Recognition: unknown
Elucidating the SNR-t Bias of Diffusion Probabilistic Models
Pith reviewed 2026-05-10 09:00 UTC · model grok-4.3
The pith
Diffusion models have an SNR-timestep mismatch during inference that the authors mitigate with per-frequency differential correction, raising generation quality across IDDPM, ADM, DDIM and others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
during training, the SNR of a sample is strictly coupled with its timestep. However, this correspondence is disrupted during inference, leading to error accumulation and impairing the generation quality... propose a simple yet effective differential correction method to mitigate the SNR-t bias.
Load-bearing premise
That the observed SNR-t mismatch is the dominant source of error accumulation rather than a symptom of other training or sampling choices, and that applying independent corrections to frequency bands will not introduce new artifacts or instability.
Figures












read the original abstract
Diffusion Probabilistic Models have demonstrated remarkable performance across a wide range of generative tasks. However, we have observed that these models often suffer from a Signal-to-Noise Ratio-timestep (SNR-t) bias. This bias refers to the misalignment between the SNR of the denoising sample and its corresponding timestep during the inference phase. Specifically, during training, the SNR of a sample is strictly coupled with its timestep. However, this correspondence is disrupted during inference, leading to error accumulation and impairing the generation quality. We provide comprehensive empirical evidence and theoretical analysis to substantiate this phenomenon and propose a simple yet effective differential correction method to mitigate the SNR-t bias. Recognizing that diffusion models typically reconstruct low-frequency components before focusing on high-frequency details during the reverse denoising process, we decompose samples into various frequency components and apply differential correction to each component individually. Extensive experiments show that our approach significantly improves the generation quality of various diffusion models (IDDPM, ADM, DDIM, A-DPM, EA-DPM, EDM, PFGM++, and FLUX) on datasets of various resolutions with negligible computational overhead. The code is at https://github.com/AMAP-ML/DCW.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fourier or wavelet decomposition can be applied to intermediate denoising samples without destroying the diffusion process semantics
Reference graph
Works this paper leans on
-
[1]
Estimating the optimal covariance with imperfect mean in diffusion probabilistic models
Fan Bao, Chongxuan Li, Jiacheng Sun, Jun Zhu, and Bo Zhang. Estimating the optimal covariance with imperfect mean in diffusion probabilistic models. InICML, 2022. 6, 7
2022
-
[2]
Analytic- DPM: an analytic estimate of the optimal reverse variance in diffusion probabilistic models
Fan Bao, Chongxuan Li, Jun Zhu, and Bo Zhang. Analytic- DPM: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. InICLR, 2022. 6, 7
2022
-
[3]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux, 2024. 2, 6, 7
2024
-
[4]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InCVPR, 2023. 1
2023
-
[5]
Stochastic self-guidance for training-free enhancement of diffusion models
Chubin Chen, Jiashu Zhu, Xiaokun Feng, Nisha Huang, Chen Zhu, Meiqi Wu, Fangyuan Mao, Jiahong Wu, Xiangxiang Chu, and Xiu Li. Stochastic self-guidance for training-free enhancement of diffusion models. InICLR, 2026. 2
2026
-
[6]
Wavegrad: Estimating gradients for waveform generation
Nanxin Chen, Yu Zhang, Heiga Zen, Ron J Weiss, Moham- mad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. InICLR, 2021. 1
2021
-
[7]
Ruidong Chen, Yancheng Bai, Xuanpu Zhang, Jianhao Zeng, Lanjun Wang, Dan Song, Lei Sun, Xiangxiang Chu, and Anan Liu. Layer-wise instance binding for regional and occlusion control in text-to-image diffusion transformers.arXiv preprint arXiv:2603.05769, 2026. 2
-
[8]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A downsampled variant of ImageNet as an alternative to the CIFAR datasets.arXiv preprint arXiv:1707.08819, 2017. 6
work page Pith review arXiv 2017
-
[9]
Usp: Unified self-supervised pretraining for image generation and under- standing
Xiangxiang Chu, Renda Li, and Yong Wang. Usp: Unified self-supervised pretraining for image generation and under- standing. InICCV, 2025. 2
2025
-
[10]
DiffEdit: Diffusion-based semantic image editing with mask guidance
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. DiffEdit: Diffusion-based semantic image editing with mask guidance. InICLR, 2023. 2
2023
-
[11]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. InNeurIPS, 2021. 1, 2, 3, 6
2021
-
[12]
Genie: Higher-order denoising diffusion solvers
Tim Dockhorn, Arash Vahdat, and Karsten Kreis. Genie: Higher-order denoising diffusion solvers. InNeurIPS, 2022. 2
2022
-
[13]
Generative adversarial nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InNeurIPS,
-
[14]
An introduction to wavelets.IEEE Computa- tional Science and Engineering, 1995
Amara Graps. An introduction to wavelets.IEEE Computa- tional Science and Engineering, 1995. 5, 6
1995
-
[15]
Haodong He, Xin Zhan, Yancheng Bai, Rui Lan, Lei Sun, and Xiangxiang Chu. Texts-diff: Texts-aware diffusion model for real-world text image super-resolution.arXiv preprint arXiv:2601.17340, 2026. 2
-
[16]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, 2017. 6, 5
2017
-
[17]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 1, 2, 6
2020
-
[18]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InNeurIPS, 2022. 2, 4, 6, 7
2022
-
[19]
Text2video-zero: Text- to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text- to-image diffusion models are zero-shot video generators. In ICCV, 2023. 1
2023
-
[20]
Refining generative process with discrim- inator guidance in score-based diffusion models
Dongjun Kim, Yeongmin Kim, Se Jung Kwon, Wanmo Kang, and Il-Chul Moon. Refining generative process with discrim- inator guidance in score-based diffusion models. InICML,
-
[21]
DiffWave: A versatile diffusion model for audio synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. DiffWave: A versatile diffusion model for audio synthesis. InICLR, 2021. 1
2021
-
[22]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 3, 6
2009
-
[23]
Rui Lan, Yancheng Bai, Xu Duan, Mingxing Li, Dongyang Jin, Ryan Xu, Lei Sun, and Xiangxiang Chu. Flux-text: A simple and advanced diffusion transformer baseline for scene text editing.arXiv preprint arXiv:2505.03329, 2025. 2
-
[24]
There is no V AE: End- to-end pixel-space generative modeling via self-supervised pre-training
Jiachen Lei, Keli Liu, Julius Berner, Y HoiM, Hongkai Zheng, Jiahong Wu, and Xiangxiang Chu. There is no V AE: End- to-end pixel-space generative modeling via self-supervised pre-training. InICLR, 2026. 2
2026
-
[25]
Srdiff: Single image super-resolution with diffusion probabilistic models
Haoying Li, Yifan Yang, Meng Chang, Shiqi Chen, Huajun Feng, Zhihai Xu, Qi Li, and Yueting Chen. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing, 2022. 2
2022
-
[26]
Alleviating exposure bias in diffusion mod- els through sampling with shifted time steps
Mingxiao Li, Tingyu Qu, Ruicong Yao, Wei Sun, and Marie- Francine Moens. Alleviating exposure bias in diffusion mod- els through sampling with shifted time steps. InICLR, 2024. 2, 4, 3
2024
-
[27]
On error propaga- tion of diffusion models
Yangming Li and Mihaela van der Schaar. On error propaga- tion of diffusion models. InICLR, 2024. 2
2024
-
[28]
Instaflow: One step is enough for high-quality diffusion-based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. InICLR, 2023. 2
2023
-
[29]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InICCV, 2015. 6
2015
-
[30]
Simplifying, stabilizing and scaling continuous-time consistency models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models. InICLR, 2025. 2
2025
-
[31]
DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InNeurIPS,
-
[32]
Eric Luhman and Troy Luhman. Knowledge distillation in it- erative generative models for improved sampling speed.arXiv preprint arXiv:2101.02388, 2021. 2
-
[33]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. InICLR, 2022. 2
2022
-
[34]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InCVPR, 2023. 2
2023
-
[35]
Shining yourself: High-fidelity ornaments virtual try-on with diffusion model
Yingmao Miao, Zhanpeng Huang, Rui Han, Zibin Wang, Chenhao Lin, and Chao Shen. Shining yourself: High-fidelity ornaments virtual try-on with diffusion model. InCVPR,
-
[36]
Analysing the spectral biases in generative models
Amitoj Singh Miglani, Shweta Singh, and Vidit Aggarwal. Analysing the spectral biases in generative models. InThe Fourth Blogpost Track at ICLR 2025, 2025. 4
2025
-
[37]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InICLR, 2021. 6
2021
-
[38]
Input perturbation reduces exposure bias in diffusion models
Mang Ning, Enver Sangineto, Angelo Porrello, Simone Calderara, and Rita Cucchiara. Input perturbation reduces exposure bias in diffusion models. InICML, 2023. 1, 2, 6
2023
-
[39]
Elucidating the exposure bias in diffusion models
Mang Ning, Mingxiao Li, Jianlin Su, Albert Ali Salah, and Itir Onal Ertugrul. Elucidating the exposure bias in diffusion models. InICLR, 2024. 2, 4, 6, 7, 3, 5
2024
-
[40]
Zero-shot image-to-image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to-image translation. InACM SIGGRAPH, 2023. 2
2023
-
[41]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InCVPR, 2023. 6, 7, 5
2023
-
[42]
Boosting diffusion models with moving average sampling in frequency domain
Yurui Qian, Qi Cai, Yingwei Pan, Yehao Li, Ting Yao, Qibin Sun, and Tao Mei. Boosting diffusion models with moving average sampling in frequency domain. InCVPR, 2024. 2
2024
-
[43]
From scale to speed: Adaptive test-time scaling for image editing.arXiv preprint arXiv:2603.00141,
Xiangyan Qu, Zhenlong Yuan, Jing Tang, Rui Chen, Datao Tang, Meng Yu, Lei Sun, Yancheng Bai, Xiangxiang Chu, Gaopeng Gou, et al. From scale to speed: Adaptive test-time scaling for image editing.arXiv preprint arXiv:2603.00141,
-
[44]
Multi-step denoising scheduled sampling: Towards alleviating exposure bias for diffusion models
Zhiyao Ren, Yibing Zhan, Liang Ding, Gaoang Wang, Chaoyue Wang, Zhongyi Fan, and Dacheng Tao. Multi-step denoising scheduled sampling: Towards alleviating exposure bias for diffusion models. InAAAI, 2024. 2
2024
-
[45]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 1, 2
2022
-
[46]
Image super- resolution via iterative refinement.TPAMI, 2022
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement.TPAMI, 2022. 2
2022
-
[47]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InICLR, 2022. 2
2022
-
[48]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015. 1, 2
2015
-
[49]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InICLR, 2021. 6
2021
-
[50]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. InICLR, 2024. 2
2024
-
[51]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021. 1
2021
-
[52]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, 2023. 2
2023
-
[53]
Self-guided generation of minority samples using diffusion models
Soobin Um and Jong Chul Ye. Self-guided generation of minority samples using diffusion models. InECCV, 2024. 6
2024
-
[54]
Don’t play favorites: Minority guidance for diffusion models
Soobin Um, Suhyeon Lee, and Jong Chul Ye. Don’t play favorites: Minority guidance for diffusion models. InICLR,
-
[55]
Score-based generative modeling in latent space
Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. InNeurIPS, 2021. 5, 7
2021
-
[56]
From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
JiYuan Wang, Chunyu Lin, Lei Sun, Rongying Liu, Lang Nie, Mingxing Li, Kang Liao, Xiangxiang Chu, and Yao Zhao. From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025. 2
-
[57]
Improved diffusion-based generative model with better adversarial robustness
Zekun Wang, Mingyang Yi, Shuchen Xue, Zhenguo Li, Ming Liu, Bing Qin, and Zhi-Ming Ma. Improved diffusion-based generative model with better adversarial robustness. InICLR,
-
[58]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
2025
-
[59]
PFGM++: Unlocking the potential of physics-inspired generative models
Yilun Xu, Ziming Liu, Yonglong Tian, Shangyuan Tong, Max Tegmark, and Tommi Jaakkola. PFGM++: Unlocking the potential of physics-inspired generative models. InICML,
-
[60]
Manifold constraint reduces exposure bias in accelerated diffusion sampling
Yuzhe Y AO, Jun Chen, Zeyi Huang, Haonan Lin, Mengmeng Wang, Guang Dai, and Jingdong Wang. Manifold constraint reduces exposure bias in accelerated diffusion sampling. In ICLR, 2025. 2
2025
-
[61]
Towards understanding the working mechanism of text-to-image diffu- sion model
Mingyang Yi, Aoxue Li, Yi Xin, and Zhenguo Li. Towards understanding the working mechanism of text-to-image diffu- sion model. InNeurIPS, 2024. 2, 5
2024
-
[62]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365, 2015. 6
work page internal anchor Pith review arXiv 2015
-
[63]
Bias mitigation in graph diffusion models
Meng Yu and Kun Zhan. Bias mitigation in graph diffusion models. InICLR, 2025. 2
2025
-
[64]
Frequency regulation for exposure bias mitigation in diffusion models
Meng Yu and Kun Zhan. Frequency regulation for exposure bias mitigation in diffusion models. InACM MM, 2025. 2, 4, 6, 7, 3
2025
-
[65]
Looka- head diffusion probabilistic models for refining mean estima- tion
Guoqiang Zhang, Kenta Niwa, and W Bastiaan Kleijn. Looka- head diffusion probabilistic models for refining mean estima- tion. InCVPR, 2023. 4, 5, 3
2023
-
[66]
Anti-exposure bias in diffusion models
Junyu Zhang, Daochang Liu, Eunbyung Park, Shichao Zhang, and Chang Xu. Anti-exposure bias in diffusion models. In ICLR, 2025. 2, 6
2025
-
[67]
Unipc: A unified predictor-corrector framework for fast sampling of diffusion models
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. InNeurIPS, 2024. 2
2024
-
[68]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[69]
A woman is walking on the beach by the sea
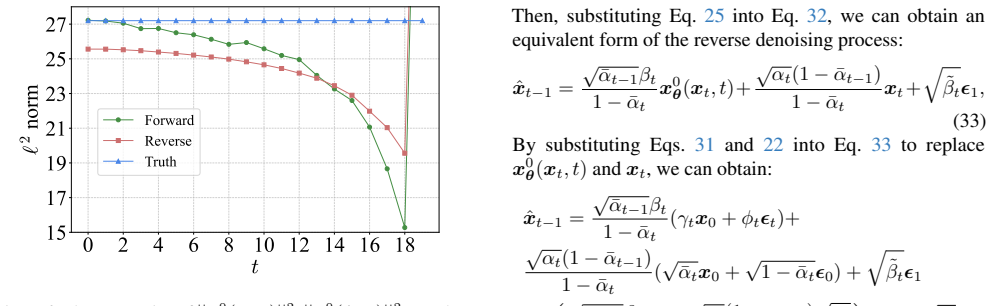
Zhenyu Zhou, Defang Chen, Can Wang, and Chun Chen. Fast ODE-based sampling for diffusion models in around 5 steps. InCVPR, 2024. 2 Elucidating the SNR-t Bias of Diffusion Probabilistic Models Supplementary Material A. Difference from Prior Works In this section, we outline the differences between the second experiment (Fig. 1c) in Sec 4 of this paper and ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.