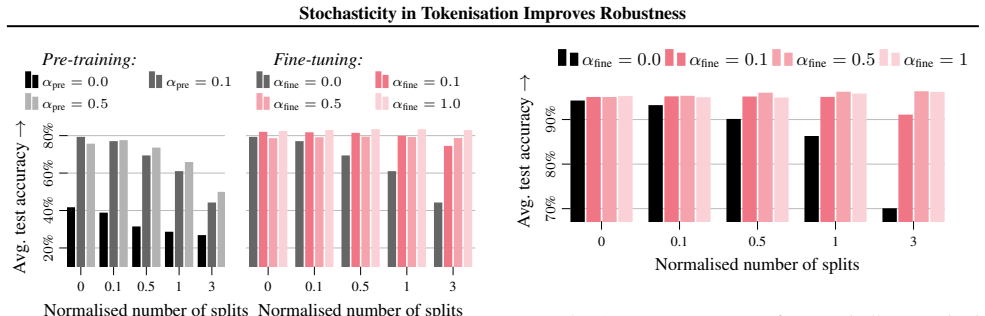
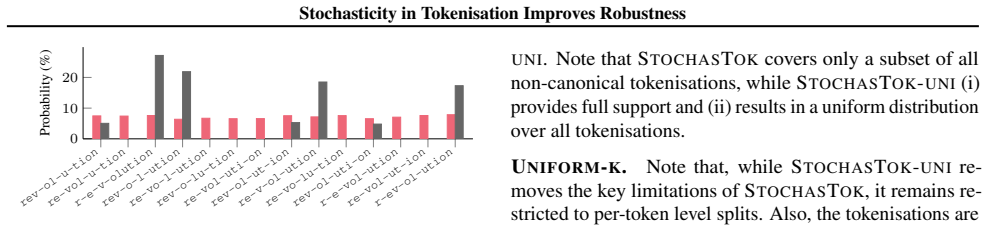

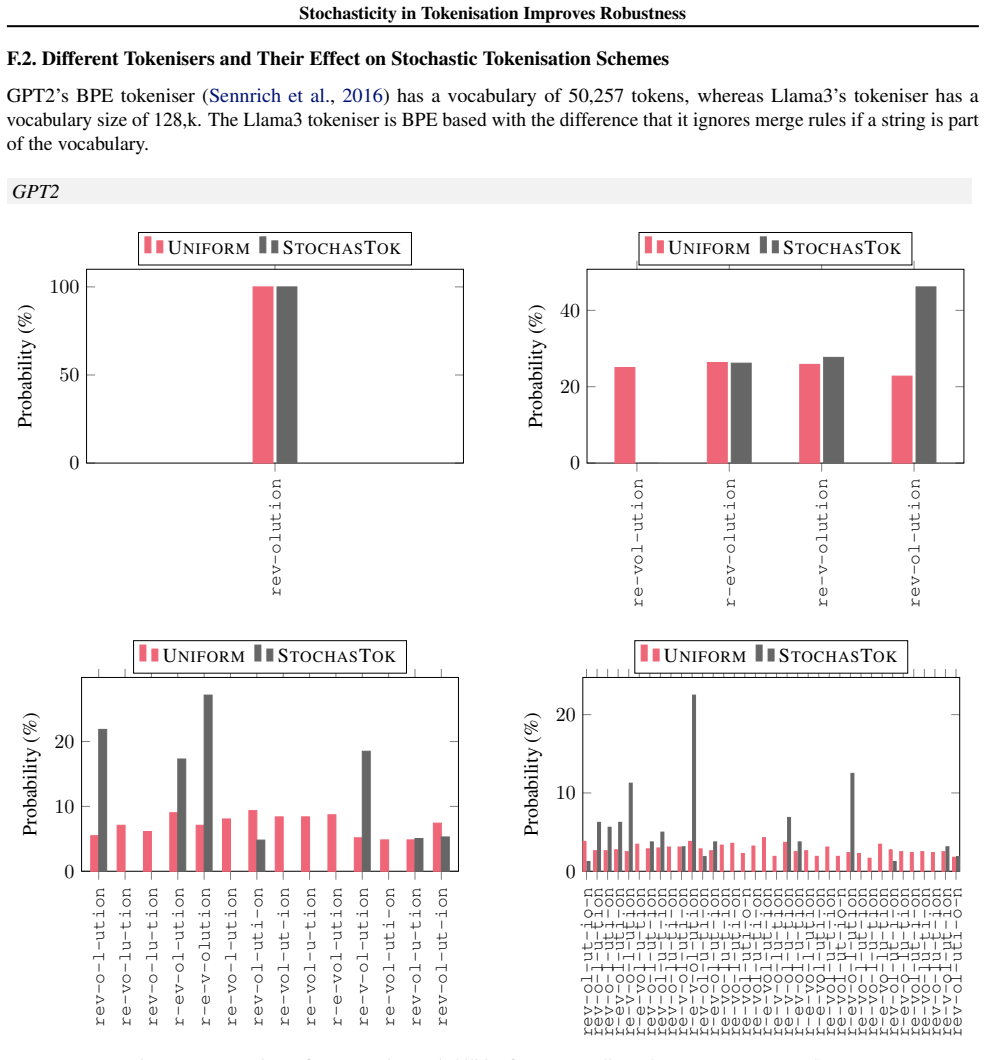

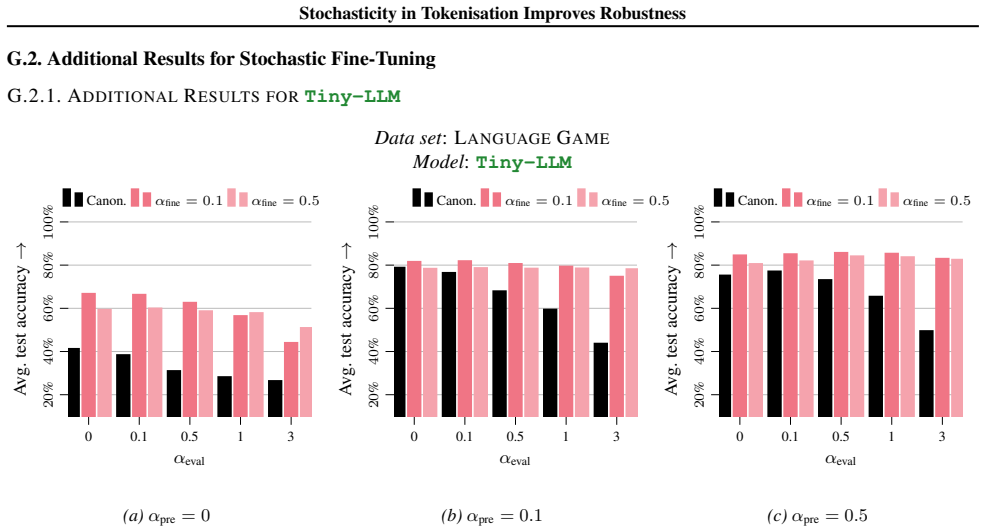






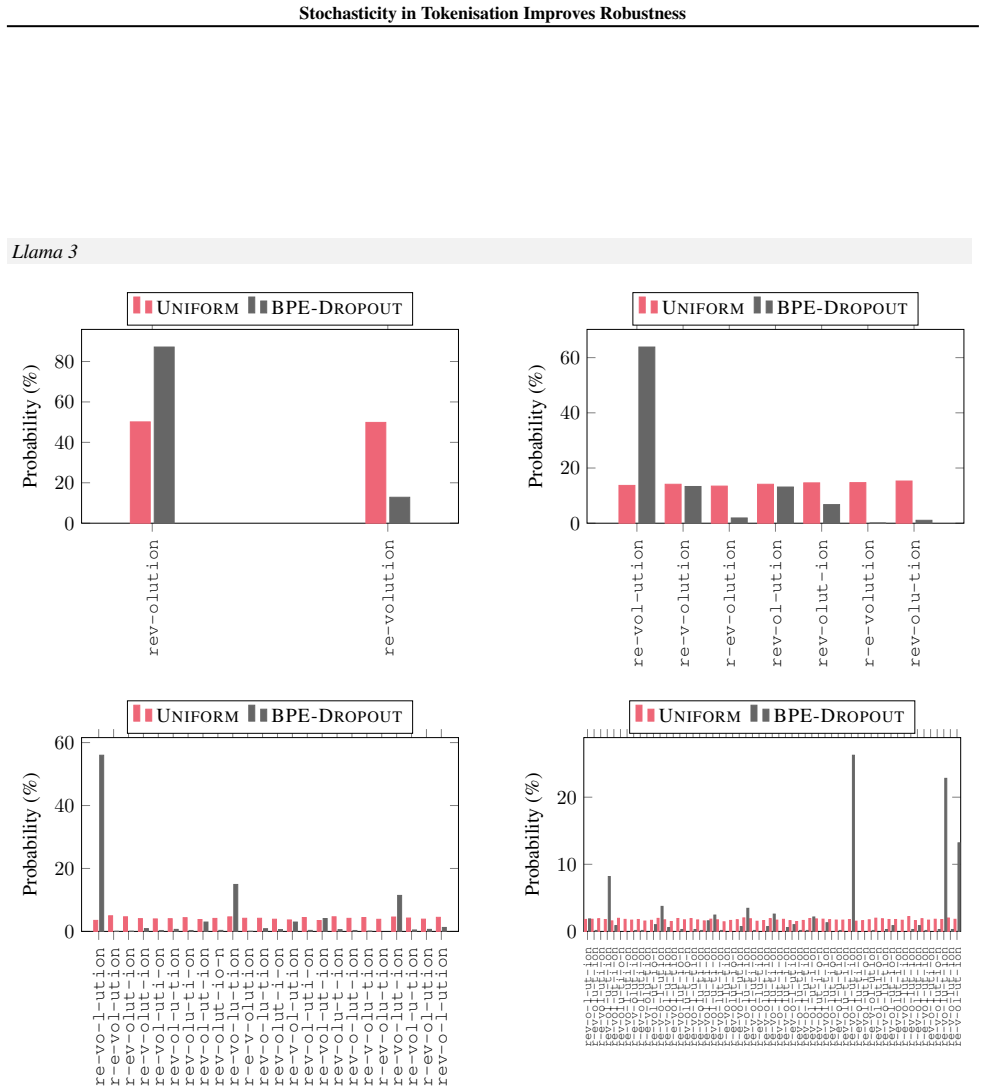
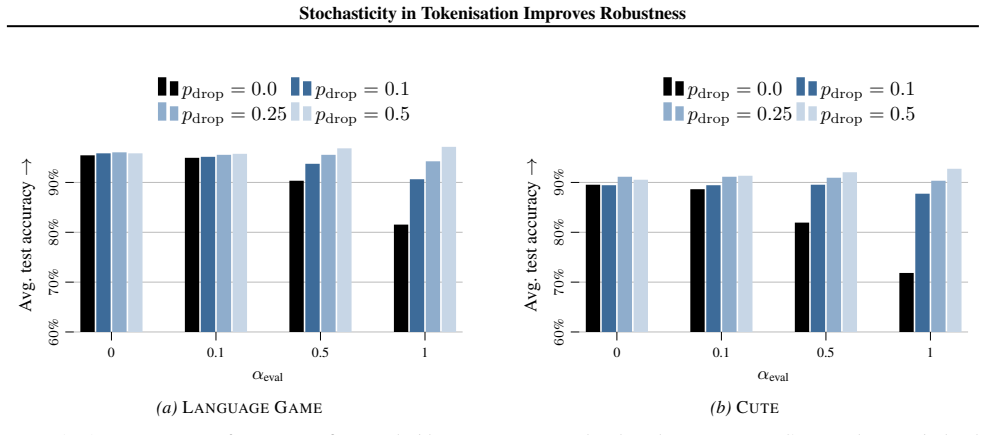
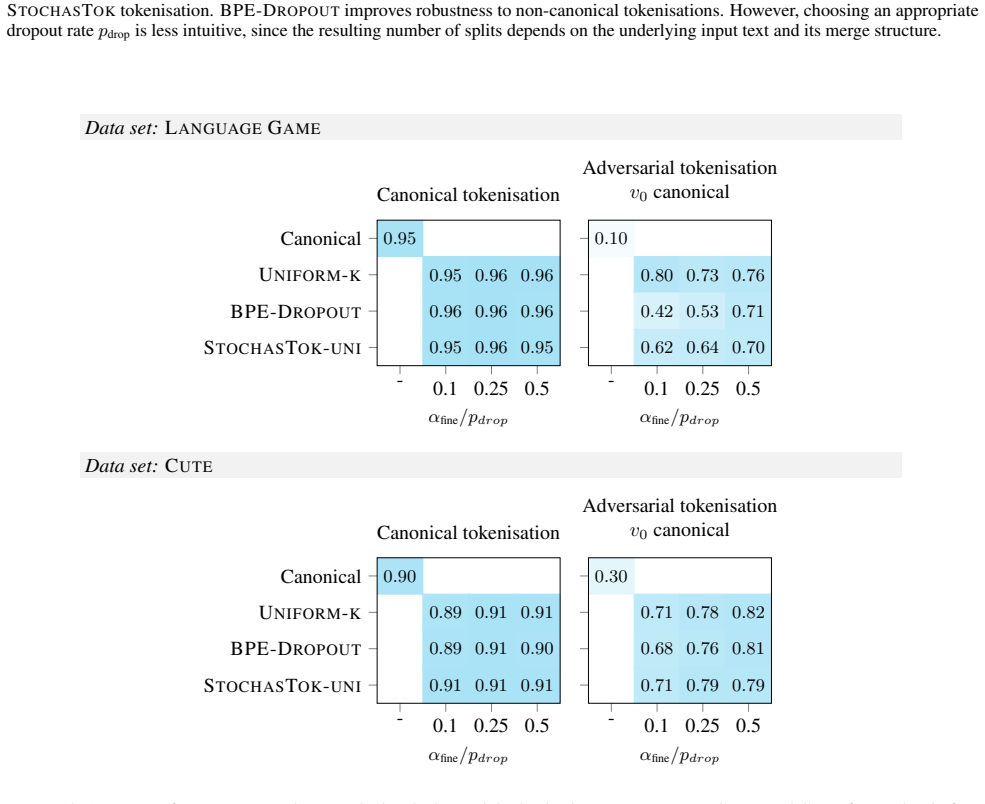




read the original abstract
The widespread adoption of large language models (LLMs) has increased concerns about their robustness. Vulnerabilities in perturbations of tokenisation of the input indicate that models trained with a deterministic canonical tokenisation can be brittle to adversarial attacks. Recent studies suggest that stochastic tokenisation can deliver internal representations that are less sensitive to perturbations. In this paper, we analyse how stochastic tokenisations affect robustness to adversarial attacks and random perturbations. We systematically study this over a range of learning regimes (pre-training, supervised fine-tuning, and in-context learning), data sets, and model architectures. We show that pre-training and fine-tuning with uniformly sampled stochastic tokenisations improve robustness to random and adversarial perturbations. Evaluating on uniformly sampled non-canonical tokenisations reduces the accuracy of a canonically trained Llama-1b model by 29.8%. We find that training with stochastic tokenisation preserves accuracy without increasing inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
Empirical study with no circular derivations or self-referential predictions
full rationale
The paper is an empirical investigation of stochastic tokenisation effects on robustness, reporting experimental results across pre-training, fine-tuning, and in-context learning regimes. No mathematical derivations, first-principles predictions, or equations are claimed that could reduce to fitted inputs or self-definitions by construction. The central claims rest on accuracy measurements under canonical vs. stochastic tokenisations, with no load-bearing self-citations or ansatzes invoked as uniqueness theorems. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
S., Ehghaghi, M., Lester, B., Liu, F., Zhao, W., Ciccone, M., and Raffel, C
Altınta¸ s, G. S., Ehghaghi, M., Lester, B., Liu, F., Zhao, W., Ciccone, M., and Raffel, C. Toksuite: Measuring the impact of tokenizer choice on language model behavior. arXiv preprint arXiv:2512.20757,
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? Try ARC, the AI2 reasoning chal- lenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Distributional properties of subword regularization
Cognetta, M., Zouhar, V ., and Okazaki, N. Distributional properties of subword regularization. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 10753–10763,
2024
-
[5]
Attacks, defenses and evaluations for LLM conversation safety: A survey
Dong, Z., Zhou, Z., Yang, C., Shao, J., and Qiao, Y . Attacks, defenses and evaluations for LLM conversation safety: A survey. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 6734–6747,
2024
-
[6]
CUTE: Measuring LLMs’ understanding of their tokens
Edman, L., Schmid, H., and Fraser, A. CUTE: Measuring LLMs’ understanding of their tokens. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 3017–3026,
2024
-
[7]
C., and Bau, D
Feucht, S., Atkinson, D., Wallace, B. C., and Bau, D. Token erasure as a footprint of implicit vocabulary items in llms. InProceedings of the 2024 Conference on Empirical 9 Stochasticity in Tokenisation Improves Robustness Methods in Natural Language Processing (EMNLP), pp. 9727–9739,
2024
-
[8]
Where is the signal in tokenization space? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp
Geh, R., Zhang, H., Ahmed, K., Wang, B., and Van den Broeck, G. Where is the signal in tokenization space? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 3966–3979,
2024
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Super tiny language models.arXiv preprint arXiv:2405.14159,
Hillier, D., Guertler, L., Tan, C., Agrawal, P., Ruirui, C., and Cheng, B. Super tiny language models.arXiv preprint arXiv:2405.14159,
-
[11]
Hiraoka, T. and Inui, K. Spelling-out is not straightforward: LLMs capability of tokenization from token to characters. arXiv preprint arXiv:2506.10641,
-
[12]
and Levy, O
Itzhak, I. and Levy, O. Models in a spelling bee: Lan- guage models implicitly learn the character composition of tokens. InProceedings of the 2022 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technologies, pp. 5061–5068,
2022
-
[13]
and Mahowald, K
Kaushal, A. and Mahowald, K. What do tokens know about their characters and how do they know it? InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2487–2507,
2022
-
[14]
Red teaming language models with language models
Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., and Irving, G. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 3419–3448,
2022
-
[15]
Com- monsenseQA: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Com- monsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158,
2019
-
[16]
Gemini: A Family of Highly Capable Multimodal Models
10 Stochasticity in Tokenisation Improves Robustness Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Wu, Y ., Schuster, M., Chen, Z., Le, Q. V ., Norouzi, M., Macherey, W., Krikun, M., Cao, Y ., Gao, Q., Macherey, K., et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144,
work page internal anchor Pith review arXiv
-
[18]
S., Liu, A., Ahia, O., Hayase, J., Choi, Y ., and Smith, N
Zheng, B. S., Liu, A., Ahia, O., Hayase, J., Choi, Y ., and Smith, N. A. Broken tokens? Your language model can secretly handle non-canonical tokenizations.arXiv preprint arXiv:2506.19004,
-
[19]
Training Details /githubThe code for the experiments is available at: https://github.com/stegsoph/ stochastic-tokenisation-robustness
11 Stochasticity in Tokenisation Improves Robustness A. Training Details /githubThe code for the experiments is available at: https://github.com/stegsoph/ stochastic-tokenisation-robustness. For LLMs trained from scratch, we use the architecture proposed in Hillier et al. (2024) and used in Sims et al. (2026). The architectural details are summarised in Table
2024
-
[20]
Feed-forward network SwiGLU, dimension 1320 Normalization RMSNorm (no bias) Positional encoding Rotary positional embeddings (RoPE) Context length 512 Tokeniser type GPT V ocabulary size 50,257 Embedding tying Input/output embeddings tied Table 5.Pre-training setup forTiny-LLMon OpenWebText. Pre-training (Tiny-LLM) Training objective Autoregressive langua...
2025
-
[21]
- stood-
tests the Character-level Understanding of Tokens of models. The original data sets was intended for zero-shot evaluation, providing only a test split. Thus, we follow Sims et al. (2026) in generating a custom CUTEdata set for training and evaluating the smaller scale LLMs. We generate questions for seven subword tasks (contains letter, delete letter, ins...
2026
-
[22]
contains multiple-choice questions that test knowledge about the physical world with two answer options. CANONICAL: •When- boiling- butter- ,- when- it- ’s- ready- ,- you- can- Pour- it- into- a- jar- •To- permanently- attach- metal- legs- to- a- chair- ,- you- can- Weld- the- metal- together- to- get- it- to- stay- firmly- in- place- •how- do- you- inden...
2018
-
[23]
has at most k non-zero columns, each withℓ 2-norm √ 2 . We can consequently formulate the following: ∥H(s 1)−H(s 2)∥≤ √ 2k .(19) And consequently, we can also derive the following: ∥E(s1)−E(s 2)∥=∥W(H(s 1)−H(s 2))∥ ≤ ∥W∥ ∥H(s 1)−H(s 2)∥ ≤ √ 2 ∥W∥ √ k .(20) Now, let’s consider the second part, which relates to the self-attention block. Let ze (correspondin...
2025
-
[24]
Importantly, during stochastic pre-training, the model is trained to predict non-canonical token sequences
Increasing αpre slightly worsens the fit to the canonical distribution, but improves robustness to non-canonical tokenisations. Importantly, during stochastic pre-training, the model is trained to predict non-canonical token sequences. This can reduce accuracy in standard MCQ evaluations, where we compare the log-likelihood of canonically tokenised answer...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.