Recognition: unknown
DenTab: A Dataset for Table Recognition and Visual QA on Real-World Dental Estimates
Pith reviewed 2026-05-10 08:30 UTC · model grok-4.3
The pith
Dental estimate tables reveal that vision-language models recover structure accurately but still fail at multi-step arithmetic and consistency reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DenTab demonstrates that on noisy administrative tables from dental estimates, current vision-language models and OCR systems achieve strong structure recovery yet exhibit persistent errors on multi-step arithmetic and consistency checks, and these errors continue even when provided with perfect ground-truth table representations in HTML.
What carries the argument
The DenTab dataset of cropped table images with HTML annotations and 2,208 questions in eleven categories, used to benchmark table recognition and visual QA.
If this is right
- Improving table structure recognition alone is insufficient for reliable TableVQA on real-world noisy tables.
- Arithmetic and logic reasoning capabilities in VLMs need targeted improvements beyond visual input processing.
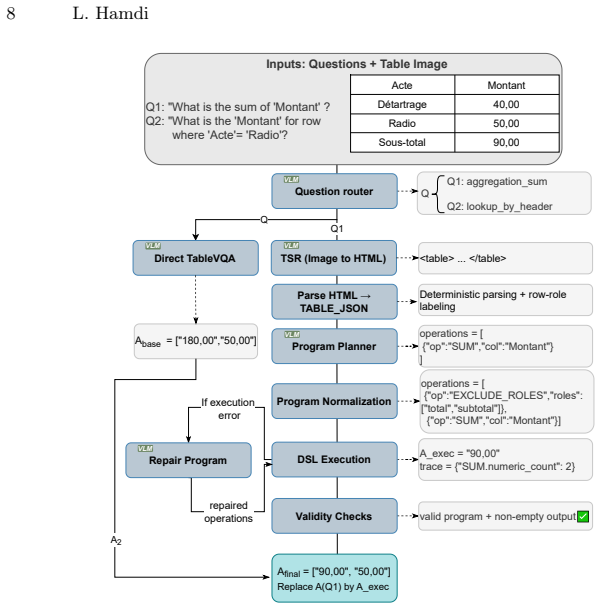
- The Table Router Pipeline shows that combining VLMs with rule-based execution can enhance performance on calculation tasks without additional training.
- Real-world administrative tables like dental estimates provide a more challenging testbed than synthetic or clean datasets for evaluating table understanding systems.
Where Pith is reading between the lines
- Similar reasoning gaps may exist in other domains involving financial or medical administrative documents.
- Future datasets could focus more on consistency checks and multi-step logic to better expose model limitations.
- Integrating symbolic computation modules with VLMs could be a general strategy for improving reliability on quantitative table tasks.
- Testing the pipeline on other table domains would confirm if the approach generalizes beyond dental estimates.
Load-bearing premise
That dental estimates are representative of real-world administrative tables and that the eleven question categories cover the key reasoning failures.
What would settle it
Observing whether the same structure-reasoning discrepancy appears when testing the same models on a different collection of noisy administrative tables from another domain.
Figures






read the original abstract
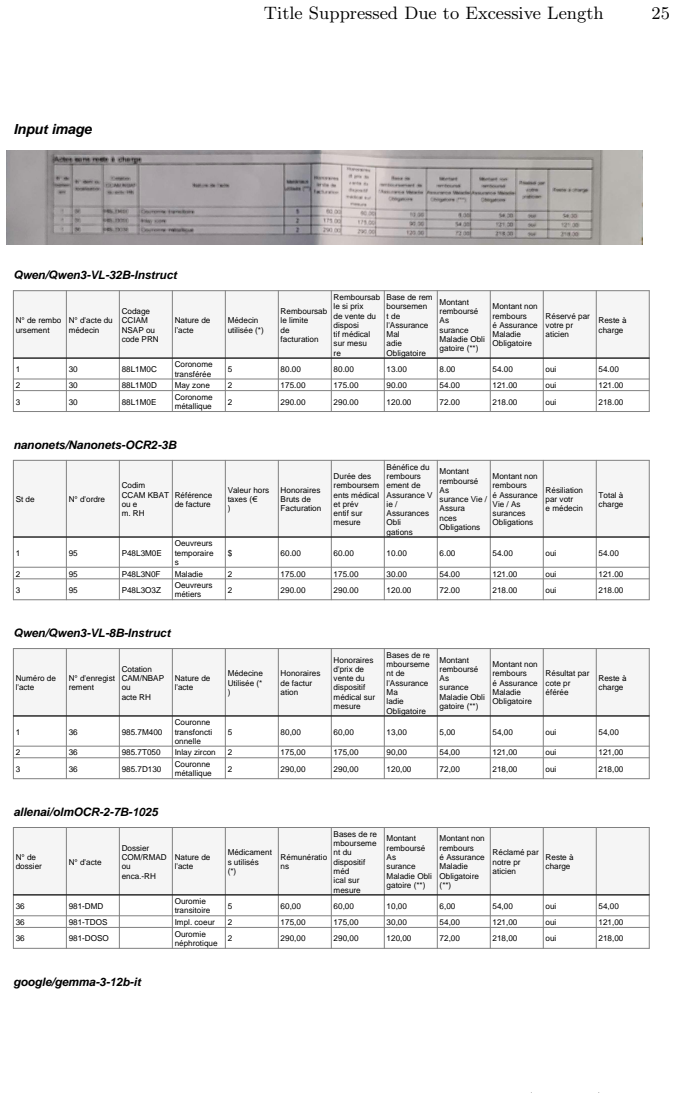
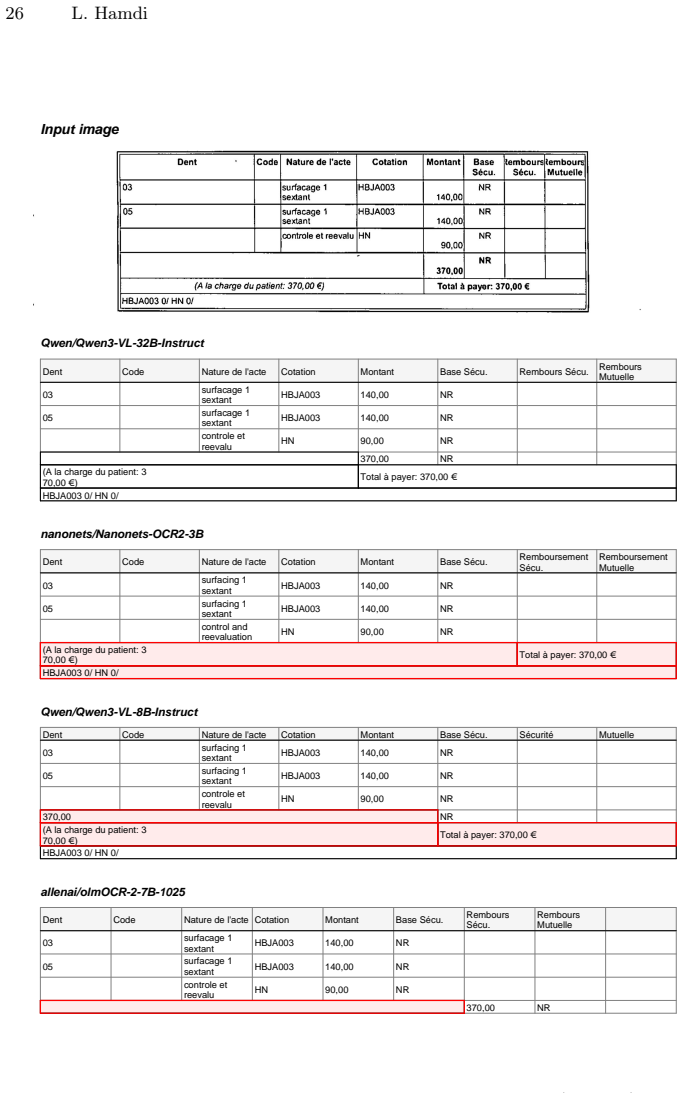
Tables condense key transactional and administrative information into compact layouts, but practical extraction requires more than text recognition: systems must also recover structure (rows, columns, merged cells, headers) and interpret roles such as line items, subtotals, and totals under common capture artifacts. Many existing resources for table structure recognition and TableVQA are built from clean digital-born sources or rendered tables, and therefore only partially reflect noisy administrative conditions. We introduce DenTab, a dataset of 2{,}000 cropped table images from dental estimates with high-quality HTML annotations, enabling evaluation of table recognition (TR) and table visual question answering (TableVQA) on the same inputs. DenTab includes 2{,}208 questions across eleven categories spanning retrieval, aggregation, and logic/consistency checks. We benchmark 16 systems, including 14 vision--language models (VLMs) and two OCR baselines. Across models, strong structure recovery does not consistently translate into reliable performance on multi-step arithmetic and consistency questions, and these reasoning failures persist even when using ground-truth HTML table inputs. To improve arithmetic reliability without training, we propose the Table Router Pipeline, which routes arithmetic questions to deterministic execution. The pipeline combines (i) a VLM that produces a baseline answer, a structured table representation, and a constrained table program with (ii) a rule-based executor that performs exact computation over the parsed table. The source code and dataset will be made publicly available at https://github.com/hamdilaziz/DenTab.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DenTab, a dataset of 2,000 cropped real-world dental estimate table images with high-quality HTML annotations for table structure recognition and TableVQA. It benchmarks 16 systems (14 VLMs and 2 OCR baselines) on 2,208 questions across 11 categories covering retrieval, aggregation, and logic/consistency. The central observation is that strong structure recovery does not reliably translate to good performance on multi-step arithmetic and consistency questions, with these failures persisting even when ground-truth HTML table inputs are provided to the models. The authors also propose the Table Router Pipeline, which routes arithmetic questions to a VLM for structured representation plus a rule-based executor for exact computation, and commit to releasing the dataset and code.
Significance. If the empirical observations hold under detailed scrutiny, the work provides a useful new resource for evaluating table understanding under realistic administrative capture conditions and highlights a persistent gap between structure recovery and multi-step reasoning in current VLMs. The public release of data and code, together with the practical Table Router Pipeline that avoids additional training, are clear strengths that could support follow-on research on hybrid VLM-plus-executor systems for table tasks.
major comments (2)
- [Experimental evaluation of VQA with ground-truth HTML] The central claim that reasoning failures on arithmetic and consistency questions persist even with ground-truth HTML inputs (stated in the abstract and evaluated in the experimental section) is load-bearing but rests on an unspecified prompting strategy for supplying the HTML to the VLMs. Because the models are vision-language systems, their ability to perform exact arithmetic over serialized HTML depends on prompt wording, serialization format, few-shot examples, and any constraints provided; without these details it is impossible to distinguish intrinsic reasoning deficits from input-processing limitations.
- [Table Router Pipeline and results] The paper reports benchmark results and proposes the Table Router Pipeline to improve arithmetic reliability, yet provides no quantitative metrics, error bars, statistical significance tests, or ablation numbers comparing the pipeline against the 14 VLMs and 2 OCR baselines on the arithmetic and consistency question subsets. This absence makes it difficult to assess the magnitude or reliability of the claimed improvement.
minor comments (2)
- [Dataset construction] The eleven question categories are described at a high level; a table or appendix listing example questions per category with their expected reasoning type would improve reproducibility and allow readers to judge coverage of practical failure modes.
- [Conclusion] The manuscript states that source code and dataset will be released at a GitHub URL but does not include a data statement or license details in the current version; adding these would strengthen the reproducibility claim.
Circularity Check
No circularity: purely empirical dataset introduction and benchmarking
full rationale
The paper introduces a new dataset (DenTab) of real-world dental estimate tables with HTML annotations and evaluates 16 external systems (VLMs and OCR baselines) on table recognition and TableVQA tasks. The central claim—that strong structure recovery does not reliably yield good multi-step arithmetic/consistency performance, even with ground-truth HTML—is supported solely by reported benchmark metrics on held-out questions. The proposed Table Router Pipeline is a practical engineering combination of a VLM plus a deterministic executor, not a derived result. No equations, fitted parameters, self-citations, or ansatzes appear in the provided text; all claims rest on external model performance against the new data. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Better patching using llm prompting, via self-consistency
Toufique Ahmed and Premkumar Devanbu. Better patching using llm prompting, via self-consistency. InIEEE/ACM, 2023
2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv:2308.12966, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Shuai Bai et al. Qwen2.5-vl technical report.arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen et al. Tabfact: A large-scale dataset for table-based fact verification. InICLR, 2020
2020
-
[5]
Wenhu Chen et al. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv:2211.12588, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024
2024
-
[7]
Hitab: A hierarchical table dataset for question answering and natural language generation
Zhoujun Cheng et al. Hitab: A hierarchical table dataset for question answering and natural language generation. InACL, pages 1094–1110, 2022
2022
-
[8]
Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; and Liu, Y
Zewen Chi et al. Complicated table structure recognition.arXiv:1908.04729, 2019
-
[9]
Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
Hao Feng et al. Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv:2505.14059, 2025
-
[10]
Icdar 2019 competition on table detection and recognition (ctdar)
Liangcai Gao et al. Icdar 2019 competition on table detection and recognition (ctdar). InICDAR, pages 1510–1515, 2019
2019
-
[11]
Pal: Program-aided language models
Luyu Gao et al. Pal: Program-aided language models. InICML, pages 10764– 10799, 2023
2023
-
[12]
Gemma Team et al. Gemma 3 technical report.arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InCVPR, pages 14953–14962, 2023
2023
-
[14]
Ocr-free document understanding transformer
Geewook Kim et al. Ocr-free document understanding transformer. InECCV, 2022
2022
-
[15]
Tablevqa-bench: A visual question answering benchmark on multiple table domains, 2024
YoonsikKim,MoonbinYim,andKaYeonSong. Tablevqa-bench:Avisualquestion answering benchmark on multiple table domains.arXiv:2404.19205, 2024
-
[16]
Building and better understanding vision-language models: insights and future directions
Hugo Laurençon et al. Building and better understanding vision-language models: insights and future directions.arXiv:2408.12637, 2024
-
[17]
Tablebank: Table benchmark for image-based table detection and recognition
Minghao Li et al. Tablebank: Table benchmark for image-based table detection and recognition. InLREC, pages 1918–1925, 2020
1918
-
[18]
Deplot: One-shot visual language reasoning by plot-to-table translation
Fangyu Liu et al. Deplot: One-shot visual language reasoning by plot-to-table translation. InFindings of ACL, 2023. Title Suppressed Due to Excessive Length 15
2023
-
[19]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023
2023
-
[20]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InW ACV, pages 2200–2209, 2021
2021
-
[21]
Mistral 3: Open-weight language model release, 2025
Mistral AI. Mistral 3: Open-weight language model release, 2025
2025
-
[22]
Nanonets-ocr-s: Image-to-markdown ocr model, 2025.https:// huggingface.co/nanonets/Nanonets-OCR-s
Nanonets. Nanonets-ocr-s: Image-to-markdown ocr model, 2025.https:// huggingface.co/nanonets/Nanonets-OCR-s
2025
-
[23]
Nanonets-ocr2-3b: Document to structured markdown, 2025.https: //huggingface.co/nanonets/Nanonets-OCR2-3B
Nanonets. Nanonets-ocr2-3b: Document to structured markdown, 2025.https: //huggingface.co/nanonets/Nanonets-OCR2-3B
2025
-
[24]
Shubham Paliwal, Dheeraj Sharma, and Lovekesh Vig. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images.arXiv:2001.01469, 2020
-
[25]
Compositional semantic parsing on semi- structured tables
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi- structured tables. InACL, 2015
2015
-
[26]
J.Poznanskietal. olmocr:Unlockingtrillionsoftokensinpdfswithvisionlanguage models.arXiv:2502.18443, 2025
-
[27]
Devashish Prasad et al. Cascadetabnet: An approach for end to end table detection and structure recognition from image-based documents.arXiv:2004.12629, 2020
-
[28]
Toolformer: Language models can teach themselves to use tools
Timo Schick et al. Toolformer: Language models can teach themselves to use tools. InNeurIPS, volume 36, pages 68539–68551, 2023
2023
-
[29]
Deepdesrt: Deep learning for detection and structure recognition of tables in document images
Sebastian Schreiber et al. Deepdesrt: Deep learning for detection and structure recognition of tables in document images. InICDAR, 2017
2017
-
[30]
Wikidt: Visual-based table recognition and question answering dataset
Hui Shi et al. Wikidt: Visual-based table recognition and question answering dataset. InICDAR, pages 406–437, 2024
2024
- [31]
-
[32]
Pubtables-1m: Towards comprehensive table extraction from unstructured documents
Brandon Smock, Rohith Pesala, and Robin Abraham. Pubtables-1m: Towards comprehensive table extraction from unstructured documents. InCVPR, 2022
2022
-
[33]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. InICCV, pages 11888–11898, 2023
2023
-
[34]
General ocr theory: Towards ocr-2.0 via a unified end-to-end model
Haoran Wei et al. General ocr theory: Towards ocr-2.0 via a unified end-to-end model. InCVPR, 2024
2024
-
[35]
Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 35:24824–24837, 2022
Jason Wei et al. Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 35:24824–24837, 2022
2022
-
[36]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu et al. Deepseek-vl2: Mixture-of-experts vision-language models for ad- vanced multimodal understanding.arXiv:2412.10302, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
A. Yang et al. Qwen3 technical report.arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang et al. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv:2303.11381, 2023
work page internal anchor Pith review arXiv 2023
-
[39]
React: Synergizing reasoning and acting in language models
Shunyu Yao et al. React: Synergizing reasoning and acting in language models. In ICLR, 2023
2023
-
[40]
arXiv preprint arXiv:2406.08100 , year =
Mingyu Zheng et al. Multimodal table understanding.arXiv:2406.08100, 2024
-
[41]
Global table extractor (gte): A framework for joint table iden- tification and cell structure recognition using visual context
Xinyi Zheng et al. Global table extractor (gte): A framework for joint table iden- tification and cell structure recognition using visual context. InW ACV, 2021
2021
-
[42]
Image-based table recognition: data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-based table recognition: data, model, and evaluation. InECCV, 2020
2020
-
[43]
answers": [
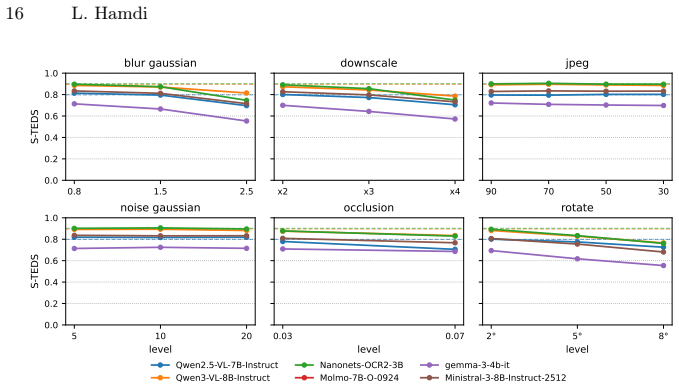
Feng Zhu et al. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance. InACL, 2021. 16 L. Hamdi 0.8 1.5 2.5 0.0 0.2 0.4 0.6 0.8 1.0S-TEDS blur gaussian x2 x3 x4 downscale 90 70 50 30 jpeg 5 10 20 level 0.0 0.2 0.4 0.6 0.8 1.0S-TEDS noise gaussian 0.03 0.07 level occlusion 2° 5° 8° level rotate Qwen2.5-VL-7B-Instruct ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.